

A Freshness Sensitive Big Data Summary Information Maintenance and Aggregated Value Query Method
An information maintenance and big data technology, applied in database design/maintenance, digital data processing, structured data retrieval, etc. Support real-time query requests and other issues to achieve the effect of improving real-time processing performance and improving real-time query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example
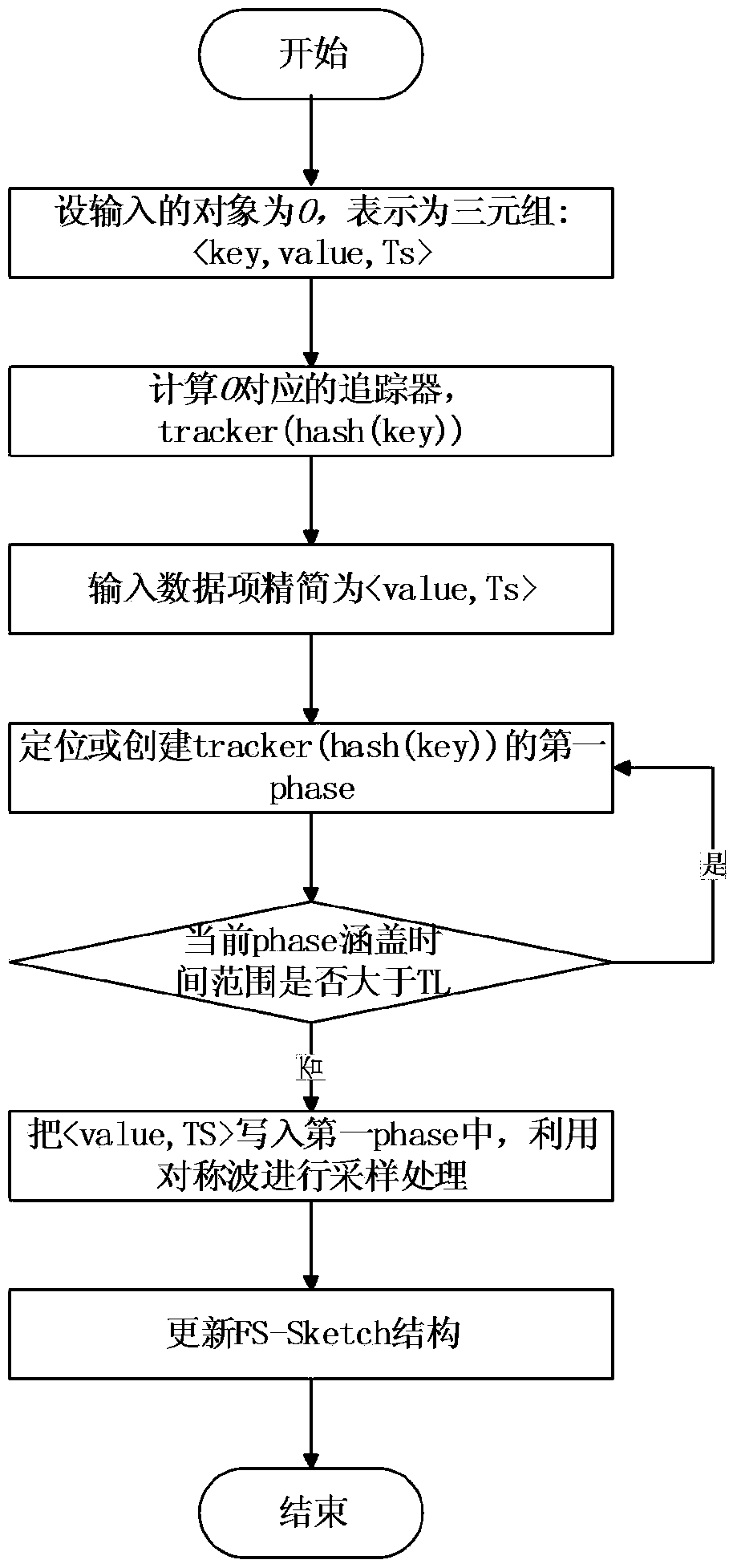
[0054] In order to make the above objects, features and advantages of the present invention more obvious and understandable, the present invention will be further described below through specific examples. Example: time interval aggregation query in streaming big data environment.
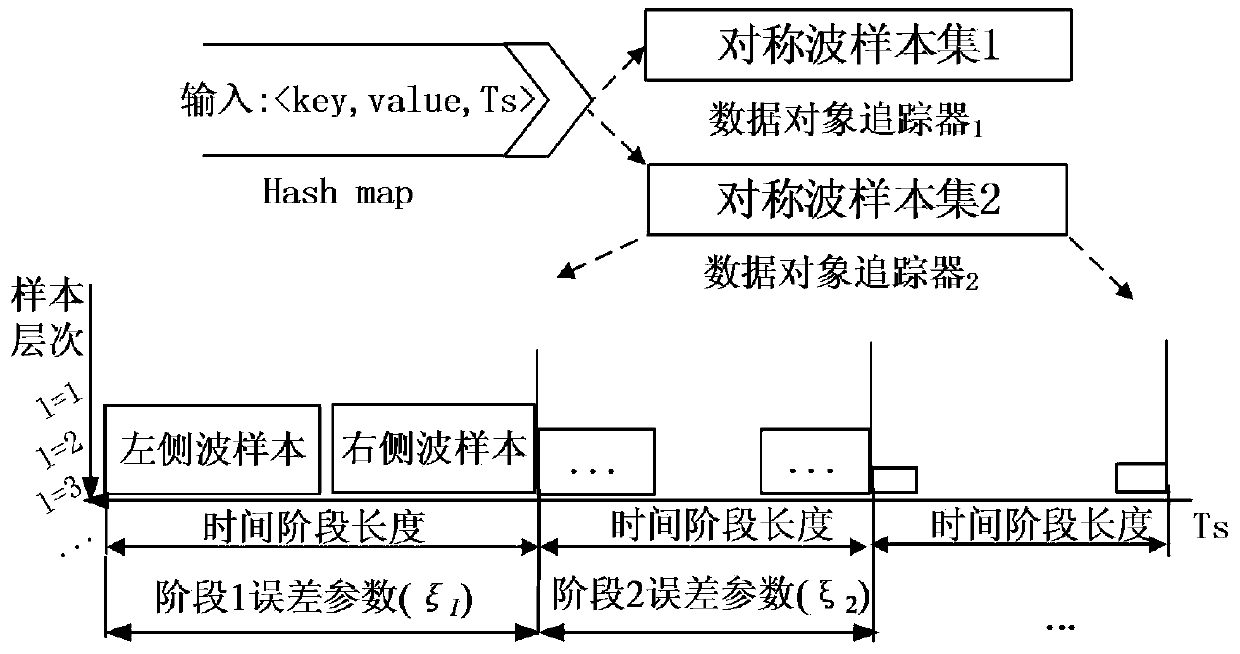
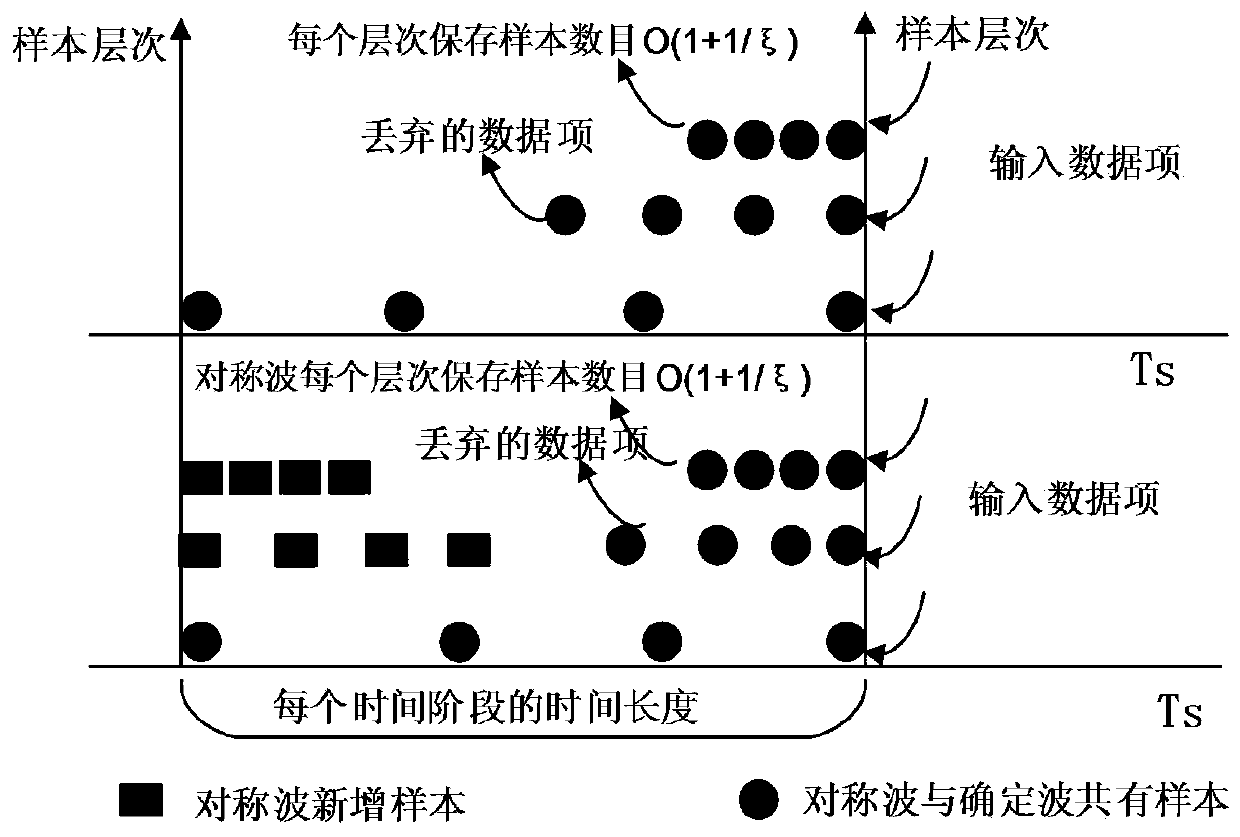
[0055] In this example, FS-Sketch is applied in the streaming big data environment, as the front-end receiver of the streaming data, it completes the data reception in O(1) time and maintains the summary data. FS-Sketch can effectively support the statistical query of TRAQ type proposed by the present invention. FS-Sketch is generally deployed in the memory structure, which can further serialize the data in FS-Sketch to files for persistent storage. Based on FS-Sketch, data distribution support for streaming big data can be effectively obtained, providing a basis for building high-level index structures and summary data.
[0056] 2. Experimental data and conclusion
[0057] The experiment accord...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More