

Visual question and answer method based on module routing network model
A network model and routing technology, applied in biological neural network models, neural learning methods, character and pattern recognition, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0072] Embodiment one function and effect
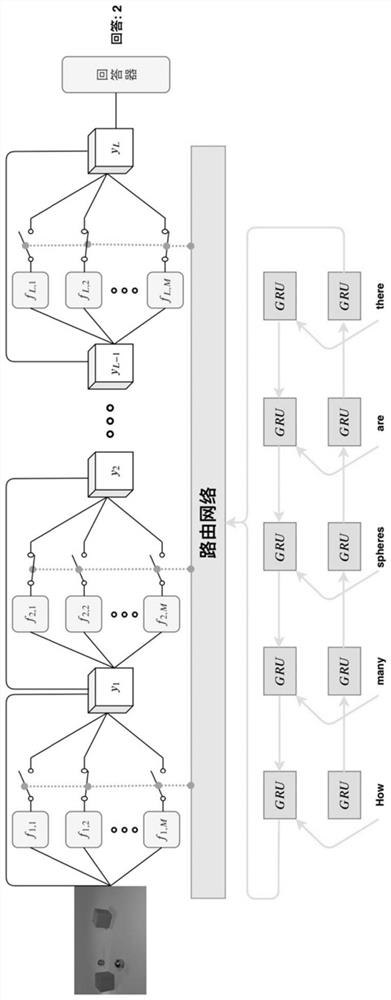
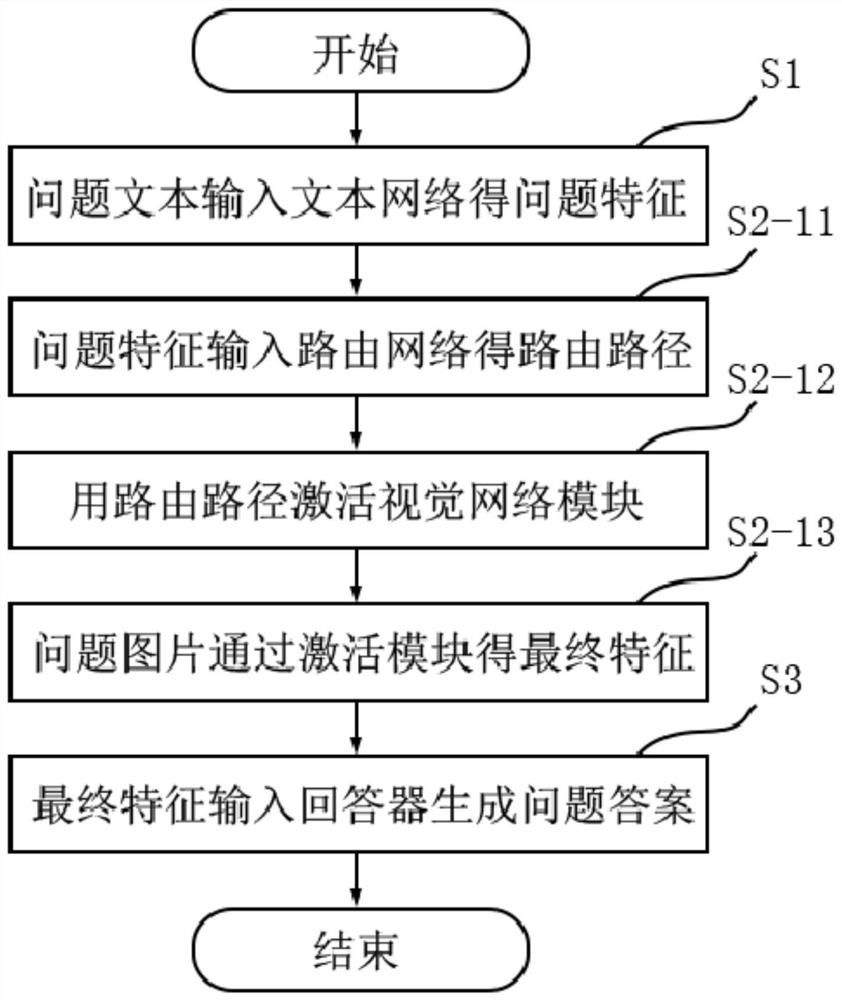
[0073] A visual question answering method based on the module routing network proposed by the present invention is to process the text of the natural language question through the text network to obtain the question features, and then process the picture and the routing path by the visual network to obtain the corresponding image features, and then the routing network corresponds to the The features in the text network and visual network are processed through the routing path generated based on the characteristics of the question, so as to obtain the final feature and extract the final answer from the predetermined answer of the answerer through the predetermined training model. Therefore, a visual question answering method based on a modular routing network provided by the present invention can fuse the two modalities of text and vision in multiple levels, so that the features of text and pictures can be fully analyzed and processed,...
Embodiment 2
[0092] Embodiment two function and effect
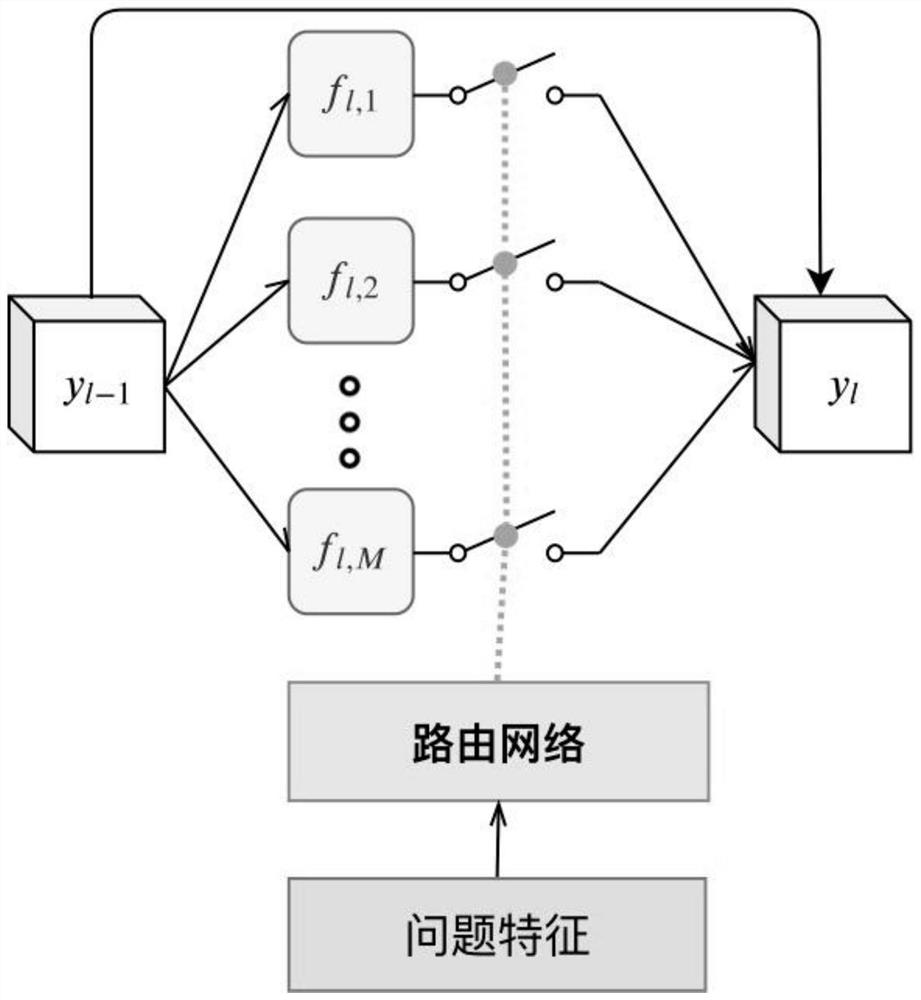
[0093] In the embodiment, the image features and question features of each module layer are processed by the routing network to obtain the routing path of the next layer, which can more accurately combine the image features and question features to obtain the final features that are more practical. The answer obtained by inputting the final features into the answerer will also be more effective in solving the problem.
[0094] The routing network aggregates the features processed by the activation module and the residual input as the image features output by each module layer. The image features of each layer can consider the residual input on the basis of the image features of the previous module layer, and can combine the effective content that may be lost in the previous step with the processed image features to avoid inconsistencies. Photo and answer to question text.
Embodiment 3
[0096] In the third embodiment, on the basis of the first embodiment, an attention module is added to the visual network, which is used to paste the image features and the problem features, and establish the pairwise positions or objects in the image features through the spatial self-attention mechanism. Contact to get the final feature.
[0097] The attention modules in the visual network include a first attention module and a second attention module.
[0098] The first attention module is used to paste image features and problem features, and then use the spatial self-attention mechanism to model the connection between two positions or objects in the feature map, and obtain the final feature with stronger expressive ability, spatial self-attention The force mechanism can be implemented in different ways, such as the encoder in Transformer.
[0099] The second attention module is used to weight and average the image features by the spatial attention mechanism to obtain a nor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More