

Method and device for classifying text and structuring text classifier by adopting characteristic expansion
A classifier and construction technology, applied in the direction of instruments, character and pattern recognition, special data processing applications, etc., to achieve the effect of improving classifier performance, good recognition ability, and good classification ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

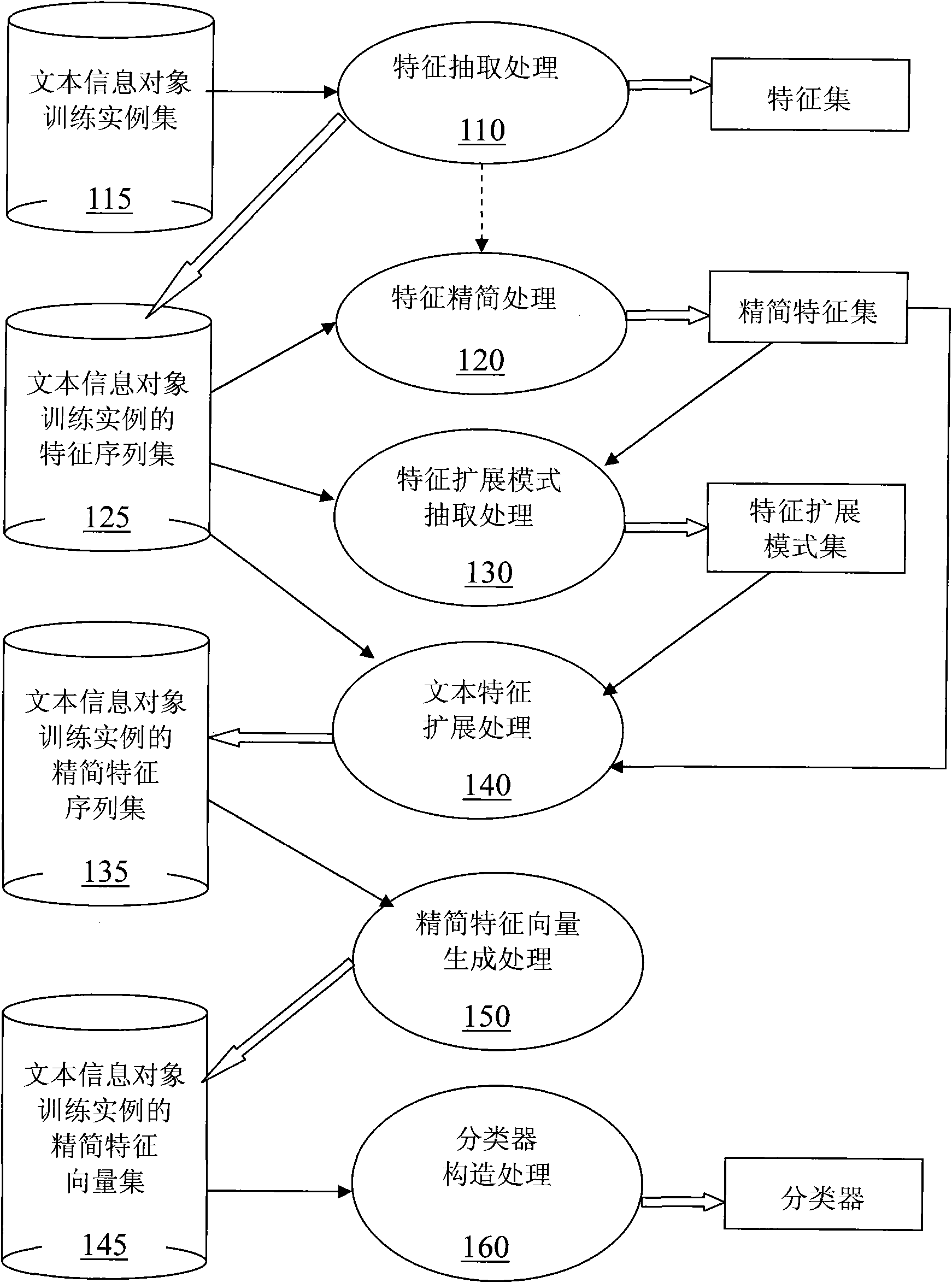
Examples
Embodiment approach 1
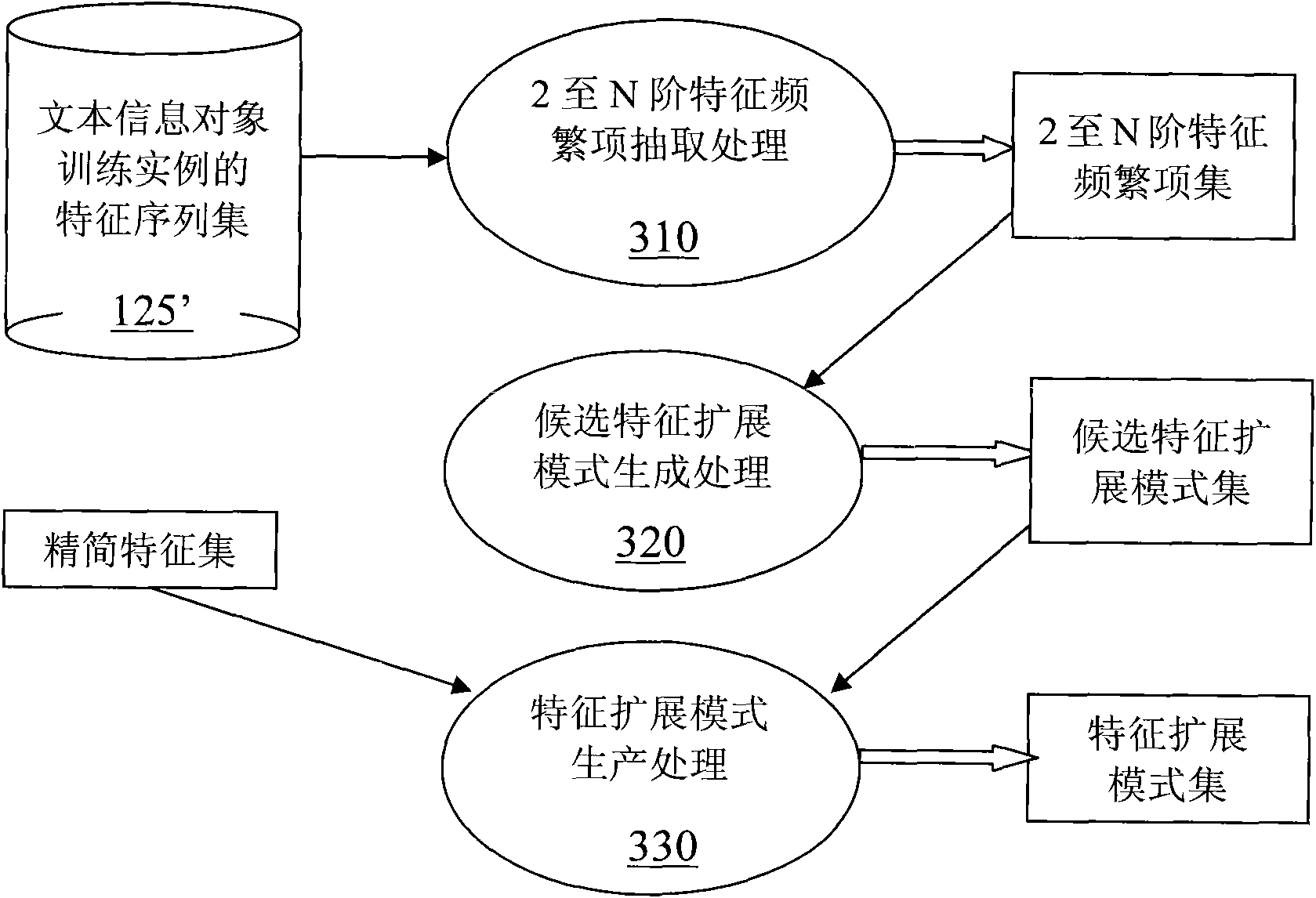
[0054] Embodiment 1: Extract feature extension patterns using association rule algorithms. Such as figure 2 Shown is a flow chart of extracting feature extension patterns using the association rule algorithm. The extraction process is as follows:
[0055] Step 1.2 to N-order feature frequent item extraction processing 310
[0056] Set the left part information table of the input feature expansion mode, the information table includes the maximum number of features N, support and confidence thresholds that can be included in the left part of the input feature expansion mode, the scanning module scans the feature sequence set 125' of the text training instance, Each feature sequence is processed as follows, using the association rule mining algorithm (the classic FP-Growth algorithm can be selected), extracting X-order frequent items that meet the support requirements from the feature sequence, and constructing 2-N order feature frequent itemsets, where 2≤X≤N+1.
[0057] Step...
Embodiment approach 2
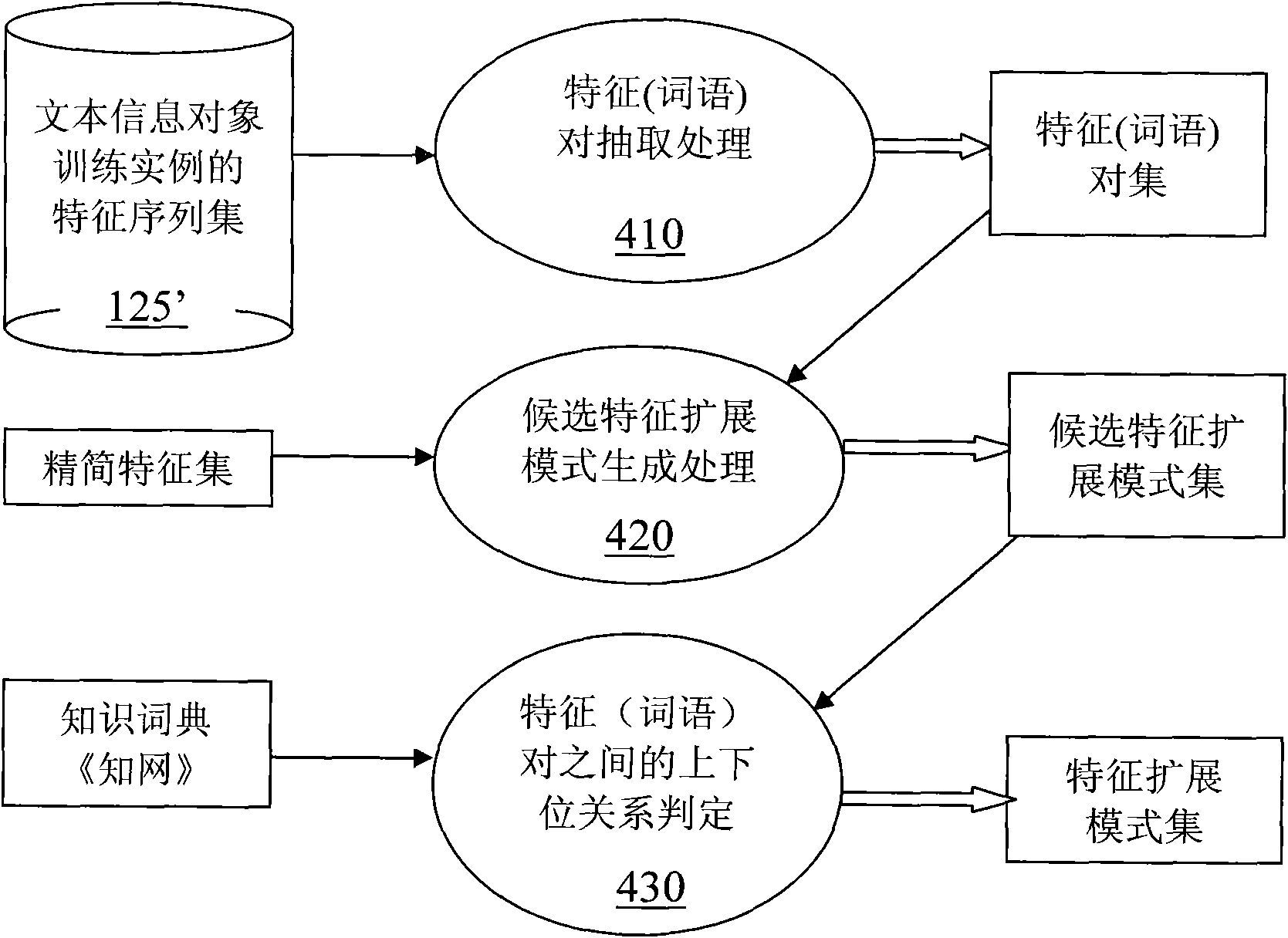
[0061] Embodiment 2: Use a knowledge dictionary (such as "HowNet") to extract feature expansion patterns. In this embodiment, the types in the feature set are limited to words. Such as image 3 Shown is the flow chart of the extended mode of feature extraction using HowNet. The specific process is as follows:
[0062] Step 1. Word Pair Extraction Processing 410
[0063] The feature sequence set of the text training instance is used as input, which is input to the extraction processing module for processing, and the output is a word pair set.
[0064] Set the distance threshold θ between word pairs. The scanning module scans the feature sequence set 125' of the text training instance, and the extraction processing module processes each feature sequence as follows: obtain the positions of the two words in the feature sequence, calculate the difference between the positions of the two words, and compare the difference with the distance threshold θ , extract word pairs whose d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More