

Automobile radar point cloud data processing method
A technology for point cloud data and automotive radar, which is applied in the processing field of automotive radar point cloud data and can solve problems such as complex computing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
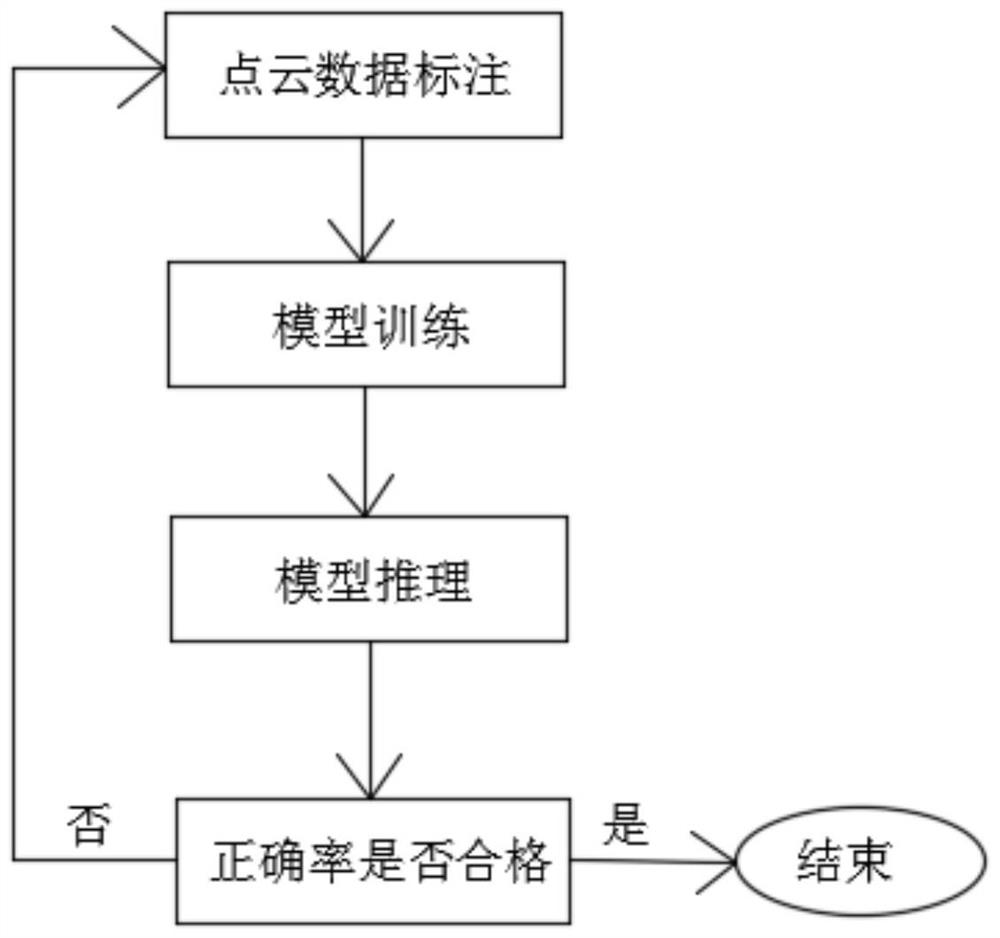
[0031] A method for processing automotive radar point cloud data, such as Figure 1-Figure 6 As shown, it includes steps: S1, mark the original point cloud data, select the corresponding number of axes according to different vehicle models, part of the marked point cloud data is used as training data, and the other part is used as test data; S2, use the training data of S1 For model training, first align the point cloud data and perform deep learning iterative training, then aggregate the extracted feature information, and at the same time perform deep learning iterative training to obtain a trained model; S3, use the test data of S1 and use S2 to train well The model of the model is used for model reasoning, and the predicted axle type output by the model is compared with the marked true value to obtain the correct rate; S4, if the correct rate is greater than the set target accuracy rate, it is passed; if the correct rate is less than or equal to the set target accuracy rate,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More