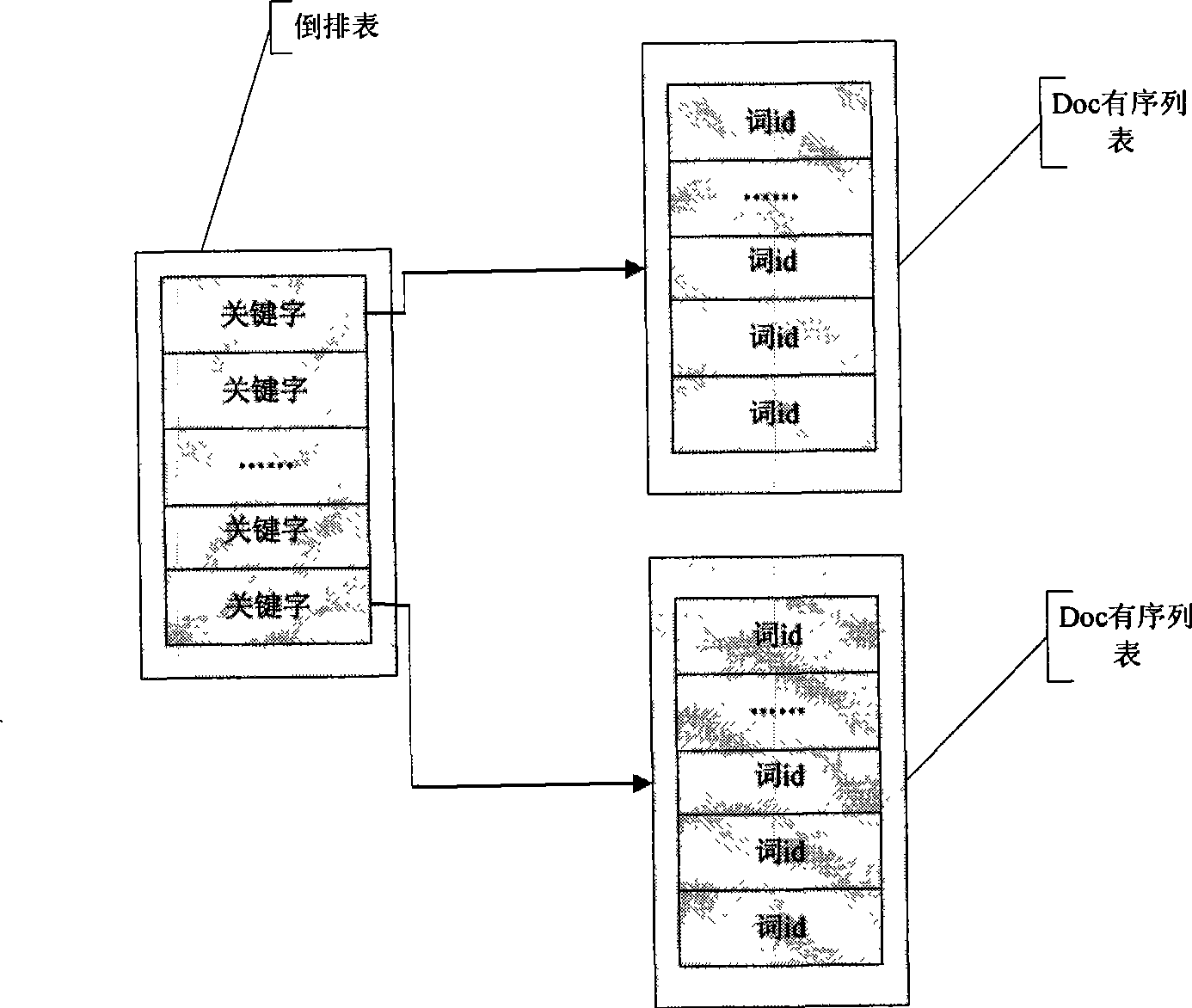
Thesaurus fuzzy enquiry method and thesaurus fuzzy enquiry system
A technology of fuzzy query and thesaurus, applied in the field of thesaurus query, can solve the problem of slow fuzzy query speed, and achieve the effect of fast query speed, reduced storage space, and comprehensive query
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0061] The present invention will be described in detail below in conjunction with the accompanying drawings.
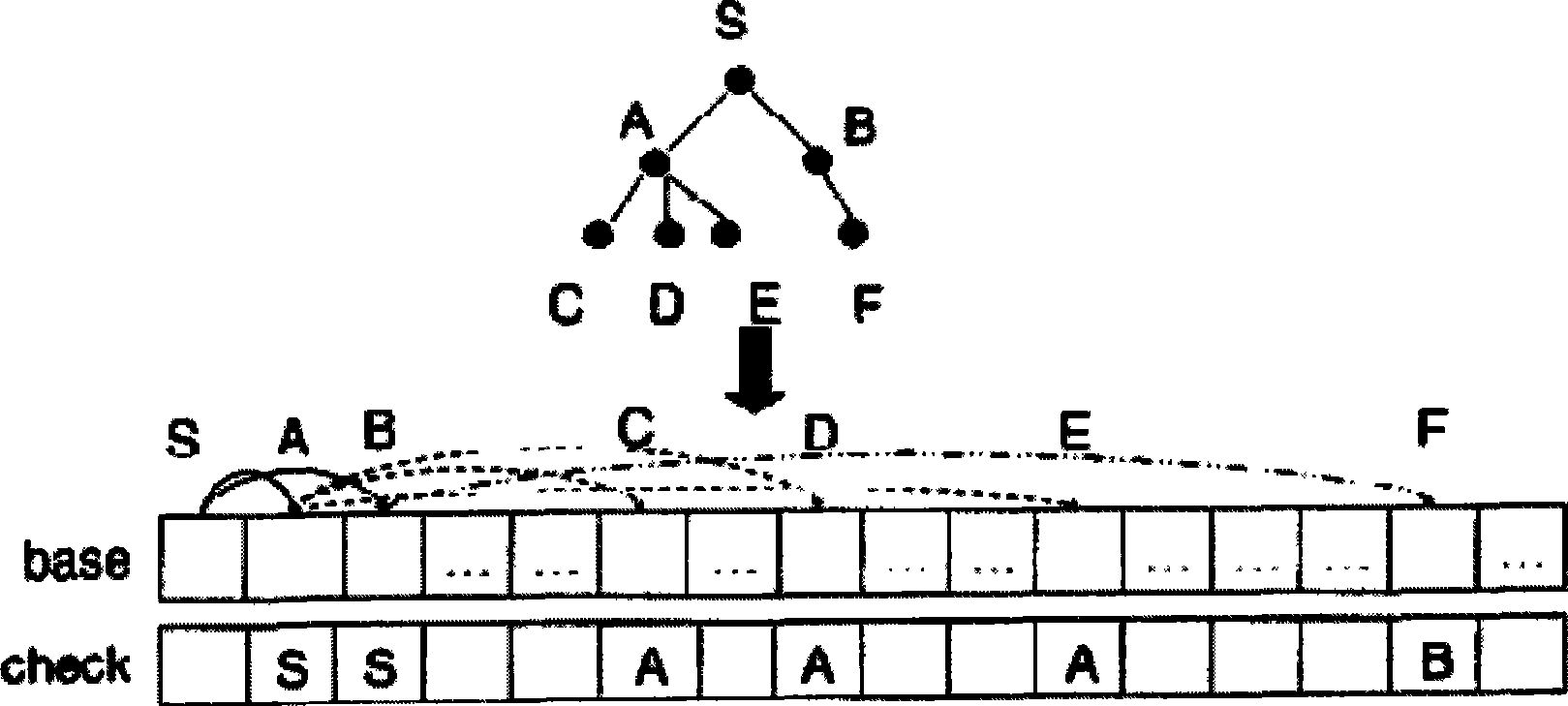
[0062] Since the present inventor has absorbed the essence of the double-array Trie for the invention and creation, before introducing the fuzzy query of the thesaurus of the present invention in detail, first introduce the double-array Trie.
[0063] If you want to query the double-array Trie, you first need to construct the double-array Trie, and determine the base value array and the corresponding check value array.
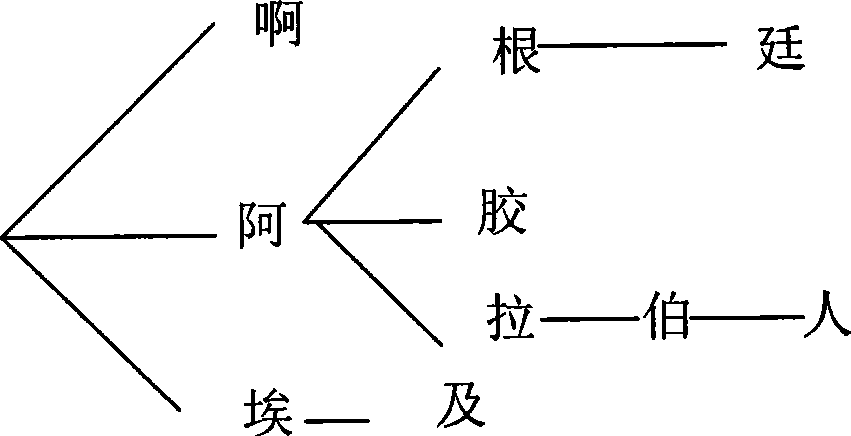
[0064] Assume that there are only words "Ah, Argentina, Ejiao, Arabia, Arabs, Egypt" in the thesaurus.
[0065] First, encode all 10 Chinese characters that appear in the lexicon: Ah-1, Ah-2, Ai-3, Gen-4, Jiao-5, La-6, and-7, Ting-8, Bo-9 , person-10. This encoding is not unique, it only needs to encode all the characters in the thesaurus one by one, which can be sequential encoding, or the corresponding encoding of each Chinese character that alre...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



