

E-Science environment-oriented multi-domain Web text feature extracting system and method
A feature extraction and multi-field technology, applied in the field of Web text feature extraction, can solve problems such as restricting the application range of Chinese information extraction systems, inconvenient experiment reproduction, difficult transplantation and promotion, etc., to enhance portability and practical value, improve utilization efficiency effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

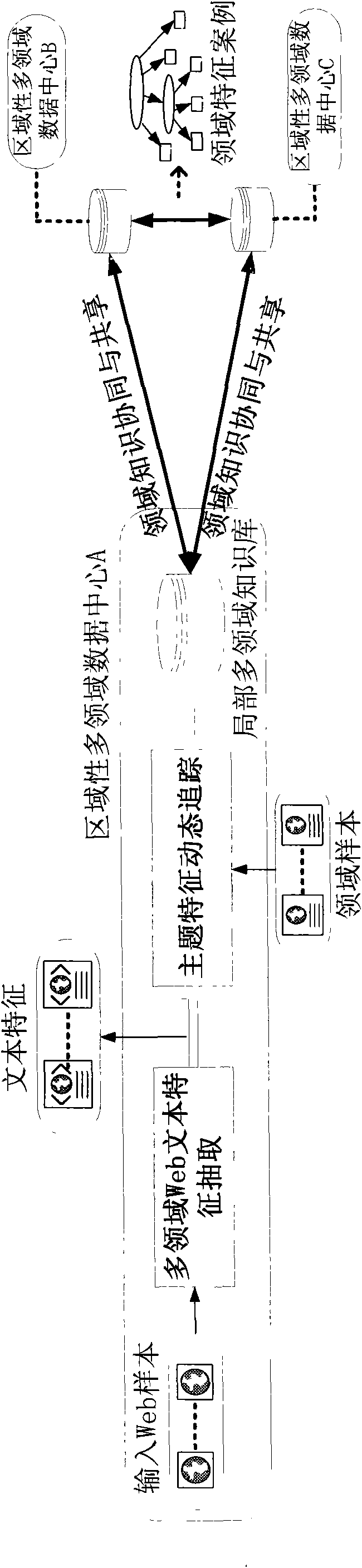
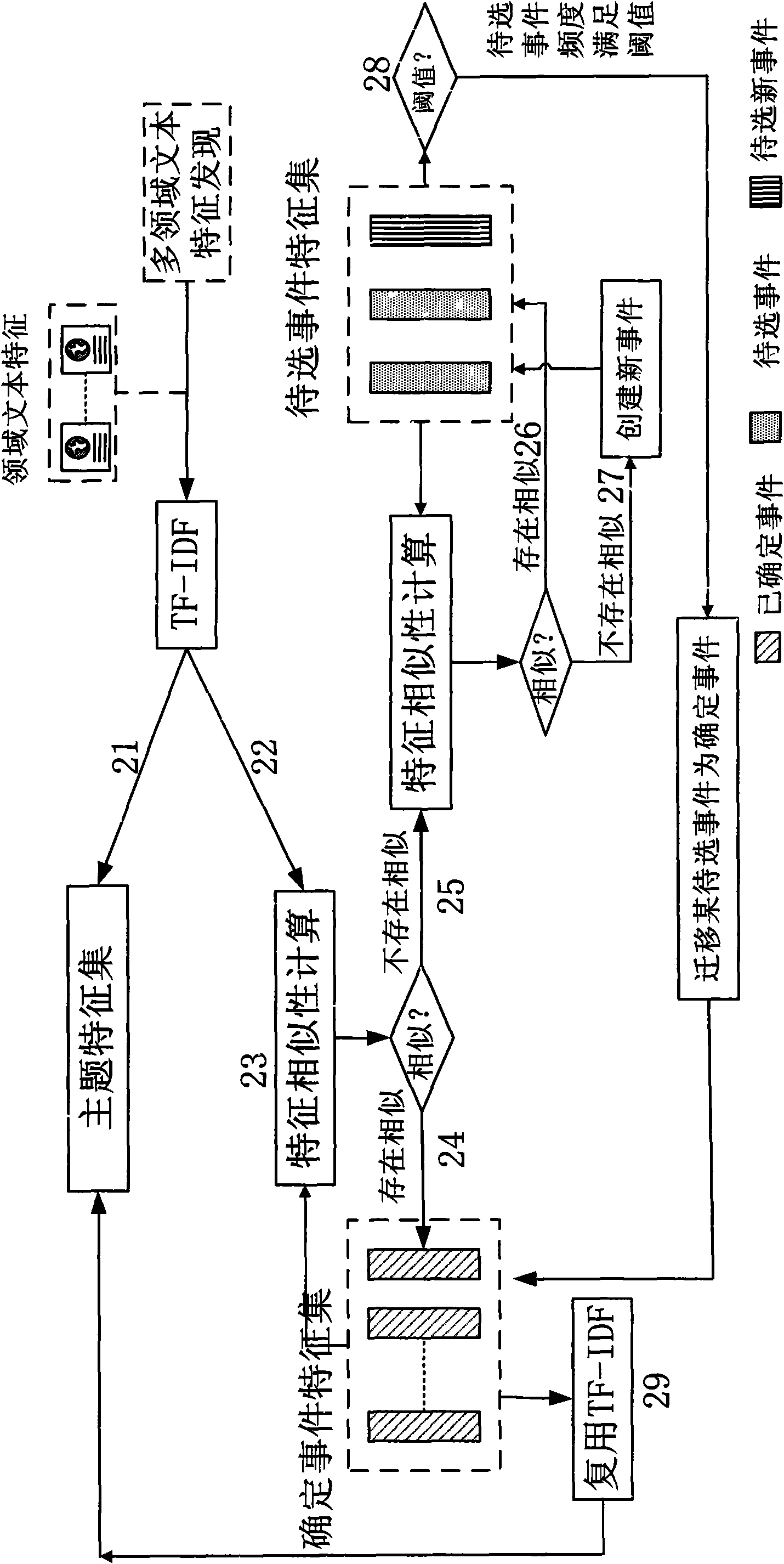
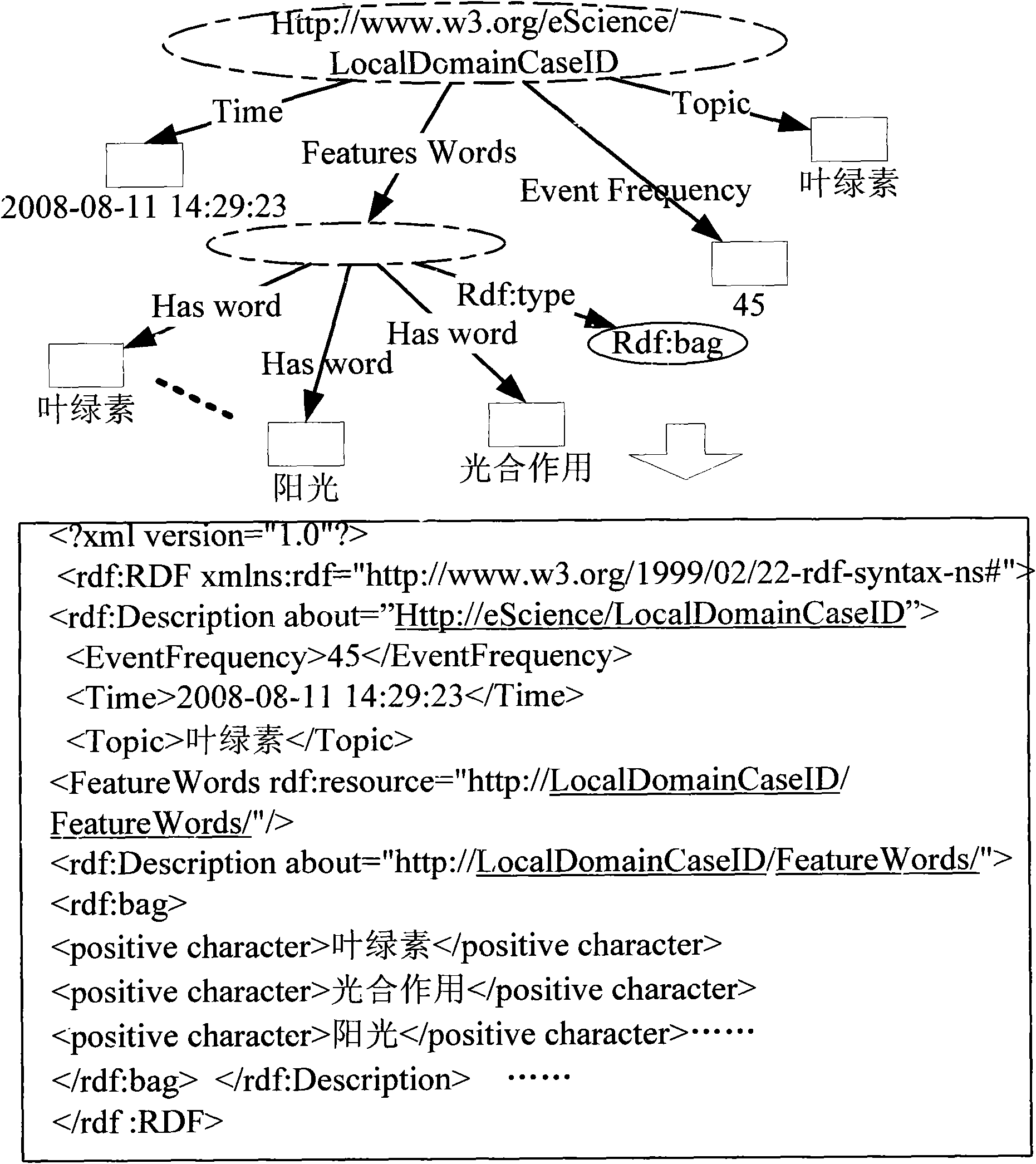
Examples
Embodiment Construction
[0040] The present invention will be described in further detail below in conjunction with the accompanying drawings.
[0041] The multi-domain Web text feature extraction system for e-Science environment mainly considers the following three aspects during the design process: First, get rid of the dependence on domain dictionaries. The role of domain dictionaries in most Chinese information extraction systems is to segment texts and perform data preprocessing for feature discovery. However, due to its limitations in quantity and update speed, it seriously restricts the ability of the Chinese information extraction system to discover new events and the latest vocabulary in the field, which is not conducive to the transplantation and promotion of the Chinese information extraction system. The introduction of dictionary-free word segmentation technology will effectively improve the knowledge learning ability of the Chinese information extraction system, and is more suitable for f...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More