

Mass web data mining method based on Hadoop
A data mining and massive technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve problems such as management that ignores the processing speed of massive data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0025] The present invention will be further explained with reference to the drawings.
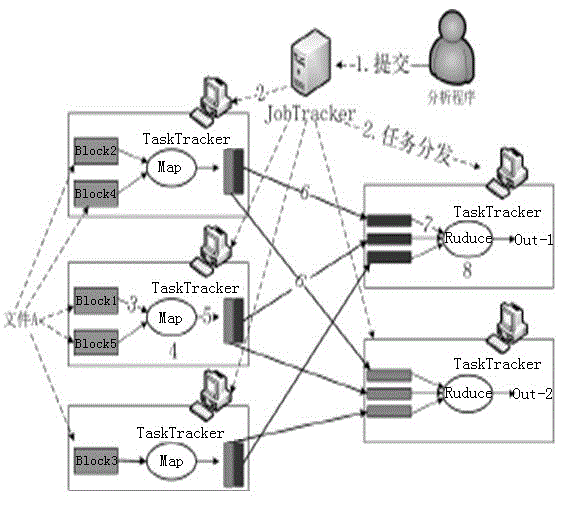
[0026] A method of massive web data mining based on Hadoop:
[0027] Set up a data mining environment: The Hadoop platform consists of 6 Proud PR2310N servers, of which the NameNode in HDFS and the JobTracker in MapReduce are served by one server, and the remaining 5 serve as computing nodes and data storage nodes. The test data set comes from the server log of the web server room of Antfang Software. The test program is developed using the Eclipse for Java developer platform;
[0028] ① Data mining job submission: users submit jobs written based on the MapReduce programming specification;
[0029] ②Task assignment: Calculate the required number of Map tasks M and Reduce tasks R, and assign the Map tasks to the task execution node TaskTracker; at the same time assign the corresponding TaskTracker to execute the Reduce task; the specific process is: the job control node JobTracker according to the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More