

Gesture recognition method and gesture recognition device
A gesture recognition and recognition technology, applied in the field of human-computer interaction, can solve the problem of low accuracy and achieve the effect of high accuracy and high precision
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

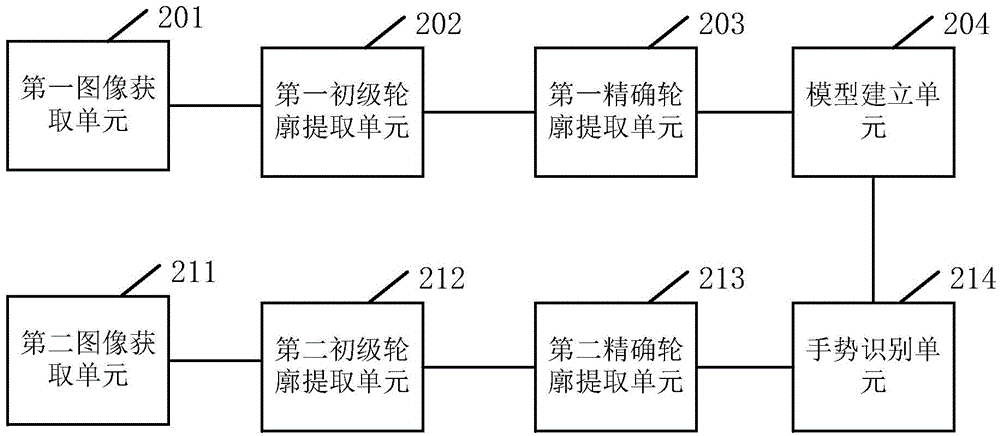
Examples
Embodiment Construction
[0047] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments.
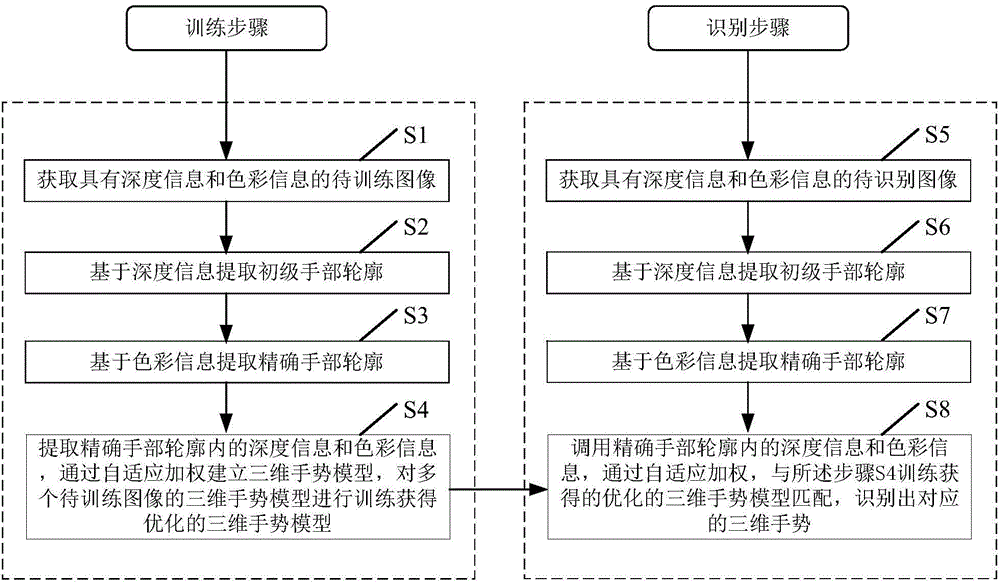
[0048] see figure 1 , is a flowchart of a gesture recognition method according to a preferred embodiment of the present invention. Such as figure 1 As shown, the gesture recognition method provided by the preferred embodiment of the present invention includes a training step and a recognition step:
[0049] Wherein, the training step further includes steps S1-S4.
[0050] First, in step S1, images to be trained with depth information and color information are acquired synchronously. This step can be realized by a depth camera, at least one color camera and a camera fixing assembly. The synchronous control of images collected by the depth camera and the color camera is realized through the controller. In this step, a depth camera may be used in...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More