

PDF content extraction method, device and equipment
An extraction method and content technology, applied in the field of PDF content extraction and computer-readable storage media, can solve the problems of reducing content identification and content extraction efficiency, poor efficiency, interference, etc., to improve identification and extraction efficiency, improve accuracy, The effect of reducing the size of an image
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach
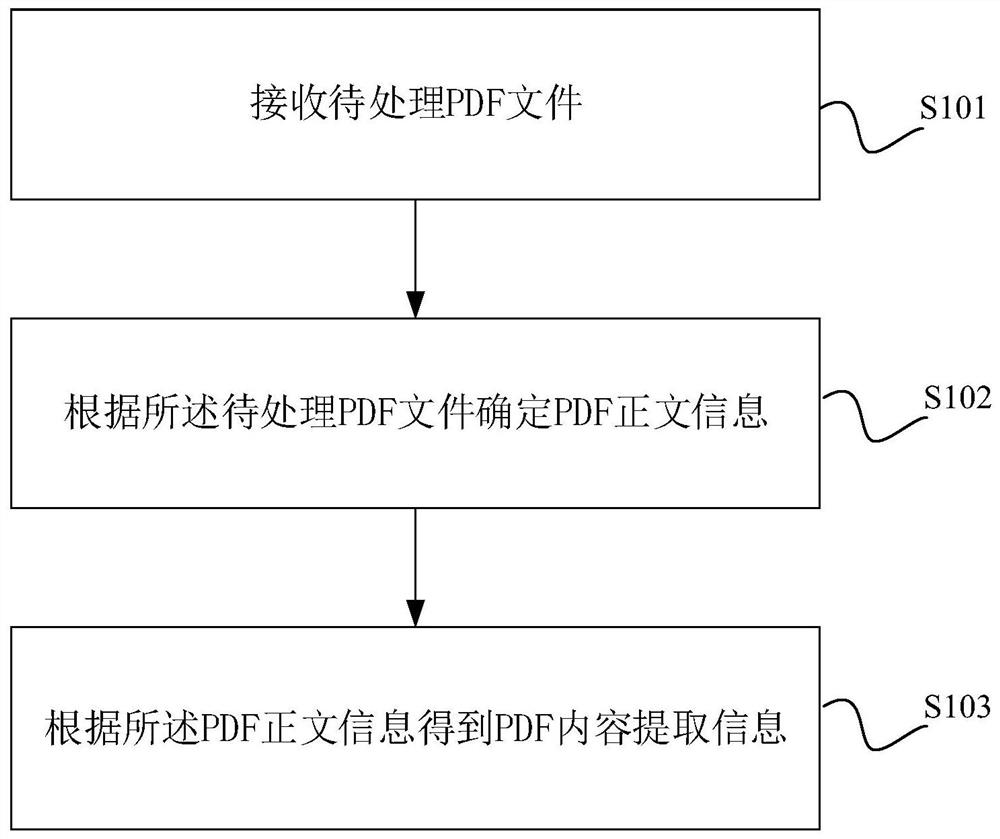
[0047] The core of the present invention is to provide a method for extracting PDF content, a schematic flow chart of a specific implementation is as follows figure 1 As shown, it is called the first specific implementation mode, including:
[0048] S101: Receive a PDF file to be processed.
[0049] S102: Determine PDF text information according to the PDF file to be processed.
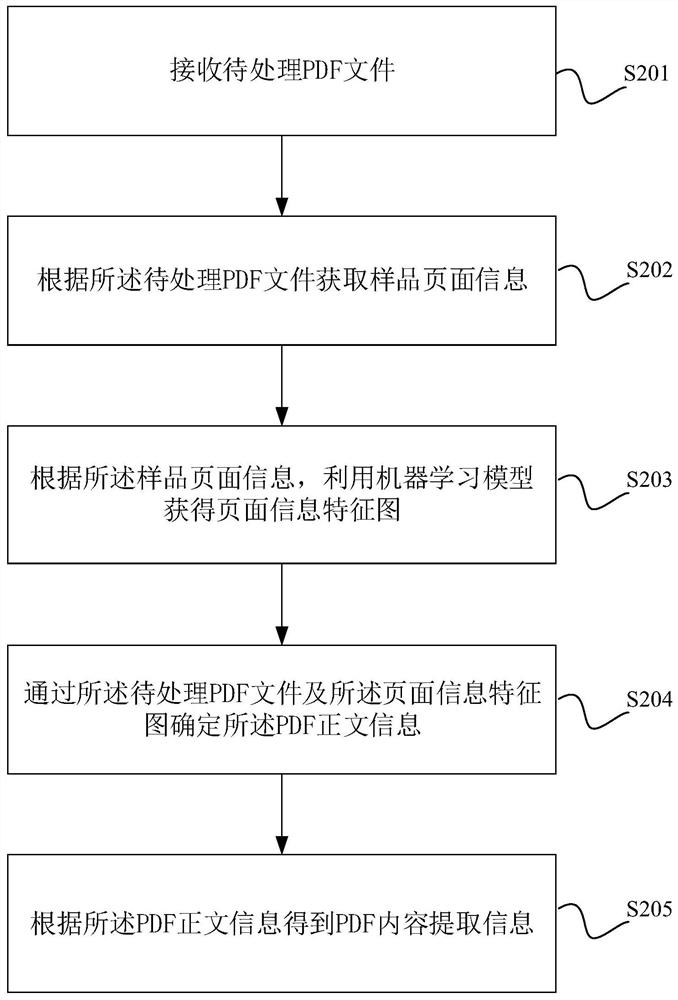
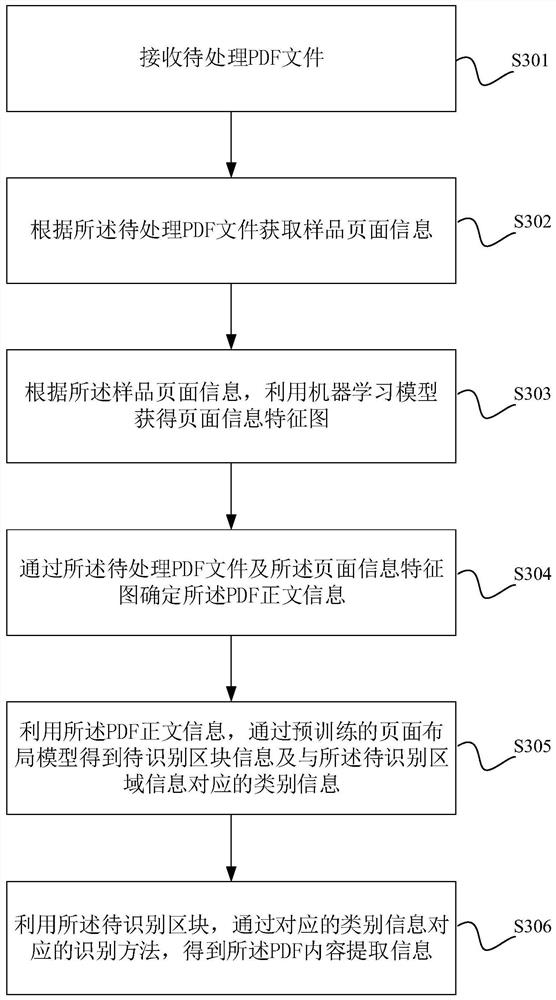
[0050] The above-mentioned determination of the PDF text information through the PDF file to be processed can be realized by a machine learning method, such as through LSTM structure or CNN neural network training, to realize the search for samples by learning several sample pages in the same PDF file The commonality between pages can automatically exclude information such as headers, footers, and page numbers, leaving only the text information of the PDF; or, it can also directly cut the PDF pages according to the preset rules, such as cutting the presets at the upper and lower ends of the PDF page....
Embodiment approach
[0077] In the process of model training, the data is unbalanced, and the focus of the current task is precisely those types with small amount of data, such as: tables, titles. In order for the model to better learn the characteristics of these regions, an impact factor is added to the loss function to increase the learning ability of these categories.
[0078] The loss function of this model is mainly divided into three parts: frame loss, classification loss, and confidence loss. The border loss of Yolov4 is the CIoU loss used, and this part does not need to be modified; the confidence loss does not need to be changed, because in terms of confidence, the higher the confidence, the better, and there is no difference between categories; the present invention What needs to be modified is the category loss caused by classification.
[0079] Modified category loss function:
[0080]
[0081] where is the impact factor of Φ(c) category, Is the cross-entropy loss b...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More