Image compression method based on discrete Gaussian mixture hyper-prior and Mask and medium
A technology of Gaussian mixing and image compression, which is applied in image communication, digital video signal modification, electrical components, etc., can solve problems such as limited capability and limited compression model performance, and achieve the goal of reducing space size, improving compression efficiency, and improving feature extraction effect of ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0040] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments. This embodiment is carried out on the premise of the technical solution of the present invention, and detailed implementation and specific operation process are given, but the protection scope of the present invention is not limited to the following embodiments.
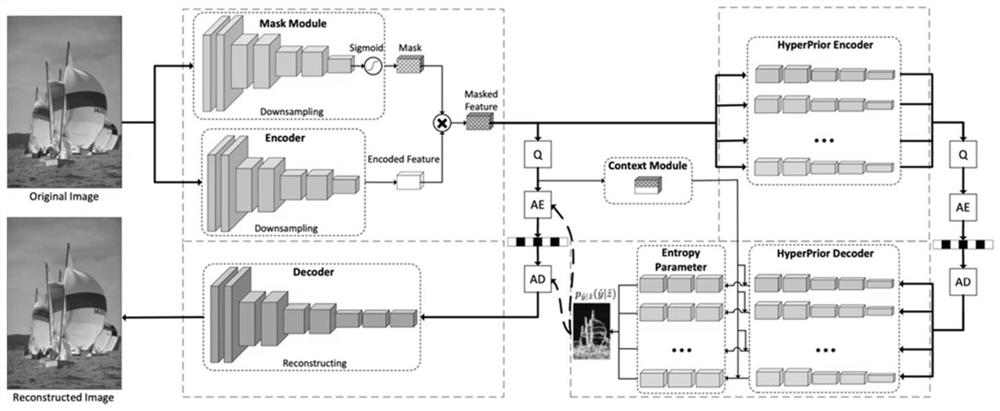
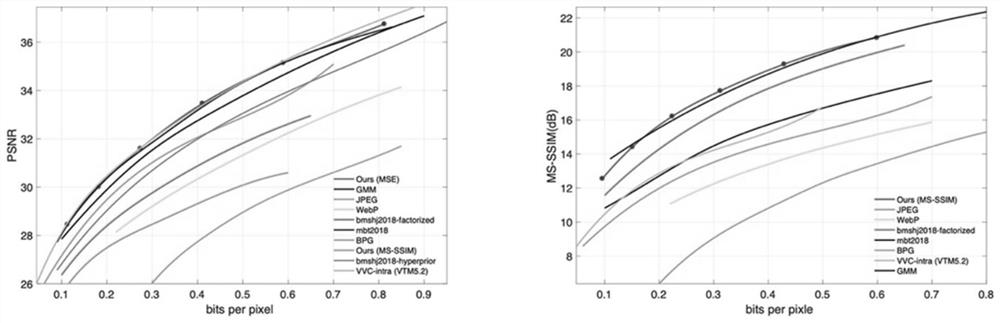
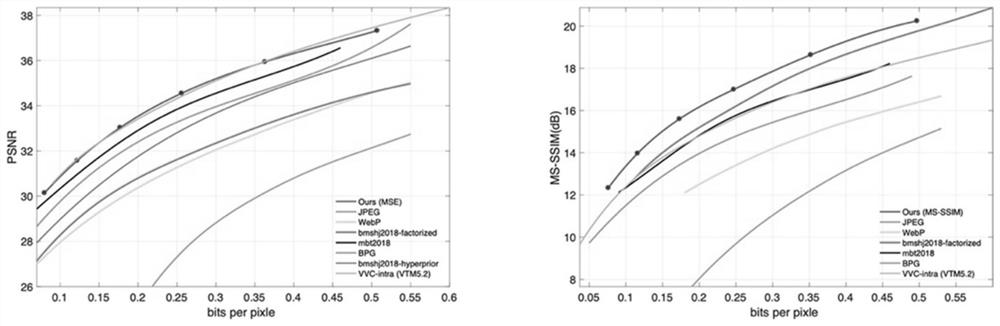
[0041] The present embodiment provides an image compression method based on discrete Gaussian mixture super prior and Mask, comprising the following steps: preprocessing the image to be compressed to obtain a preprocessed image; extracting the feature map of the preprocessed image, and simultaneously based on the Preprocess the spatial feature information of the image to generate a Mask value, and perform dot product processing on the feature map and the Mask value to obtain a hidden variable representation; use multiple Gaussian distributions to extract the distribution of hidden vari...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com