Multi-agent reinforcement learning method for data unloading of Internet of Things
A technology of reinforcement learning and multi-agents, applied in the direction of reducing energy consumption, advanced technology, electrical components, etc., can solve problems such as slow learning speed, and achieve the effect of improving learning rate and performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment 1
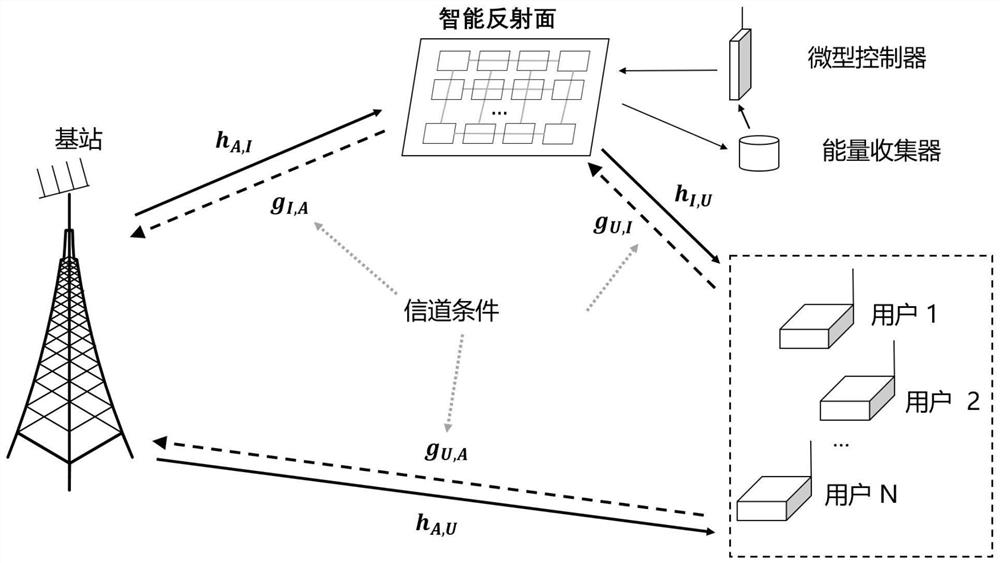
[0036] Aiming at the problem of continuous variable control in the dynamic environment of agents, the multi-agent deep deterministic policy gradient (MADDPG) method is used to solve it: assuming that there are n agents (agents), we design a corresponding action set a for each agent 1 ,...,a n , the corresponding observation quantity o 1 ,...,o n . The state transition equation includes all states, actions and observations: in Each agent's policy consists only of its own state and actions: μ i :o i →a i . Each agent uses a deep critic network to approximate the Q function, that is, the i-th agent's critic network learns the action value function: in The parameters of the critic network will be updated every decision epoch, thus outputting a better approximation of the Q value. This can be achieved by training a deep neural network (DNN) to minimize the loss function:
[0037]
[0038] in:
[0039]
[0040] represents the output of the target-critic netwo...
specific Embodiment 2
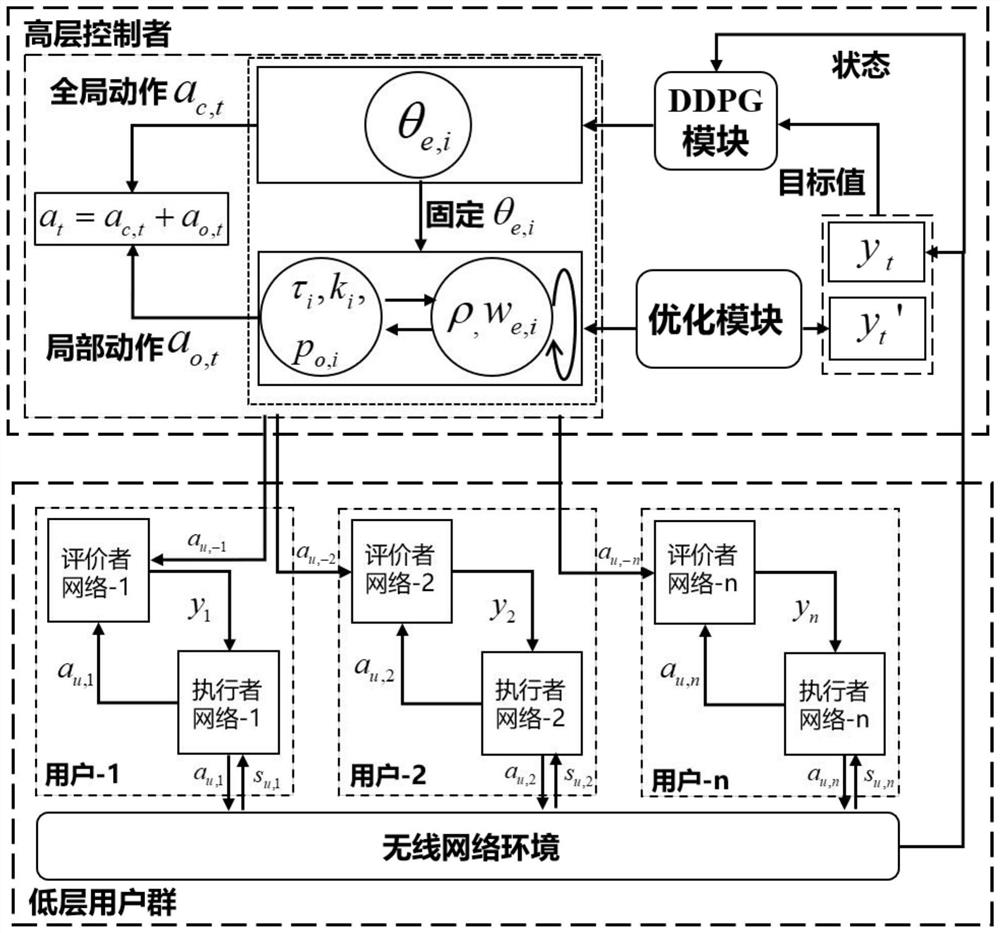
[0048] For the highly coupled multivariate learning complexity and target value estimation problem, an optimization-driven deep deterministic policy gradient (DDPG) method is designed:
[0049] Specifically, the action a t =(θ i ,ω i ,ρ i ,τ i ,k i ) into the global action a c,t = θ i with local action a o,t =(ω i ,ρ i ,τ i ,k i );
[0050] Define a deep deterministic policy gradient (DDPG) module and an optimization module, and the DDPG module generates a global action a c,t , the optimization module generates a local action a o,t .
[0051] At the beginning of the iteration, the DDPG module outputs the global action a c,t = θ i , and input the optimization model;
[0052] The optimization module first fixes the phase θ i , to solve the active beamforming strategy ω by solving the equivalent convex problem i , then fix the above parameters, perform inner layer iterations, and alternately solve the reflection coefficient ρ i and time slot division ratio τ ...
specific Embodiment 3
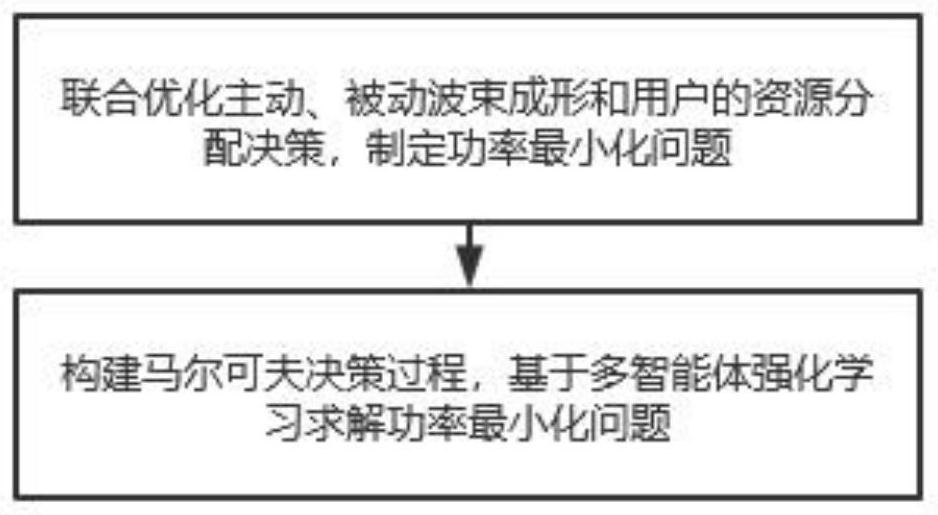
[0060] For the problem of multi-agent information fusion, in the MADDPG framework, each user generates an estimate of the target value y by the target-critic network, and generates estimates of other user strategies by the approximate policy network j≠i, in order to complete the information fusion of multi-agents. In the early stage of learning, due to the random initialization of the critic network and the approximate policy network, the estimation of y and the policy estimation far from the optimal value. This problem can be tackled with an optimization-driven hierarchical reinforcement learning approach. Estimate the lower bound of the target value y by solving approximate optimization problems and approximate strategies for other agents Specifically, system participants are divided into high-level controllers and low-level multi-user agents. The controller agent has a DDPG module and an optimization module. Through the optimization module in Example 2, the action est...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com