

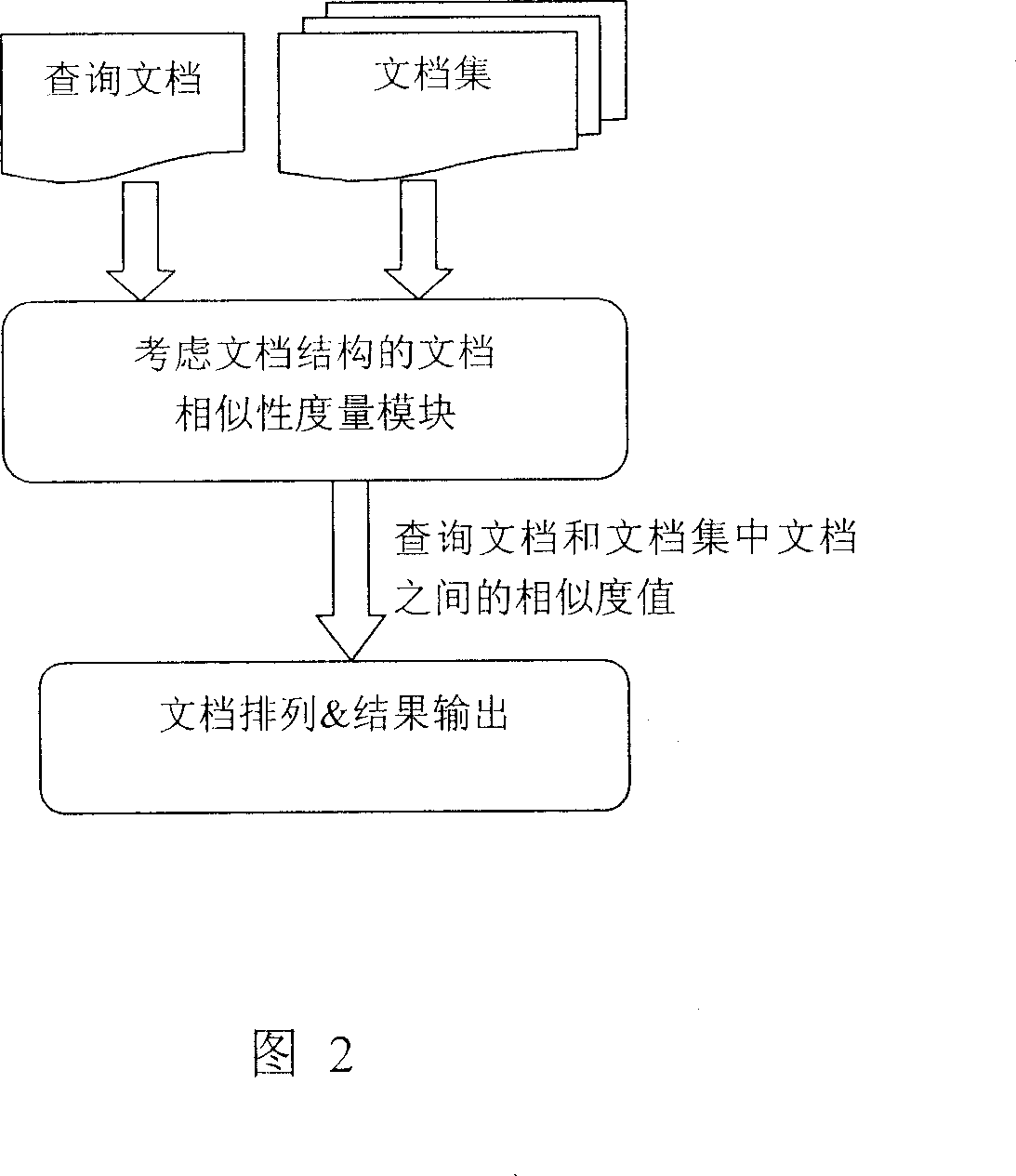
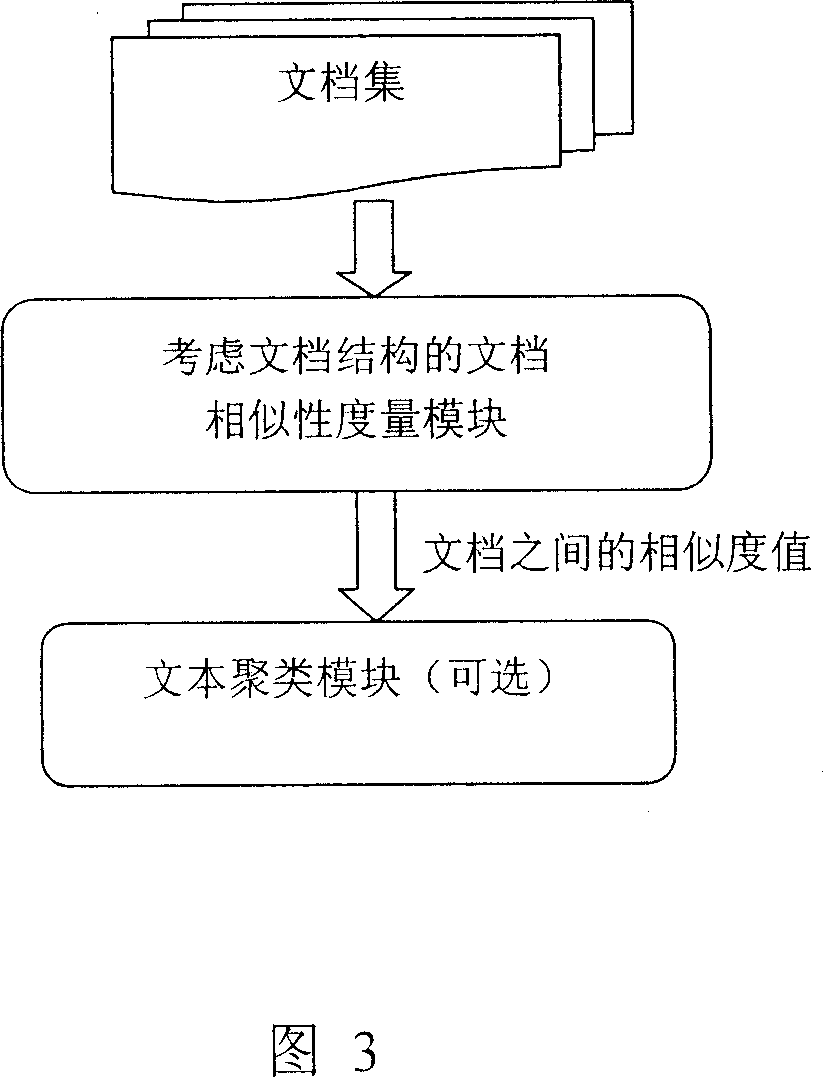
Measure of similarity of documentation based on document structure
A technology of similarity measurement and document structure, applied in the fields of instrumentation, calculation, electrical and digital data processing, etc., can solve the problem of low accuracy of measurement methods, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
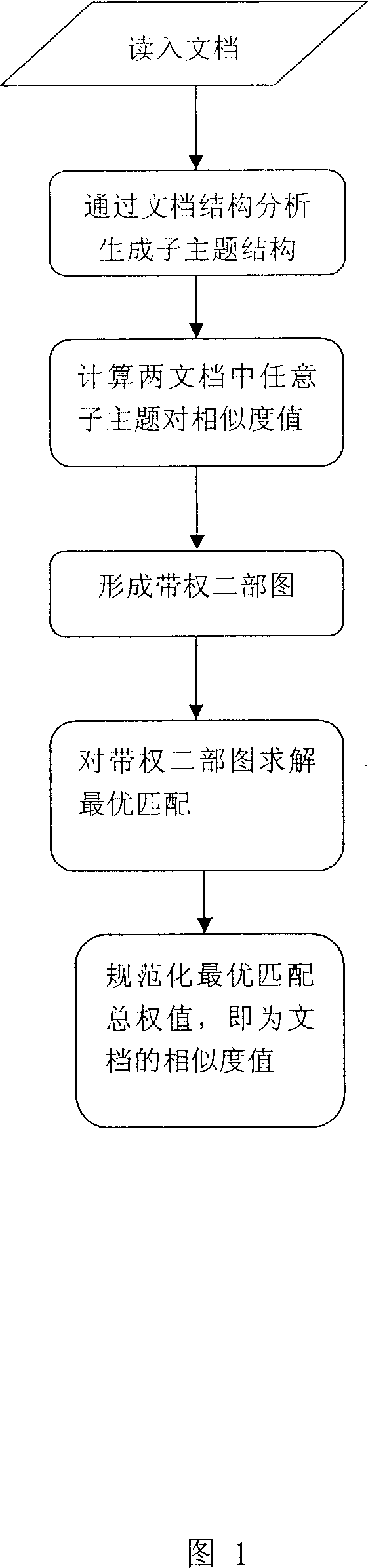
[0034] In preferred embodiment one of the present invention, a text block segmentation method (TextTiling) is adopted to analyze the document structure, and the flow process includes the following steps as shown in Figure 1:
[0035] 1. Read in the two documents X and Y that need to be compared. For the two documents X and Y that need to be compared, use the text block segmentation method (TextTiling) to obtain the subtopic sequence X={x 1 , x 2 ,...,x n} and Y={y 1 ,y 2 ,...y m}, the specific steps are:
[0036] ① Segment the read document X, divide every 20 words into a word string, and the size of the word string can be selected according to needs.
[0037] 2. Calculate a similarity value for the position between each two word strings by the following method: for the position between word string i and word string i+1, calculate the text block composed of word string i-k to word string i The cosine similarity value between the text blocks composed of word string i+1 to...
Embodiment 2
[0058] The second preferred embodiment of the present invention uses clustering technology to analyze the document structure, including the following steps:
[0059] 1. Read in the two documents X and Y that need to be compared, and use the clustering method to obtain the document subtopic sequence for the two documents X and Y respectively. The specific algorithm steps are:
[0060] ① Segment the read document and divide the document into n sentences;
[0061] ② Calculate the cosine similarity value between any two sentences;
[0062] ③Using the data clustering method to cluster the sentences, the text composed of all the sentences in each category
[0063] This block is a subtopic. In this embodiment, the aggregated clustering method is used to cluster sentences, and the steps are:
[0064] a. Initially, each sentence is classified into one category, and there are k clusters in total;
[0065] b. The two clusters with the largest similarity value among the existing k clu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More