

A Log Clustering Method Based on Graph Structure
A clustering method and graph structure technology, applied in the field of text clustering, can solve the problems of the number of log categories cannot be automatically identified, the amount of calculation is large, and the number of categories cannot be guaranteed by clustering.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0043] The specific implementation manners of the present invention will be further described in detail below in conjunction with the accompanying drawings.
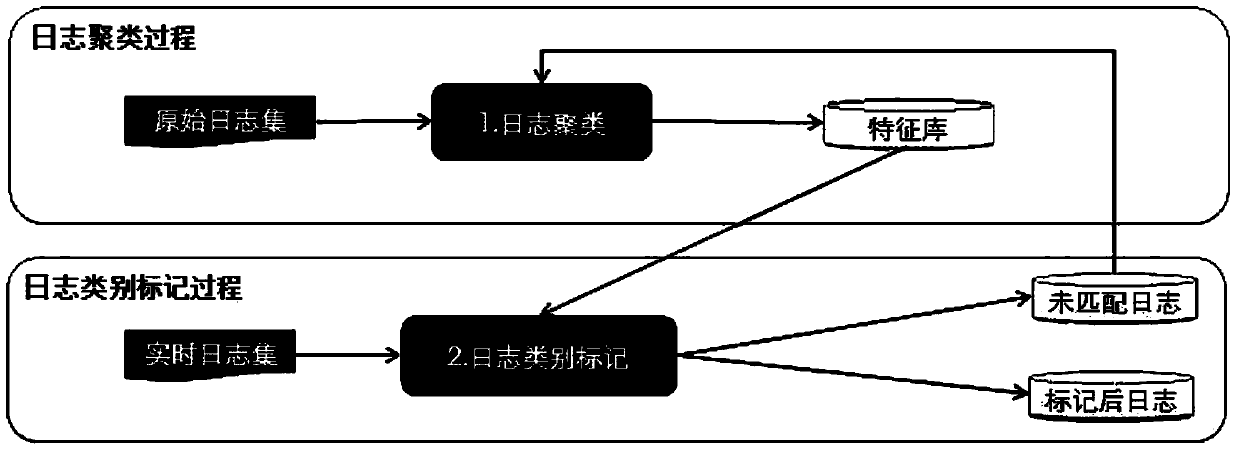
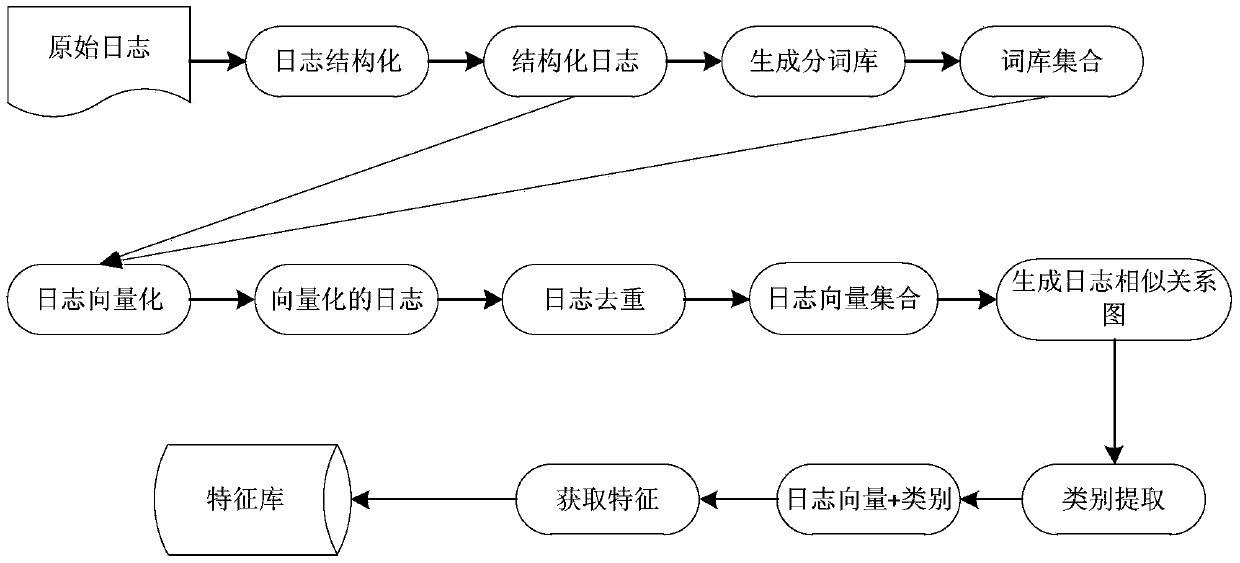
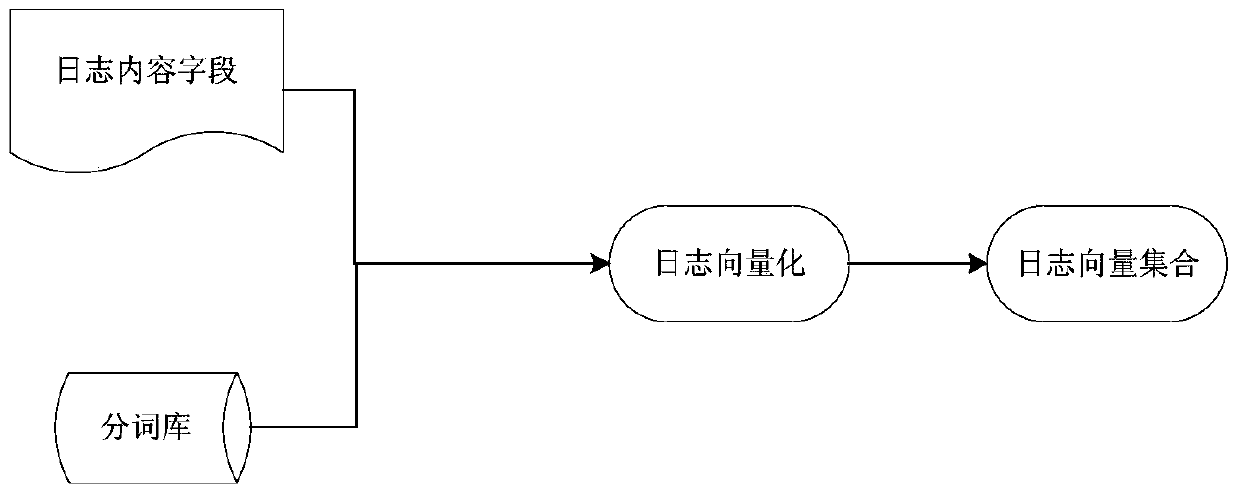
[0044] Such as figure 1 As shown, a log clustering method based on a graph structure, the method includes: based on text word segmentation, vector similarity and clustering the logs of the largest connected subgraph to obtain a feature library; and according to the category features in the feature library Massive logs are categorized.
[0045] 1. Obtaining the feature library includes the following steps:
[0046] (1) Structuring the original log to generate structured log data; including: inputting the original log, structuring the semi-structured original log by columns, and outputting the structured log data.
[0047] For example, the form of Linux syslog logs is shown in Table 1.1, and the columns are structured into fields such as Timestamp, Level, Source, and Message. The original syslog becomes the format in Ta...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More