Method for realizing web crawler tasks
A web crawler and task technology, applied in the field of web crawlers, achieves the effects of speed assurance, shortened development cycle, and reduced development difficulty
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
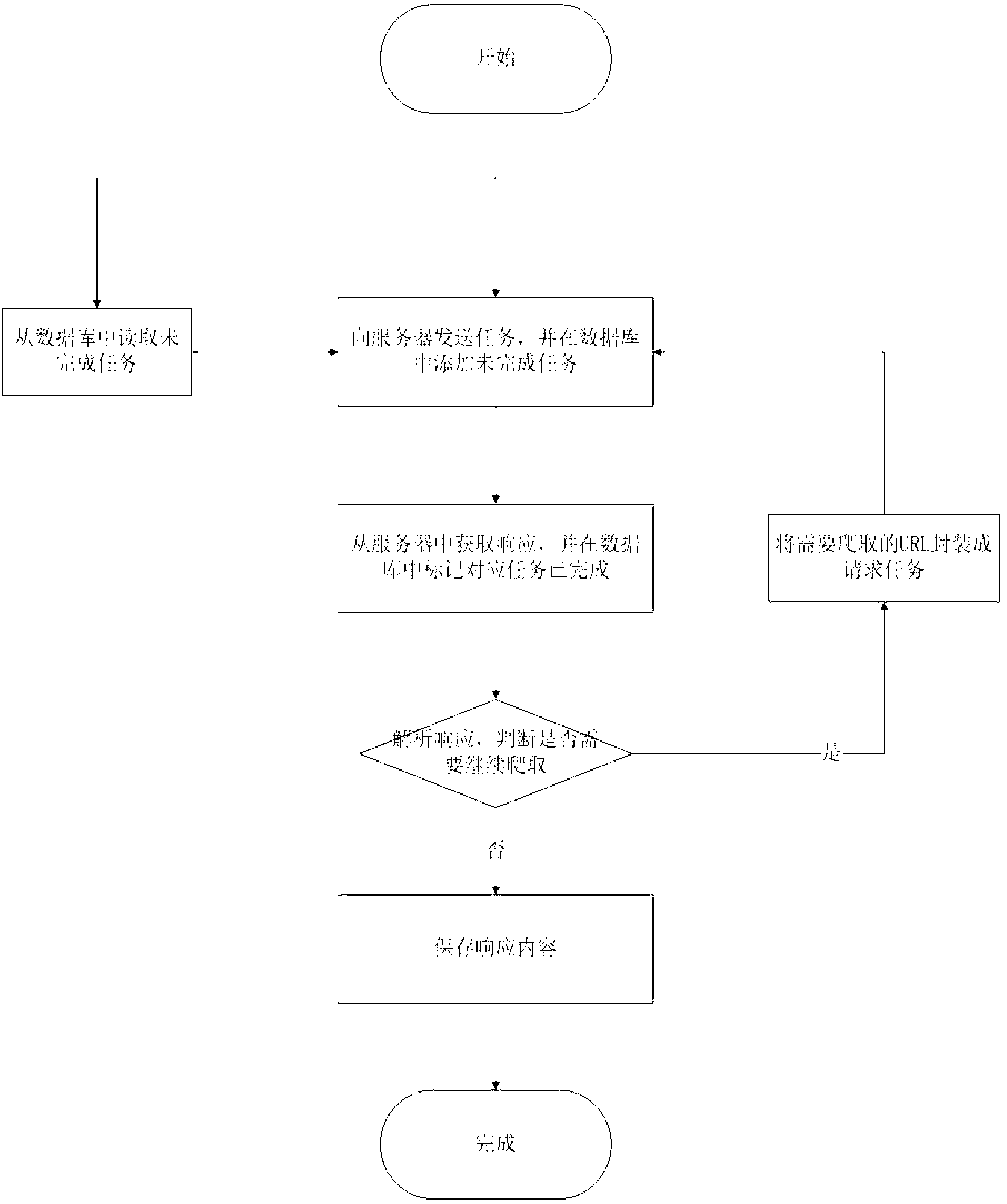
Embodiment : 1 system approach , specific 1 、 approach 。 specific Embodiment approach
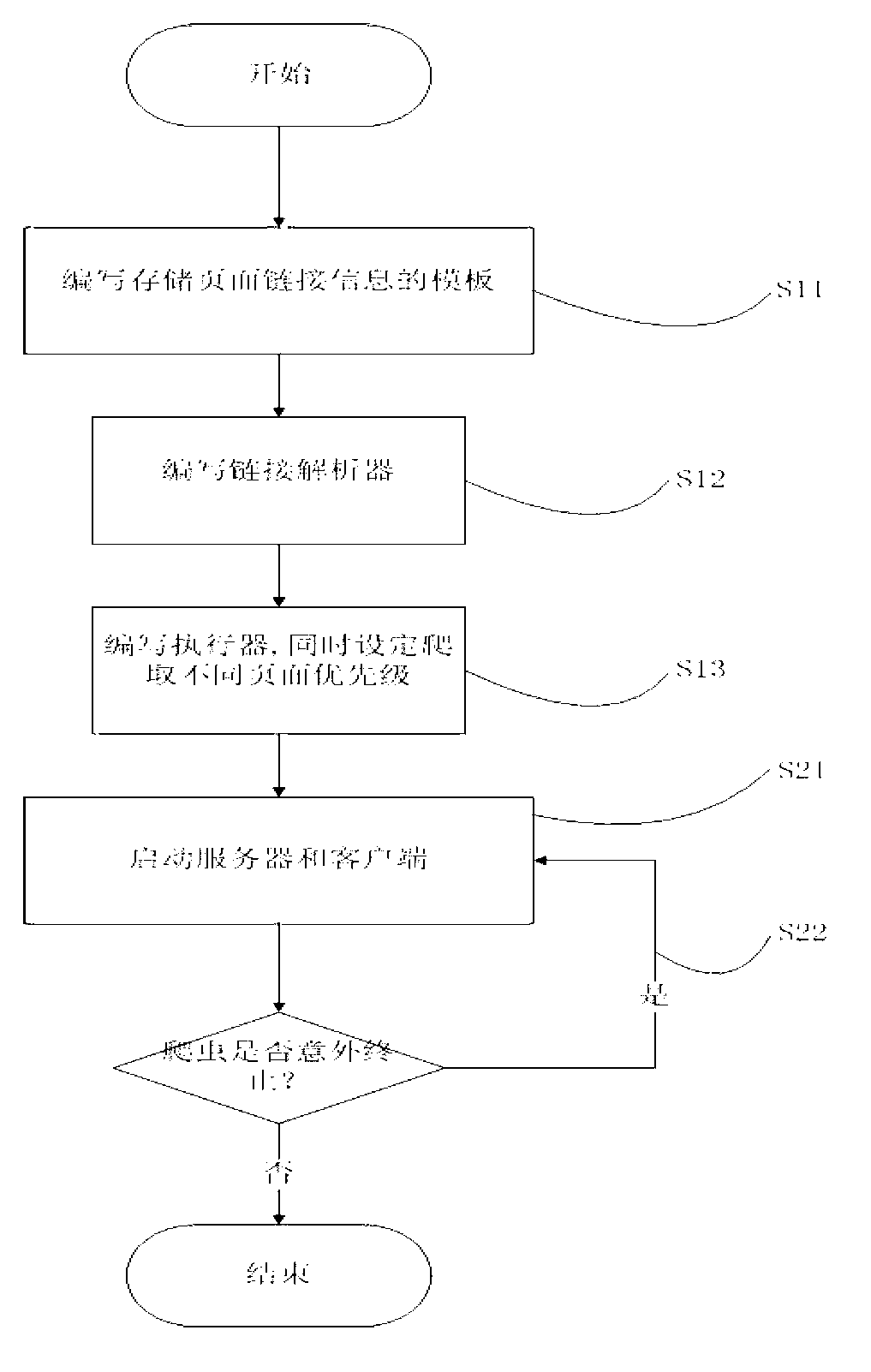
[0033] A. In step S11, write a template for storing page link addresses. This step creates a template for storing page link address information for each page that needs to be crawled. This template is equivalent to a blank page address record book, which can be used to save the link address of the crawled page and the depth information of the page. For example, the address link of the detailed information page of Wanfang Papers is:
[0034] (http: / / d.wanfangdata.com.cn / Periodical_ahzylczz201203001.aspx), the page depth is 3, then the content stored in the template is the above address link and depth value 3.
[0035] B. In step S12, write a link resolver. First, establish a regular expression, analyze the website that needs to be crawled, and write a regular expression that can extract the link address of this type of page from the content of the web page according to the characteristics of the link address of each page that needs to be crawled; secondly, Concrete implementa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com