

Discovering terms using statistical corpus analysis
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
example embodiment
II. Example Embodiment
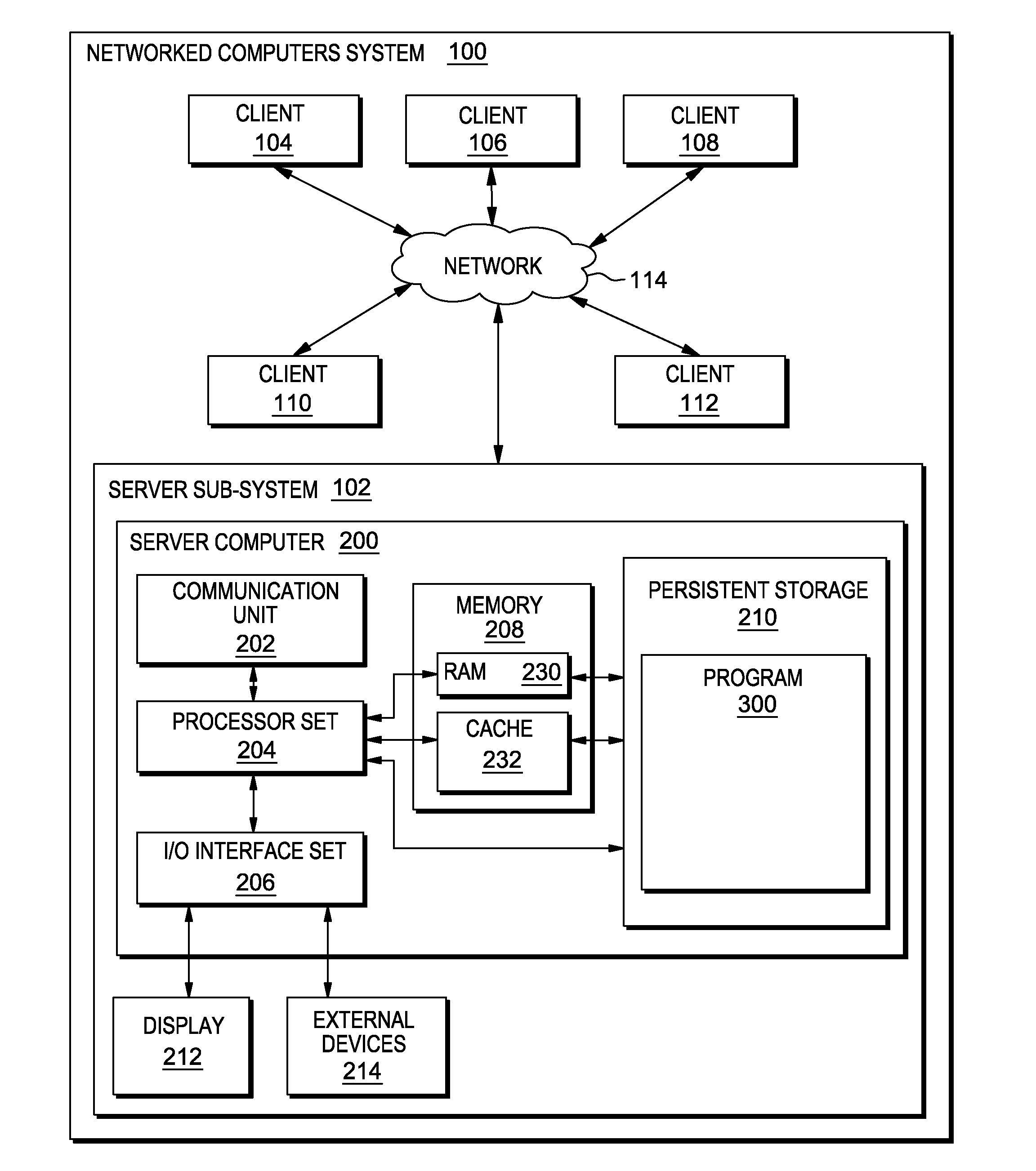
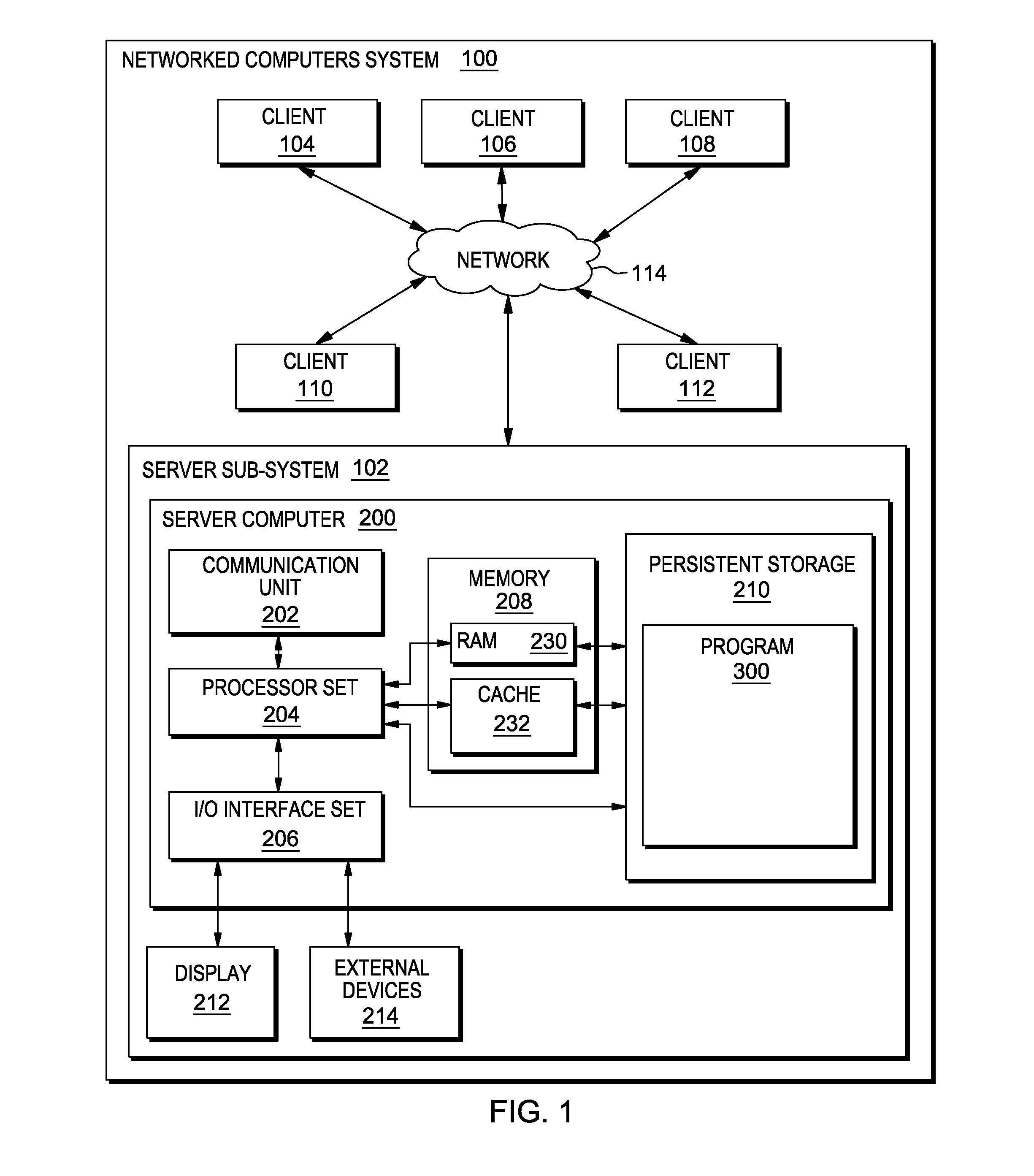
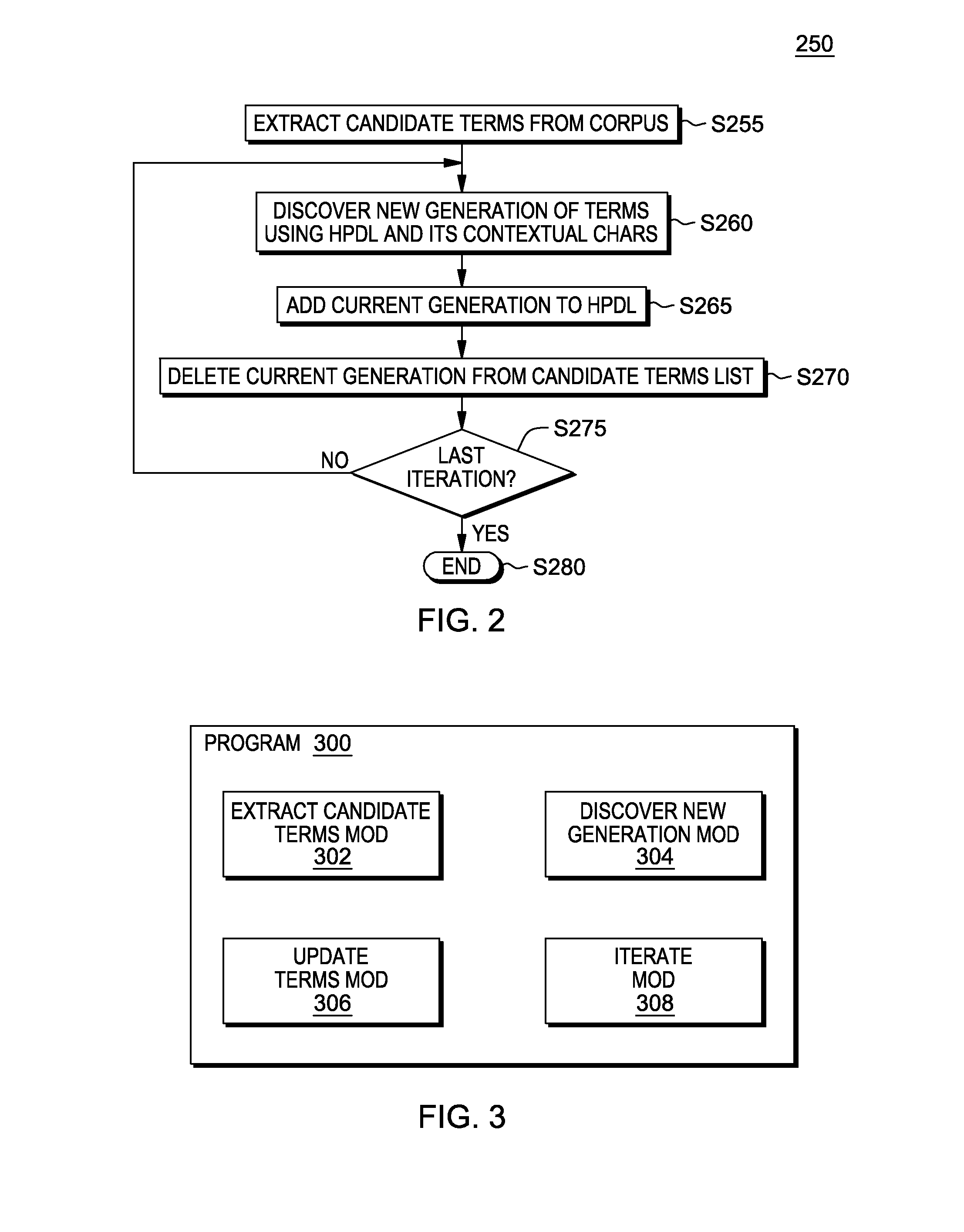
[0045]FIG. 2 shows flowchart 250 depicting a method according to the present invention. FIG. 3 shows program 300 for performing at least some of the method steps of flowchart 250. This method and associated software will now be discussed, over the course of the following paragraphs, with extensive reference to FIG. 2 (for the method step blocks) and FIG. 3 (for the software blocks).
[0046]The present embodiment refers extensively to a high precision domain lexicon (HPDL). The HPDL (also referred to as a “set of category related terms”) is a collection of terms (words or sets of words) that belong to a specific domain, category, or genre (“domain”). In term extraction, and more generally in natural language processing, the HPDL can serve as an underlying “knowledge base” for a given domain so as to extract more contextually relevant terms from a piece of text (or corpus). In many embodiments of the present invention, the HPDL is used to: (i) extract contextually ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More