

Rapid decoding method for voice identifying system
A technology of speech recognition and decoding methods, applied in speech recognition, speech analysis, instruments, etc., which can solve the problems of high hardware computing power and memory requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

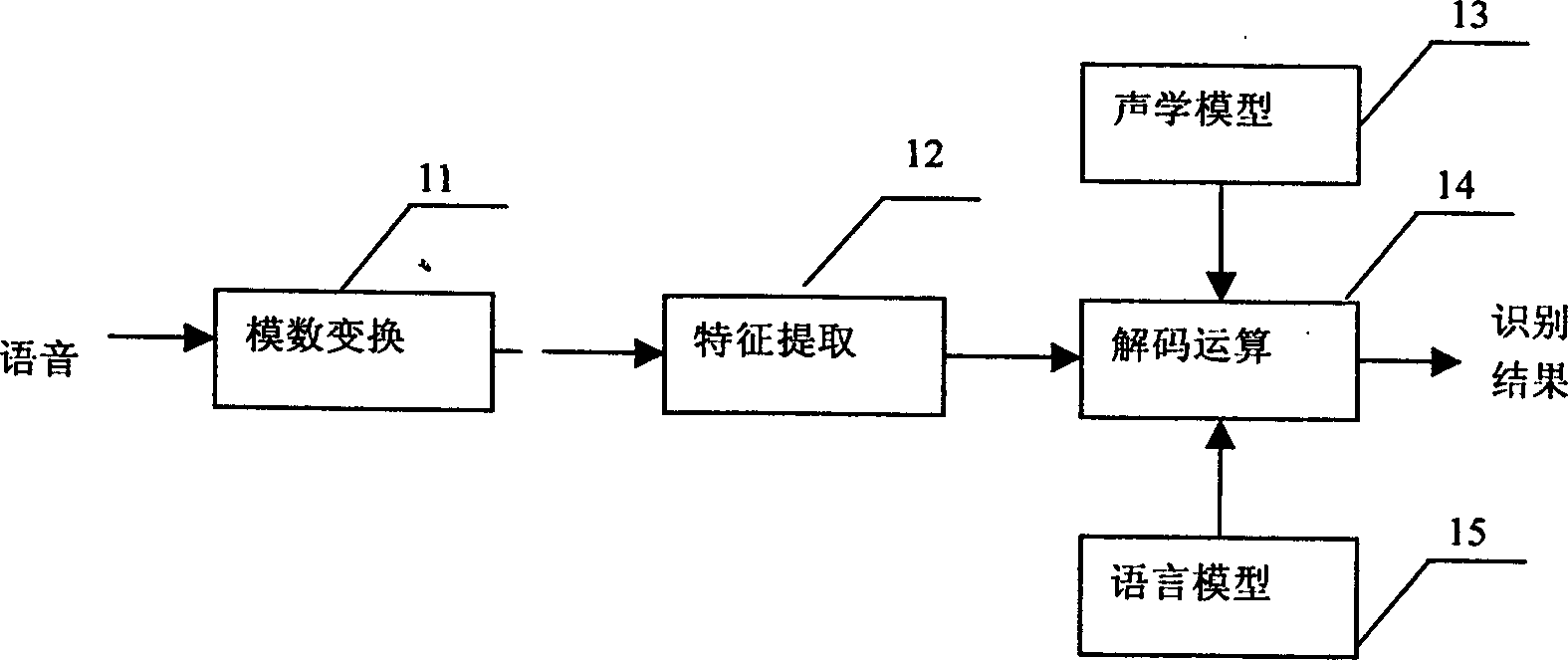
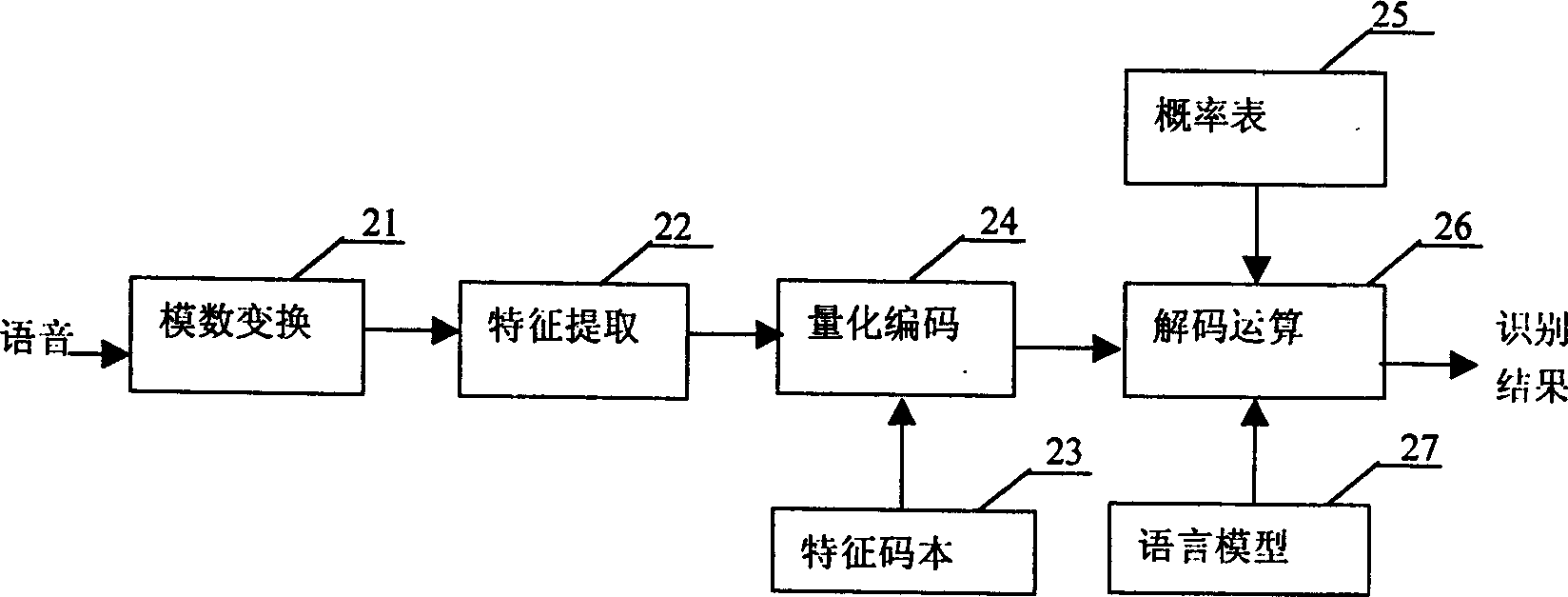
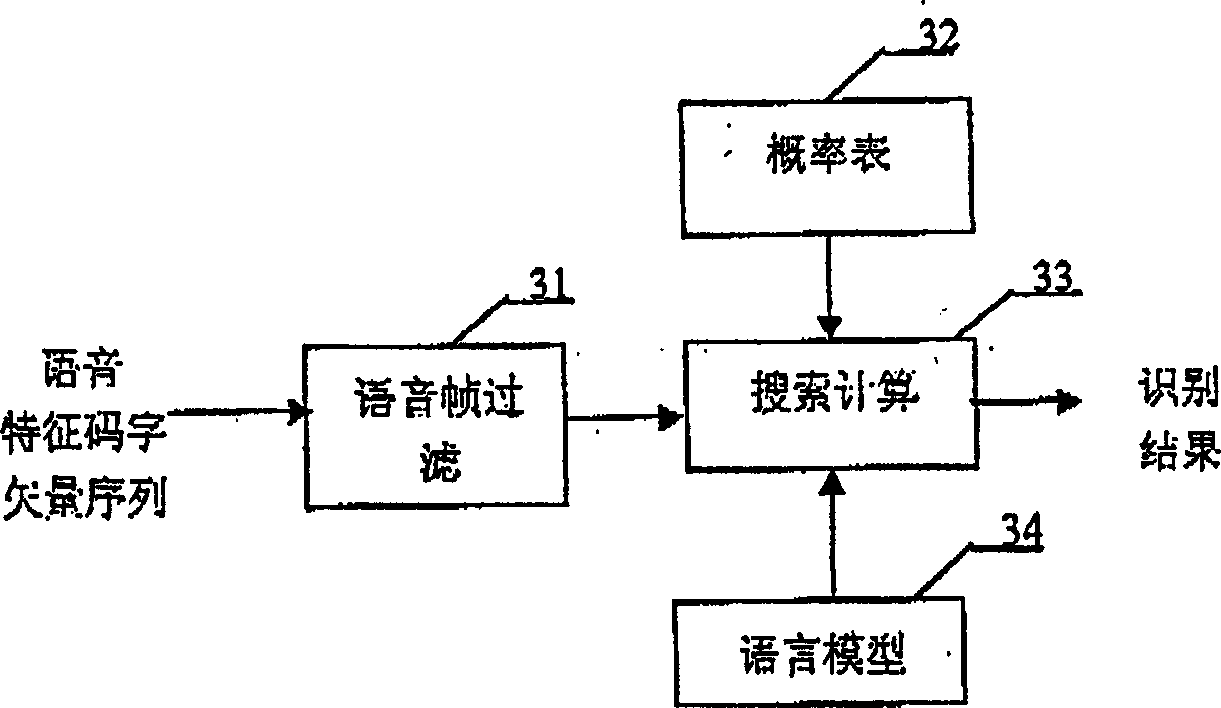
Examples
Embodiment Construction
[0084] specific implementation
[0085] image 3 The decoding operation flow chart of the present invention is given. Depend on figure 2 , combine image 3 , the operating flow of the voice recognition system based on the decoding operation subsystem of the present invention is: the input voice analog signal is converted into a digital signal; the digital signal is processed in frames, and the characteristic parameters of each frame of voice are extracted, and each voice Frame corresponds to a feature vector, obtains the feature vector sequence of input speech; Utilizes feature code book to carry out quantization encoding to described feature vector sequence, each speech frame corresponds to a feature codeword vector, obtains corresponding feature codeword vector sequence; Speech The speech frame filtering unit of the characteristic codeword vector sequence input decoding operation subsystem, do the speech frame filtering operation, remove the characteristic codeword vecto...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More