

Method and device for realizing association rule mining algorithm supporting distributed computation
A distributed computing and mining algorithm technology, applied in the computer field, can solve problems such as slow computing efficiency and insufficient rule mining results, and achieve fast computing efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment
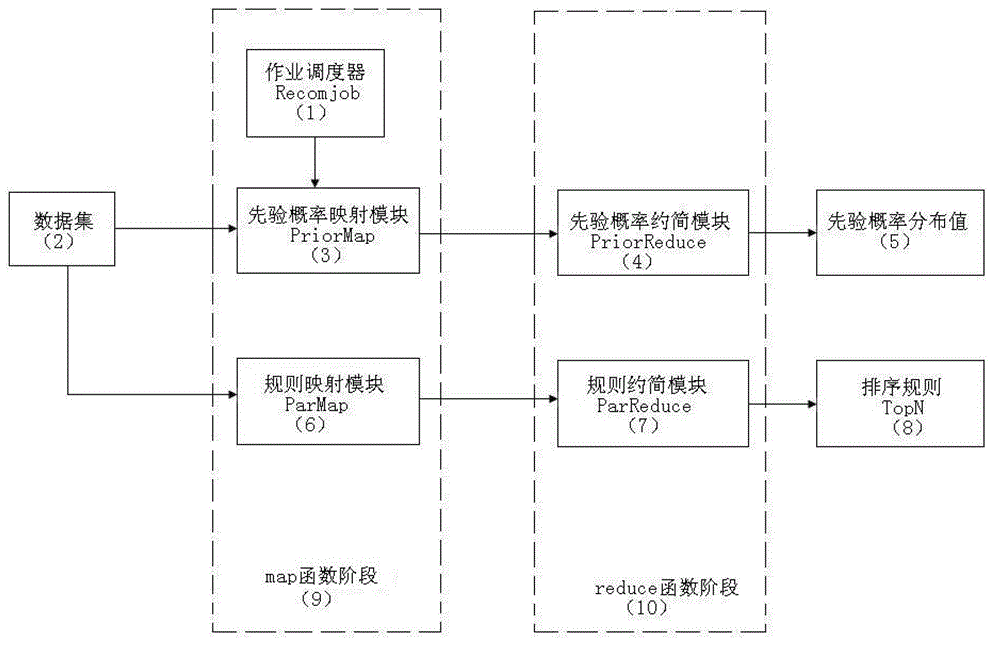
[0035] Embodiment: a method for implementing an association rule mining algorithm that supports distributed computing in this embodiment, such as figure 1 As shown, using the distributed file system Hadoop programming model MapReduce to decompose the association rule mining algorithm PA into two stages of map function stage 9 and reduce function stage 10, the decomposition steps are as follows:
[0036] Step 1: Configure the job scheduler Recomjob1;
[0037] Step 2: Use the prior probability mapping module PriorMap3 to read the data set 2, and convert the data rows of the data set into key-value pairs through the map function;
[0038] Step 3: Use the prior probability reduction module PriorReduce4 to read the key-value pairs processed in step 2, and use the reduce function to randomly generate the sorting rule TopN8 including the i-item set, and calculate the prior probability distribution value 5 of the confidence;
[0039] Step 4: Use the rule mapping module ParMap6 to rea...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More