Data analysis method and data analysis system for steel trade industry spot commodity resource
A data analysis and spot technology, applied in the field of data analysis, can solve the problem of low effective data conversion rate and achieve the effect of improving the effective data conversion rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0011] The data analysis method and system for spot resources in the steel trade industry provided by the present invention will be described in detail below in conjunction with the accompanying drawings.
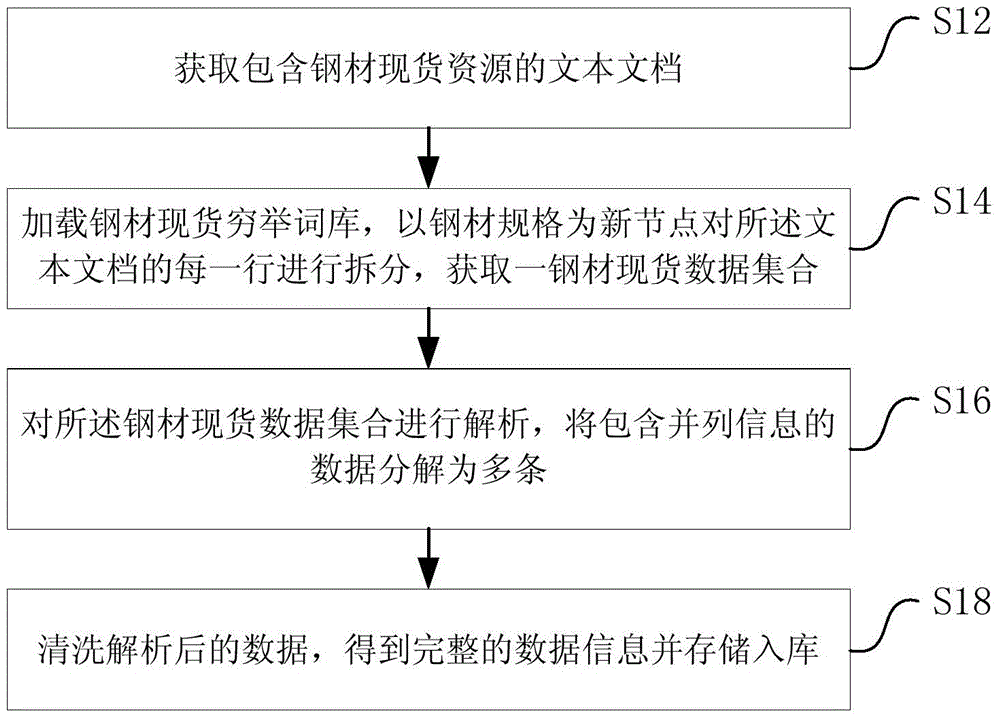
[0012] refer to figure 1 , a schematic flow chart of the data analysis method for spot resources in the steel trade industry described in the present invention. The method includes, S12: Acquiring a text document containing steel spot resources; S14: Loading an exhaustive thesaurus of steel spot resources, splitting each line of the text document with the steel specification as a new node, and obtaining a steel spot data set ; S16: Analyzing the steel spot data set, decomposing the data containing parallel information into multiple pieces; S18: Cleaning the analyzed data, obtaining complete data information and storing it into a warehouse. The method of the present invention will be described in detail below.
[0013] S12: Obtain a text document containing steel spot reso...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com