Mobile application download prediction method based on cluster
A forecasting method, technology for mobile applications, used in data processing applications, business, instrumentation, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
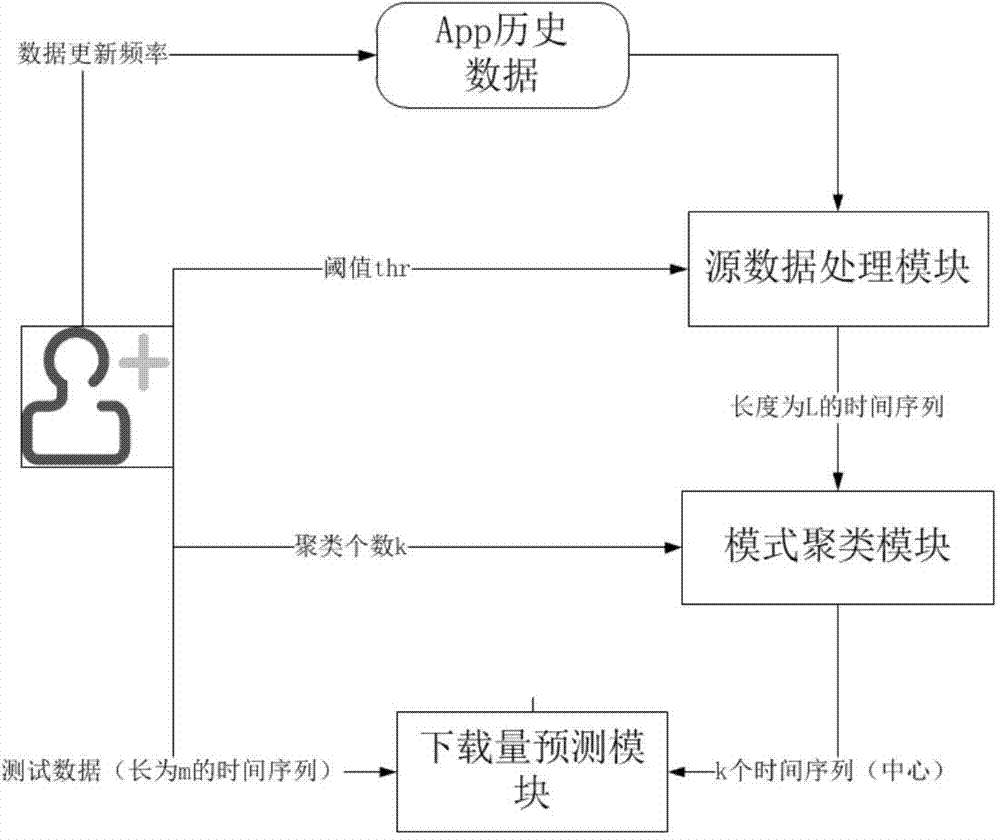
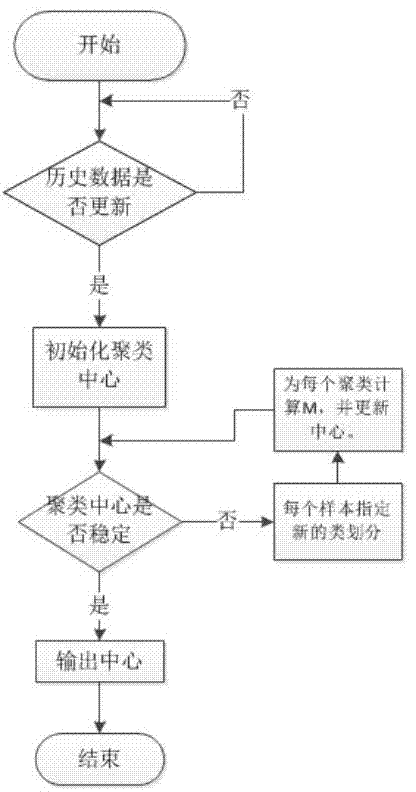
[0043] Refer to attached picture.
[0044] The method for predicting download volume of the present invention comprises the following steps:
[0045] 1) Obtain the historical data of the app to be predicted from the background data, including the download amount of the app within the known m days;
[0046] 2) Source data processing: process the data in step 1) to generate a discrete time series x of length L to represent the download curve of each app, so far the download curves of all apps form a discrete time series training data set, specifically Include the following steps:
[0047] Described step 2) specifically comprises the following steps:
[0048] (1) The download threshold thr is given; thr is an artificially specified parameter, and the default thr=0.1. On the basis of thr determination, the L of the entire training data set can be calculated 1 and L 2 , generally adjust thr so that L 1 +L 2 Not less than 2 / 3 of the length of the original sequence.
[0049]...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



