

Estimation method for fundamental frequency of Chinese whispered speech
A technology of ear speech and fundamental frequency, which is applied in the field of speech signal processing, and can solve the problem of lack of fundamental frequency information of Chinese ear speech
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
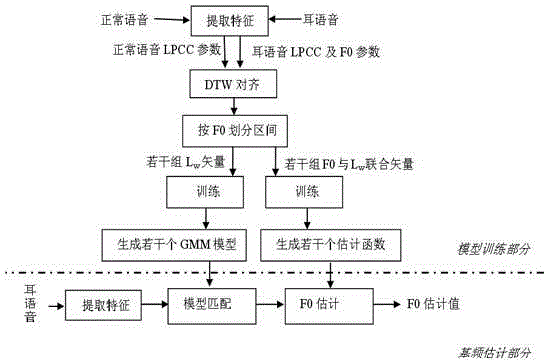
[0017] Embodiment one: see figure 1 Shown, a kind of fundamental frequency estimation method of Chinese ear speech, comprises the following steps:
[0018] (1) Establish a database of earphone and normal voice with consistent corpus, so that in the database, the speaker, voice content, and word order of earphone and normal voice are completely consistent;
[0019] (2) Extract the linear predictive cepstrum parameters L of ear speech respectively w , the linear predictive cepstrum parameter L of normal speech n and fundamental frequency parameter F0, and according to L w and L n Perform Dynamic Time Warping (DTW) alignment;
[0020] (3) Divide the F0 of normal speech between 100 and 300 Hz according to an interval of 5 Hz, and generate 40 intervals in total;
[0021] (4) All the aligned vectors are assigned to each interval according to the size of the normal speech F0, and the linear predictive cepstral vectors of all ear speech in each interval are trained as a Gaussian ...
Embodiment 2
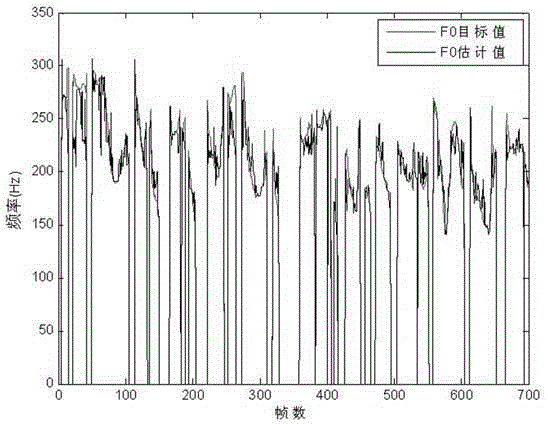
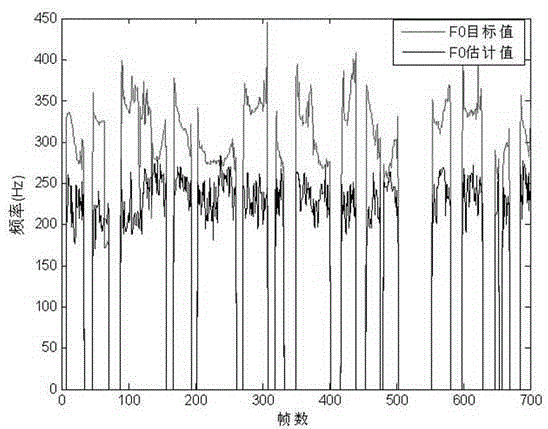
[0023] Embodiment 2: 80 speakers are selected to participate in the recording, including 40 males and 40 females, and the age ranges from children to the elderly, and the distribution is relatively balanced. The recording environment is quiet, the microphone is a handheld microphone, the sampling rate is 16KHz, and the quantization bit is 16bits. In order to ensure that children can participate in the recording smoothly, the recording text is collected from elementary school Chinese textbooks, including all Chinese tonal syllables composed of 21 initials and 35 finals in Chinese. The content of the corpus has been screened to ensure a balanced distribution of phonemes.
[0024] Each speaker pronounces the same corpus with ear speech and normal speech respectively. Due to the particularity of ear speech pronunciation, it is inevitable that there may be incorrect pronunciation methods. Therefore, all ear speech corpus data have undergone subjective spectrum observation to ensure...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More