

Distributed-structure-based big data clustering method and device
A distributed structure and clustering method technology, applied in the field of data mining, can solve problems such as hard division of intervals, no consideration of the different effects of big data data points on knowledge discovery tasks, uneven data distribution, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


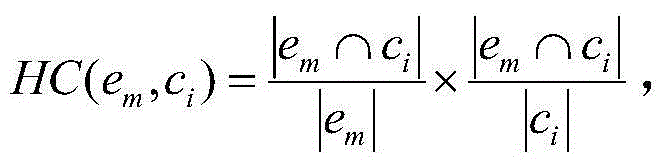
Examples
Embodiment Construction
[0098] The technical solutions of the present invention will be clearly and completely described below in conjunction with the accompanying drawings of the present invention. Reference will now be made in detail to the exemplary embodiments, examples of which are illustrated in the accompanying drawings. When the following description refers to the accompanying drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. The implementations described in the following exemplary examples do not represent all implementations consistent with the present invention. Rather, they are merely examples of apparatuses and methods consistent with aspects of the invention as recited in the appended claims.
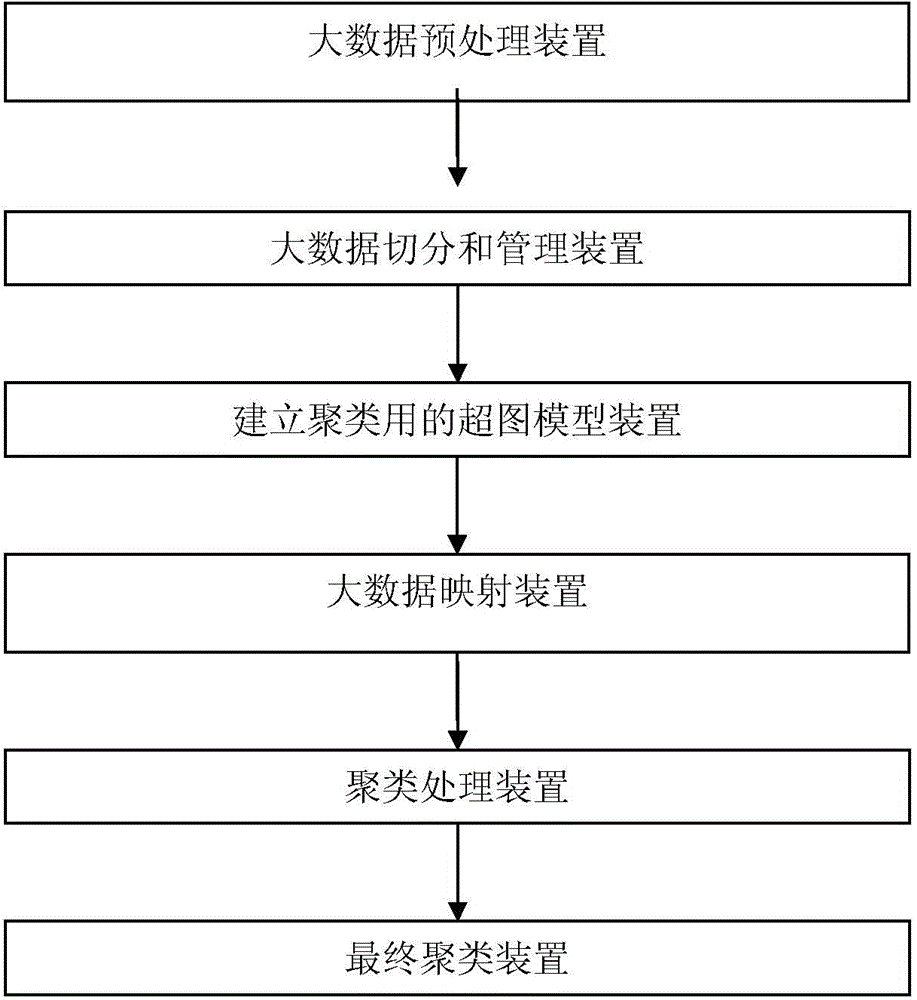
[0099] see figure 1 , a kind of big data clustering method based on distributed structure that the present invention proposes, comprises:
[0100] Step S100, big data preprocessing, cleaning up the data in the real world by fill...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More