

Cross-modal time sequence behavior positioning method and device for multi-granularity cascade interaction network
A behavior positioning and multi-granularity technology, applied in the field of visual-language cross-modal learning, can solve the problems of not making full use of multi-granularity text query information, not fully modeling the timing dependence characteristics of video local contexts, etc., to improve accuracy, The effect of improving positioning accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0075] Specific embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. It should be understood that the specific embodiments described here are only used to illustrate and explain the present invention, and are not intended to limit the present invention.
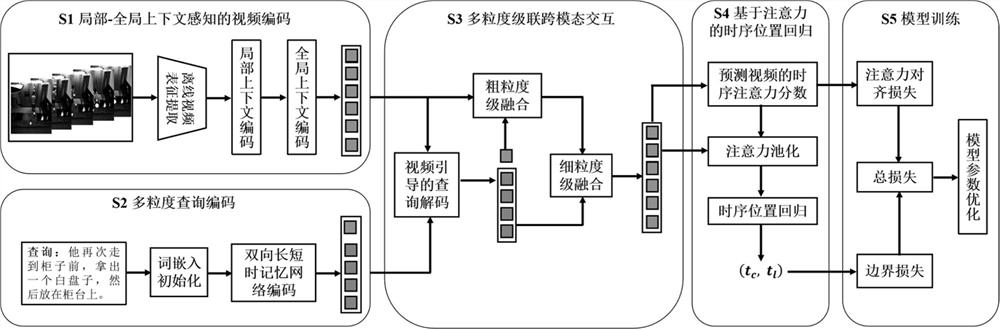
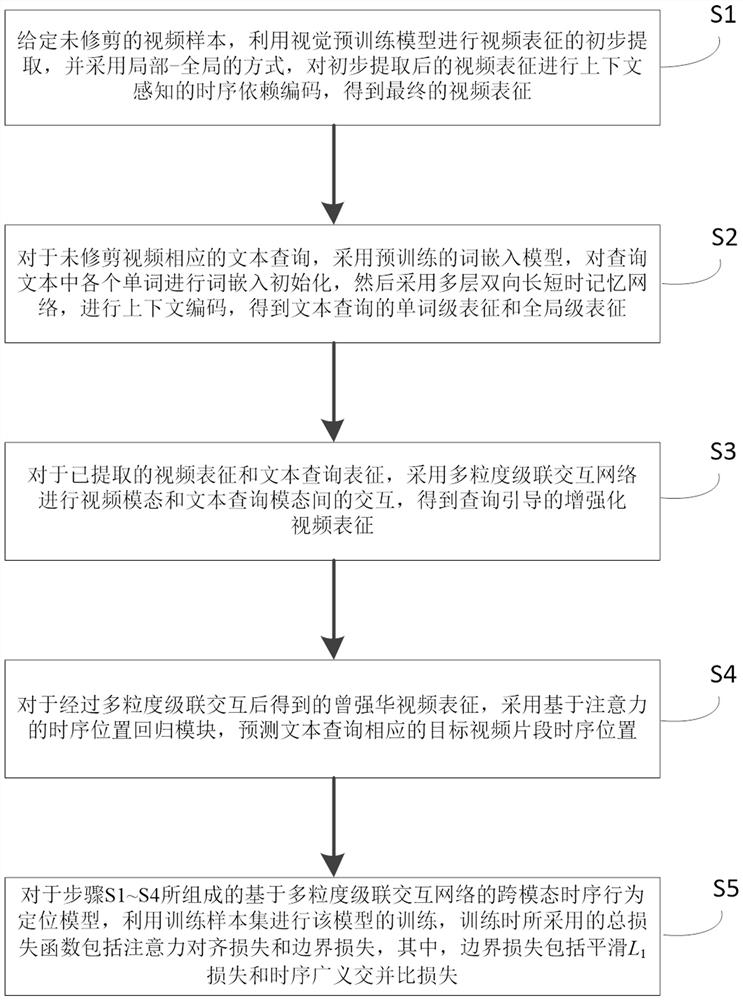
[0076] The invention discloses a multi-granularity cascaded interactive network cross-modal temporal behavior positioning method and device, based on the multi-granularity cascaded interactive network visual-language cross-modal temporal behavior positioning, which is used to solve untrimmed video based on given The timing behavior positioning problem of a given text query. This method proposes a simple and effective multi-granularity cascaded cross-modal interaction network to improve the cross-modal alignment ability of the model. In addition, the present invention introduces a local-global context-aware video encoder, which is used to improve the context timin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More