

Access trace locality analysis-based shared buffer optimization method in multi-core environment
A shared cache and optimization method technology, applied in the direction of memory address/allocation/relocation, resource allocation, memory system, etc., can solve the problems of high overhead, insufficient dynamic behavior collection and analysis, waste of cache resources, etc., to reduce cache hotspots The probability of improving performance and the effect of improving cache performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
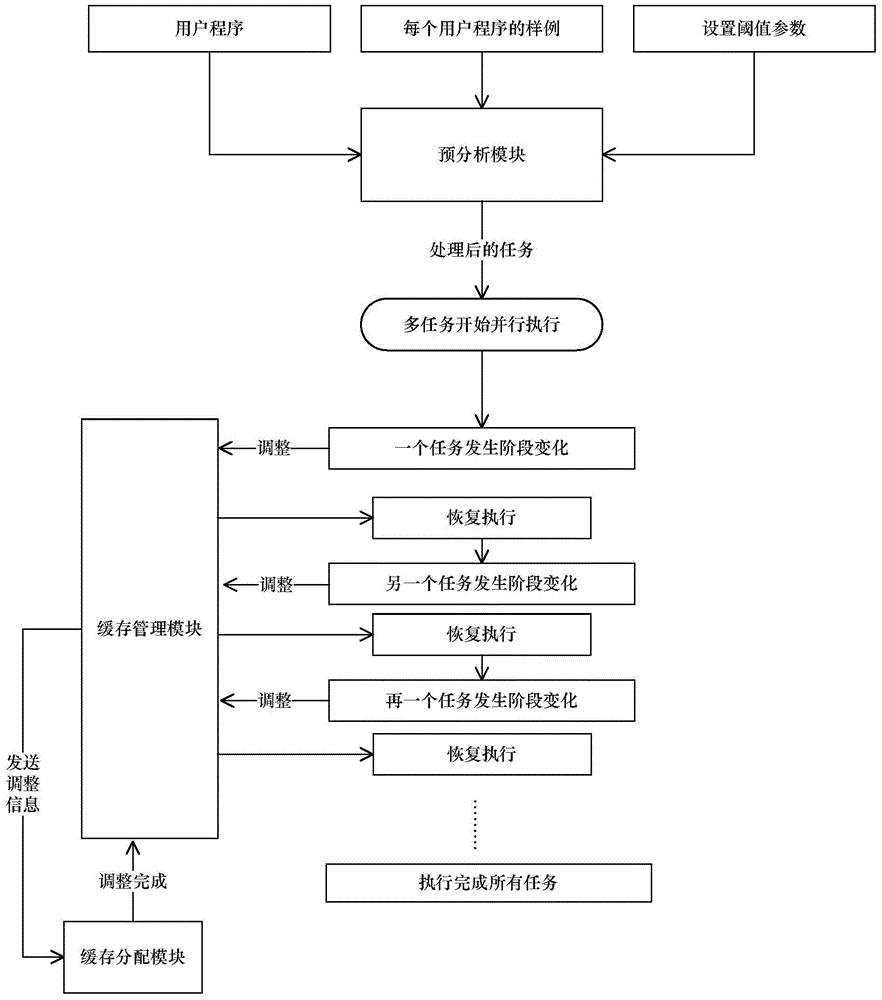
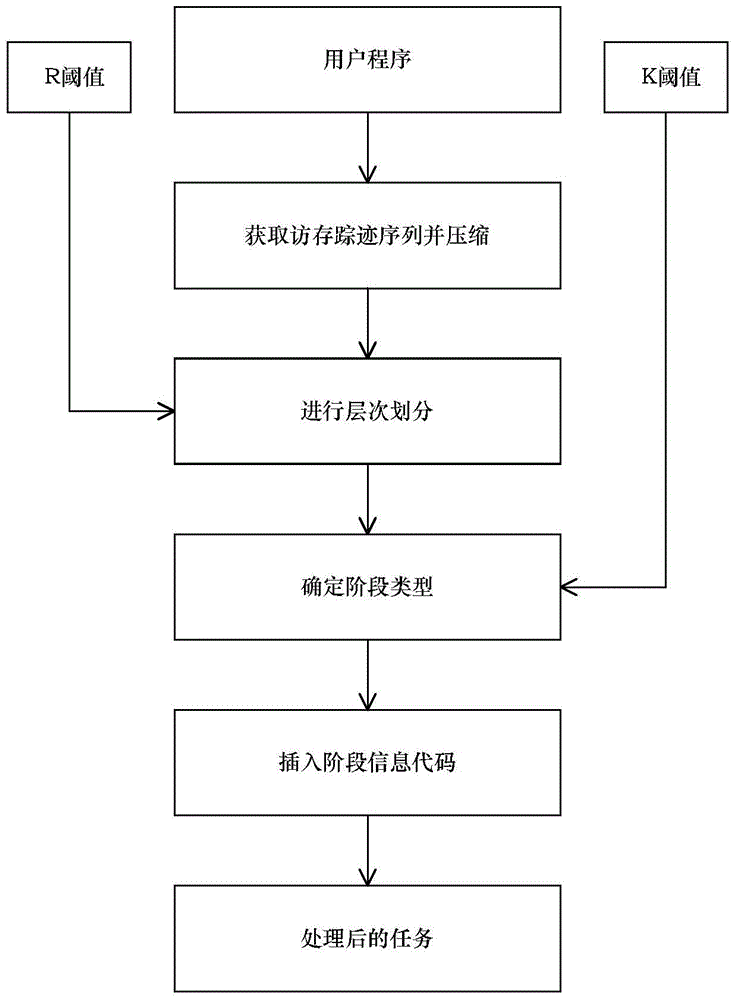
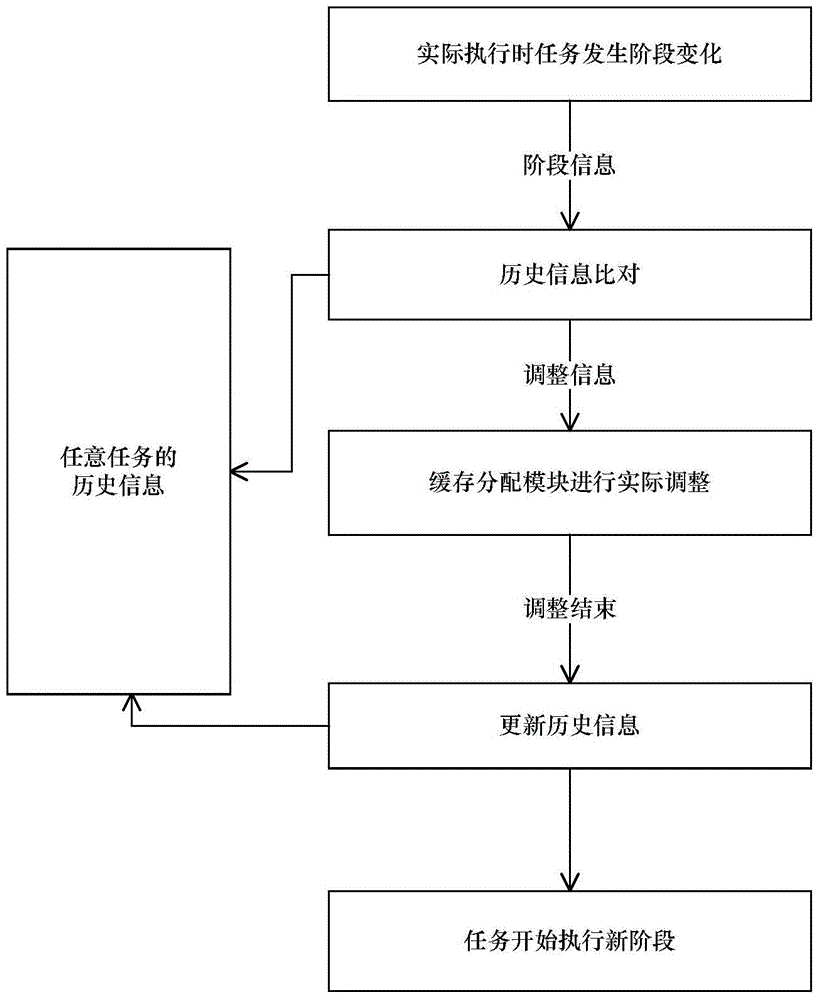
[0026] The present invention will be further described in detail below in conjunction with the accompanying drawings.
[0027] In the present invention, the program code is marked as P, and each program code P generates a task when running, and the task is marked as task. All tasks in the operating system are recorded as T={task 1 , task 2 ,...,task c}, task 1 Indicates the first task, task 2 Indicates the first task, task c Indicates the last task, c indicates the identification number of the task, for the convenience of description, task c Also means any task. The memory access trace sequence of all tasks T in the operating system is denoted as MA T = { MA task 1 , MA task 2 , . . . , MA task ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More