Large-scale high-dimensional data approximate neighbor query system and method based on Spark
A high-dimensional data and neighbor query technology, which is applied in other database retrieval, other database indexing, electrical digital data processing, etc., can solve the problem that the performance of throughput and delay cannot meet the actual needs, and does not consider non-spatial high-dimensional vectors requirements, inability to support non-spatial high-dimensional vector data and other issues, to achieve improved query throughput, wide applicability, and significant effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

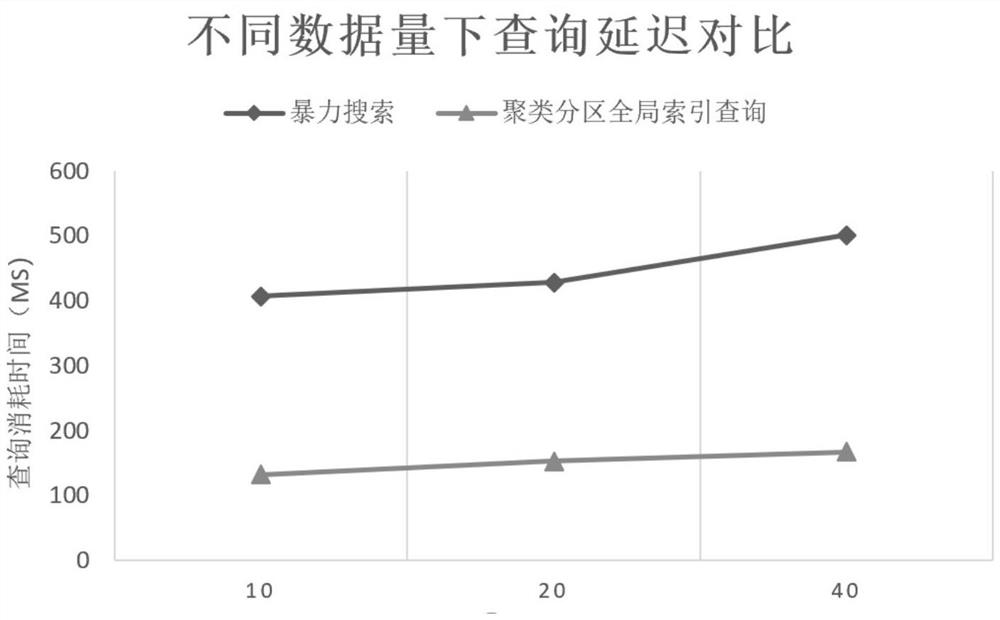


Examples
Embodiment Construction
[0069] The technical solutions in the embodiments of the present application will be clearly and completely described below in conjunction with the drawings in the embodiments of the present application. It should be understood by those skilled in the art that the described embodiments are some, but not all, embodiments of the present invention. Based on the embodiments in the present application, those skilled in the art can make any appropriate modification or variation to obtain all other embodiments.
[0070] In the first aspect, the embodiment of the present invention proposes a large-scale high-dimensional data approximate neighbor query system based on Spark, the system includes:
[0071] Vector acquisition module, index building module and query module.
[0072] The vector acquisition module is used to acquire the vectors to be processed by the system, that is, the data sets to be processed, including the vectors to be processed converted from the unstructured data to...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More