

Parallel clustering method for processing large geographical grid data
A technology of raster data and clustering method, applied in geographic information database, electronic digital data processing, structured data retrieval, etc., can solve the problem of system inoperability and operating efficiency, and achieve the effect of small communication cost
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
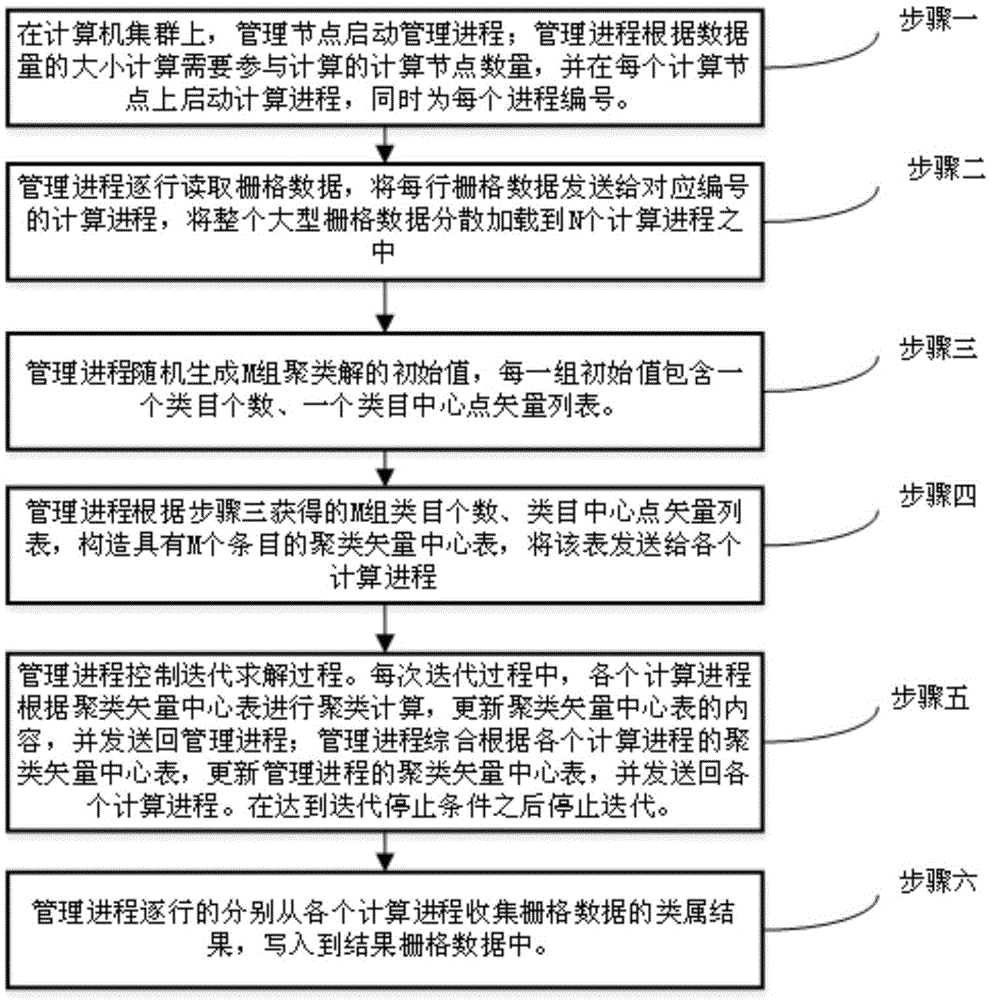
[0048] Specific implementation mode one: combine figure 1 A parallel clustering method for processing large geographic grid data in this embodiment is specifically prepared according to the following steps:
[0049] Step 1. On the computer cluster, use the management node to start the management process. The management process calculates the number of computing nodes participating in the calculation according to the large geographic raster data volume, and starts the computing process on each computing node, and at the same time numbers each computing process ; Among them, a computer cluster includes 5 to 100 computers connected to the Internet, choose a computer in the computer cluster to act as a management node, and other nodes in the computer cluster except the management node serve as computing nodes; large-scale geographic raster data The amount of data is greater than 1000M;
[0050] Step 2: The management process reads the large geographic grid data row by row, loads...
specific Embodiment approach 2
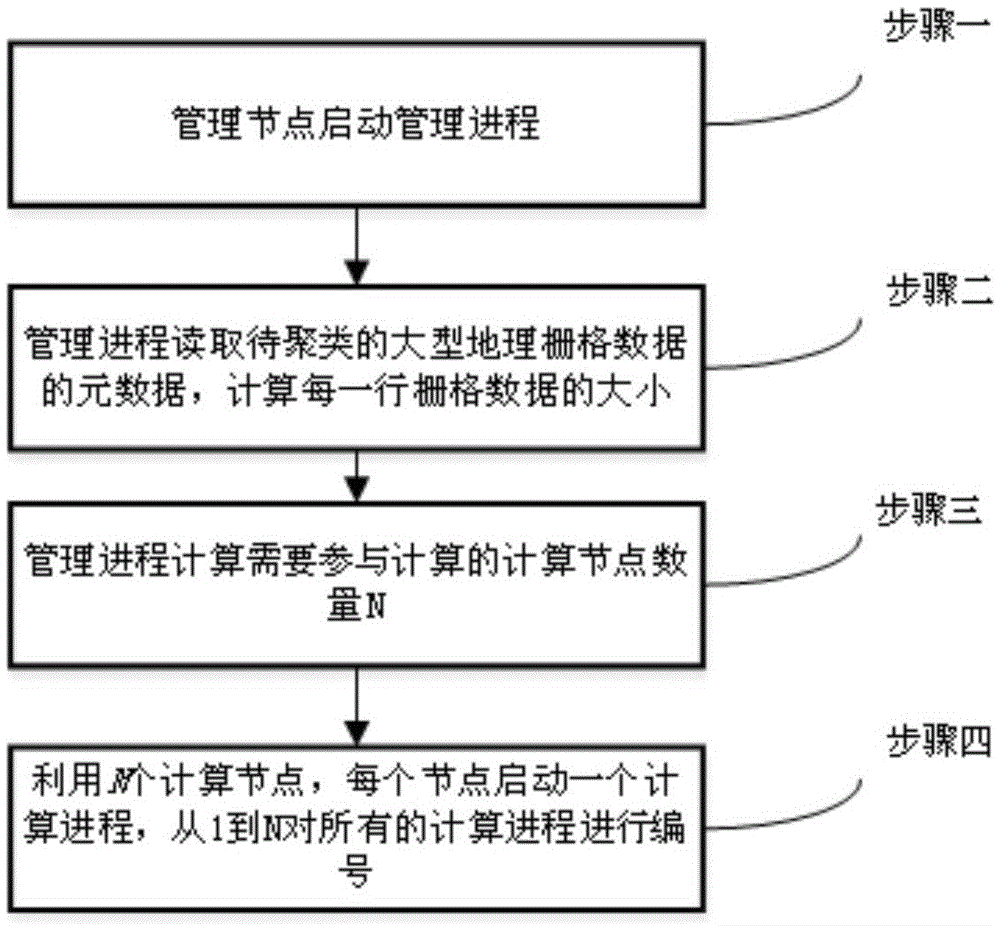
[0072] Specific embodiment 2: The difference between this embodiment and specific embodiment 1 is that in step 1, on the computer cluster, the management node is used to start the management process, and the management process calculates the number of computing nodes participating in the calculation according to the amount of large-scale geographic raster data, and Start the calculation process on each calculation node, and number specific steps for each calculation process (the processing flow of this step is as follows figure 2 shown) as follows:
[0073] (1) The management node starts the management process;
[0074] (2) The management process reads the row number RowNum, the column number ColNum, and the total file size SumSize of the large-scale geographic raster data to be clustered; the calculation method of the size RowSize of each row of the large-scale geographic raster data to be clustered is:
[0075] RowSize=SumSize / ColNum;
[0076] (3) The management process c...
specific Embodiment approach 3
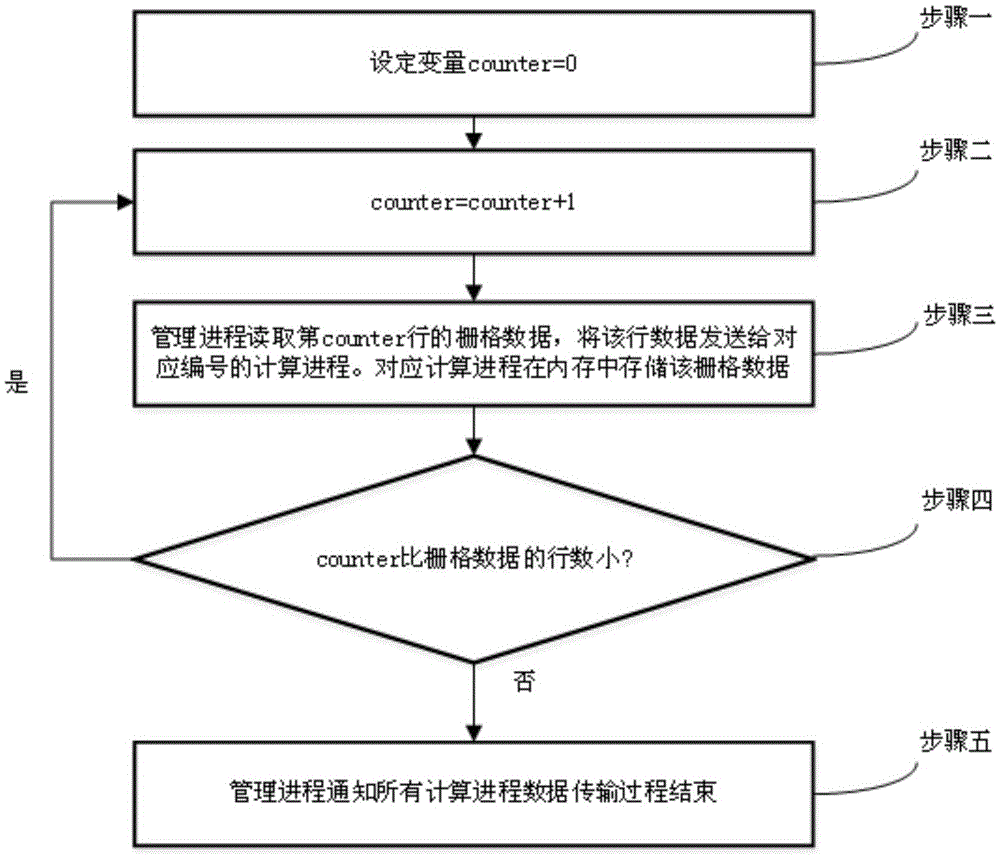
[0083] Specific embodiment three: the difference between this embodiment and specific embodiment one or two is that in step two, the management process reads the large-scale geographic grid data line by line, and loads the entire large-scale geographic grid data into N computing processes in a distributed manner. Each row of large-scale geographic raster data is sent to the calculation process with the corresponding number as ID. The specific steps are as follows (such as image 3 ):
[0084] (1) variable counter=0 in the setting management process;
[0085] (2) counter=counter+1;
[0086] (3) The management process reads the data in the counter row in the large geographic raster data, and sends the data in the counter row in the large geographic raster data to the calculation process whose number is ID corresponding to the data in the counter row. The calculation process is stored in the counter row of the large geographic raster data in the memory space of the calculation ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More