

A Calculation Method of Document Semantic Similarity
A technology of semantic similarity and calculation method, which is applied in the field of document semantic similarity calculation, can solve the problems of little meaning, application, and semantic calculation method
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

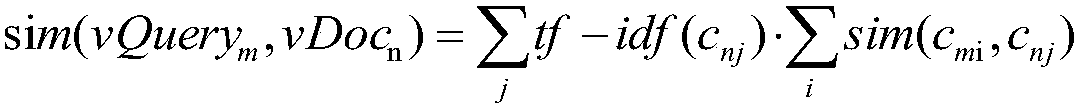
Examples
Embodiment Construction
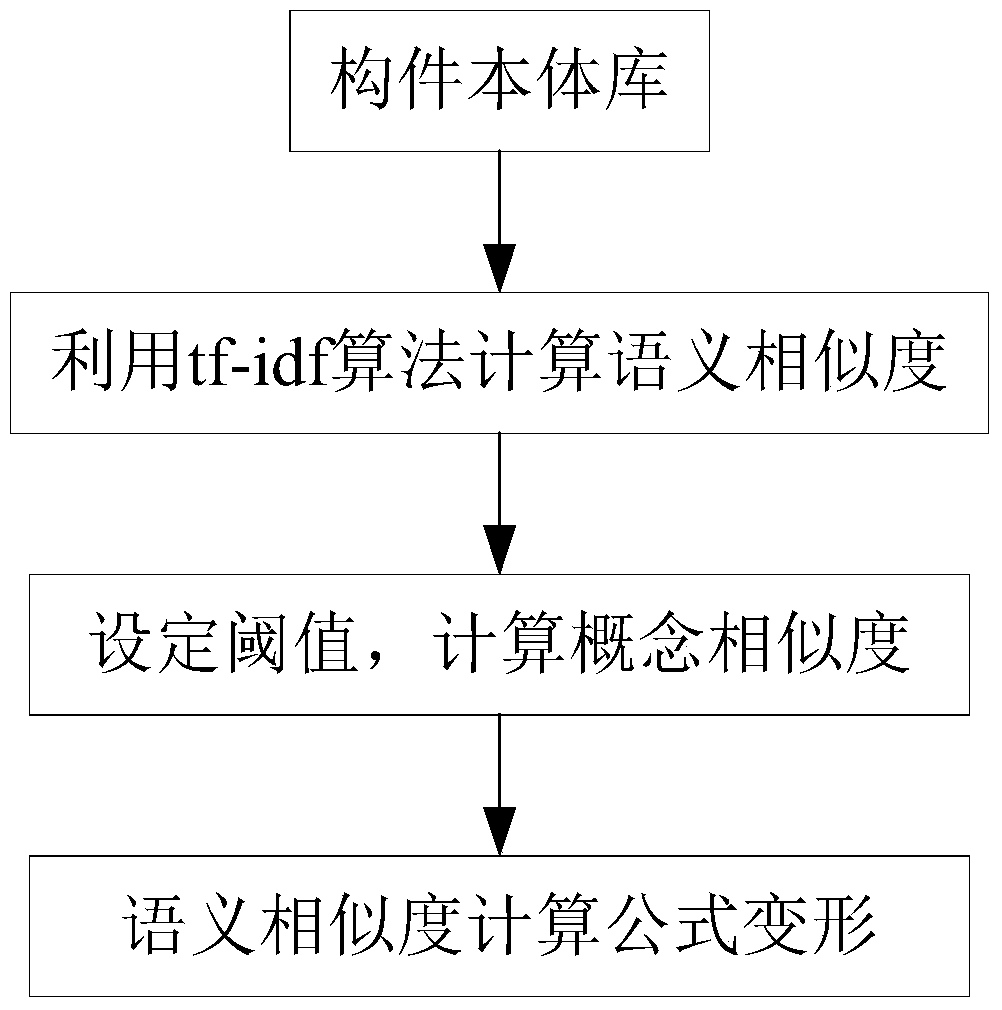
[0030] refer to figure 1 , a kind of document semantic similarity computing method that the present invention proposes, adopts the method for setting the threshold value, calculates the similarity between partitions, specifically comprises the following steps:
[0031] A. Construct one or more sets of ontology databases; construct an ontology database by inputting concept systems and main description words, in the ontology database, concepts form a concept tree according to the degree of association, and the concept tree forms a concept forest;
[0032] B. Calculate the semantic similarity; use the tf-idf (term frequency-inverse document frequency, term frequency-inverse document frequency) algorithm to calculate the query object vQuery m with documentation vDoc m The semantic similarity between, the calculation formula is,
[0033]
[0034] tf is the number of times the query object appears in the document, idf is a measure of the general importance of the query object, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More