

Concrete crack detection method based on ConcreteCrackSegNet model
A detection method, concrete technology, applied in the direction of neural learning method, biological neural network model, character and pattern recognition, etc., can solve the problems of time-consuming and laborious, the influence of subjective judgment of inspectors, low efficiency of manual visual inspection, etc., and save manpower The effect of high material strength and high segmentation accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
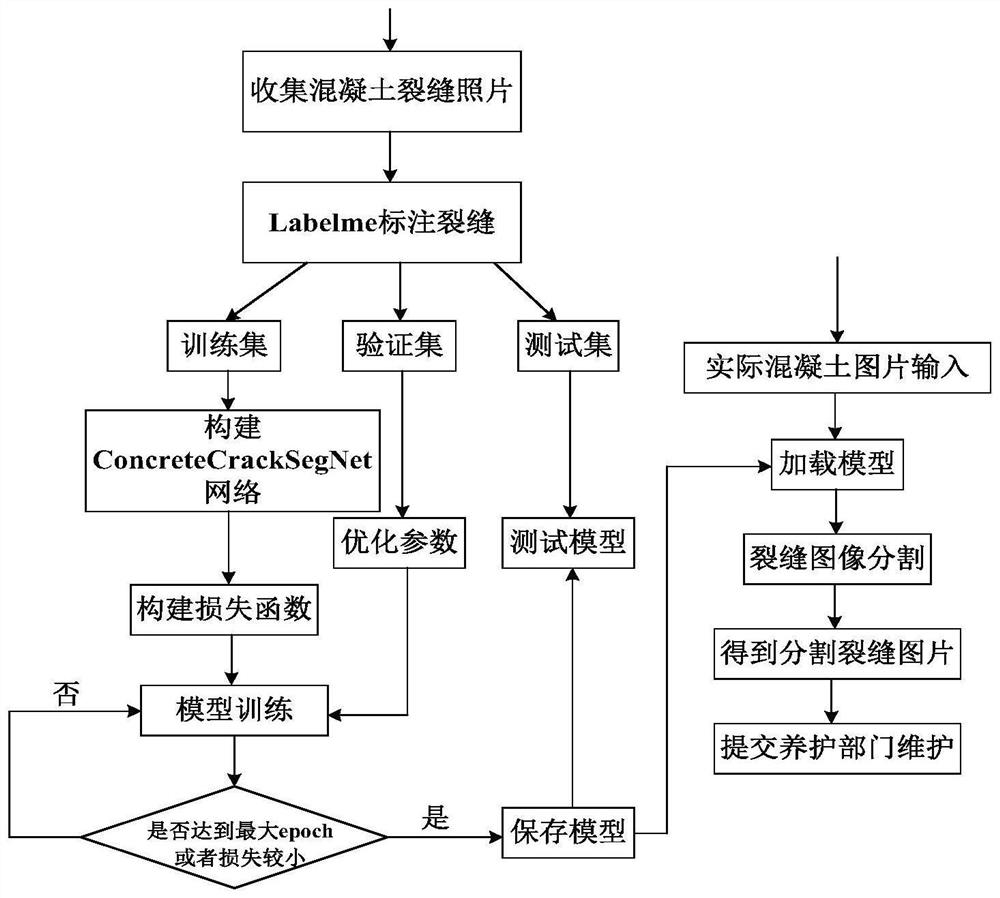
[0037] In order to facilitate understanding of the present application, the present application will be described more fully below with reference to the related drawings. The preferred embodiments of the present application are shown in the accompanying drawings. However, the present application may be implemented in many different forms and is not limited to the embodiments described herein. Rather, these embodiments are provided so that a thorough and complete understanding of the disclosure of this application is provided.
[0038] like figure 1 As shown, the concrete crack detection method based on ConcreteCrackSegNet includes the following steps:
[0039] 1. Collect concrete photos of bridge concrete structures and highways through drone photography, industrial cameras, etc., some of which contain cracks and diseases;
[0040] 2. Use LabelMe software to label photos. LabelMe is a software for labeling images. Use LabelMe to label the bounding box polygons of cracks and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More