

Mass vector data partition method and system based on Hadoop
A vector data and map function technology, applied in the field of spatial big data, can solve problems such as reduced task execution efficiency, uneven distribution of Reduce load, and inability to guarantee the consistency of spatial index results, improve storage and computing efficiency, and ensure spatial distribution. Features, the effect of improving the efficiency of spatial indexing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0045] Embodiments of the present invention will be described in detail below with reference to the accompanying drawings.
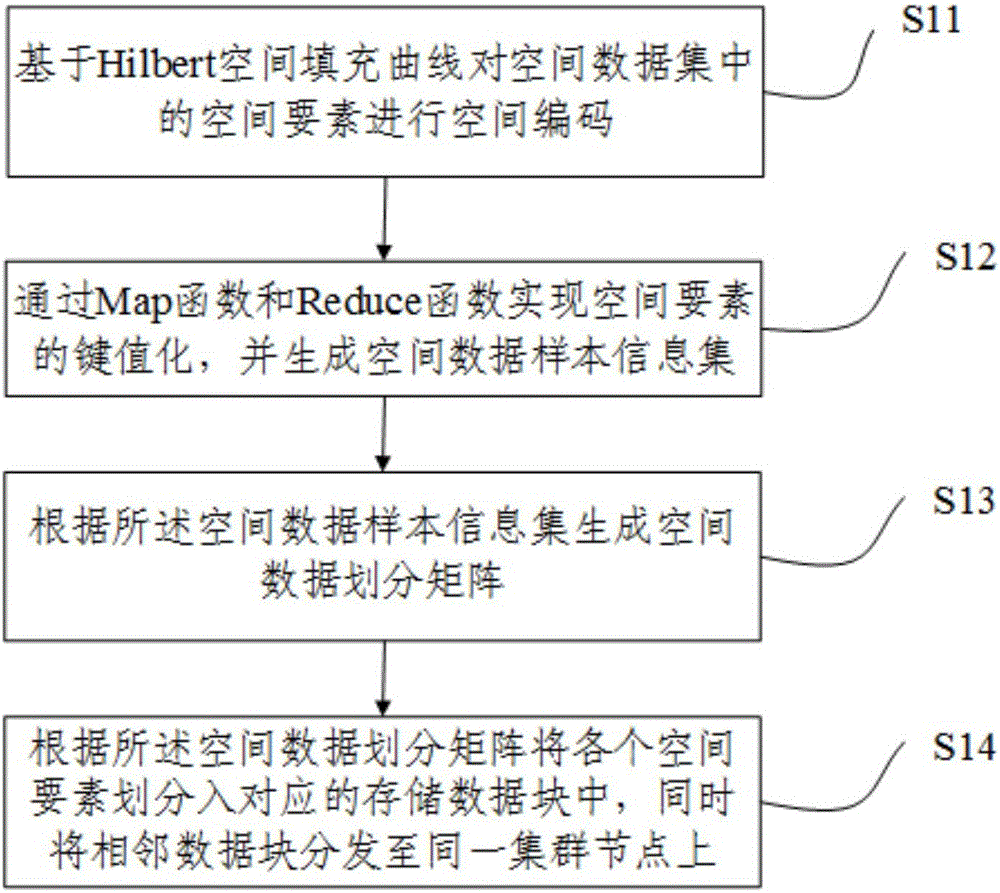
[0046] figure 1It shows a schematic flowchart of a method for dividing massive vector data based on Hadoop according to an embodiment of the present invention. Such as figure 1 As shown, the Hadoop-based massive vector data division method of this embodiment includes:
[0047] S11: spatially encode the spatial elements in the spatial dataset based on the Hilbert space-filling curve;
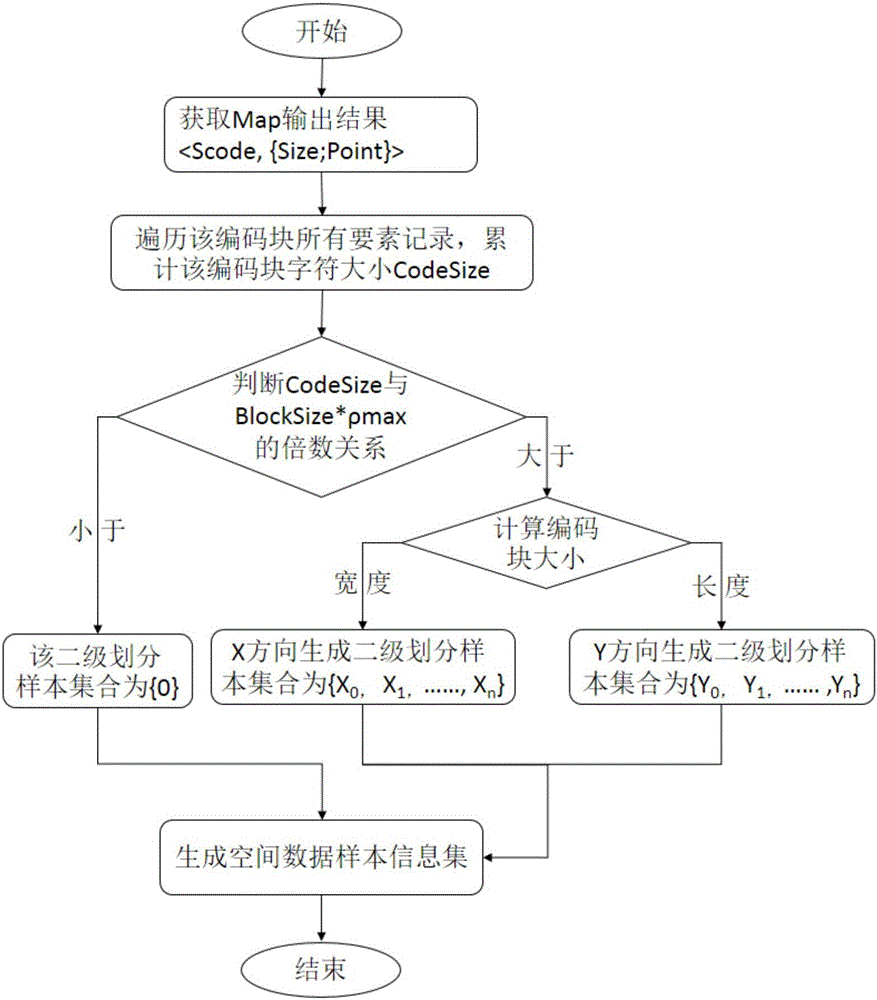
[0048] S12: Realize key-value of spatial elements through Map function and Reduce function, and generate spatial data sample information set;
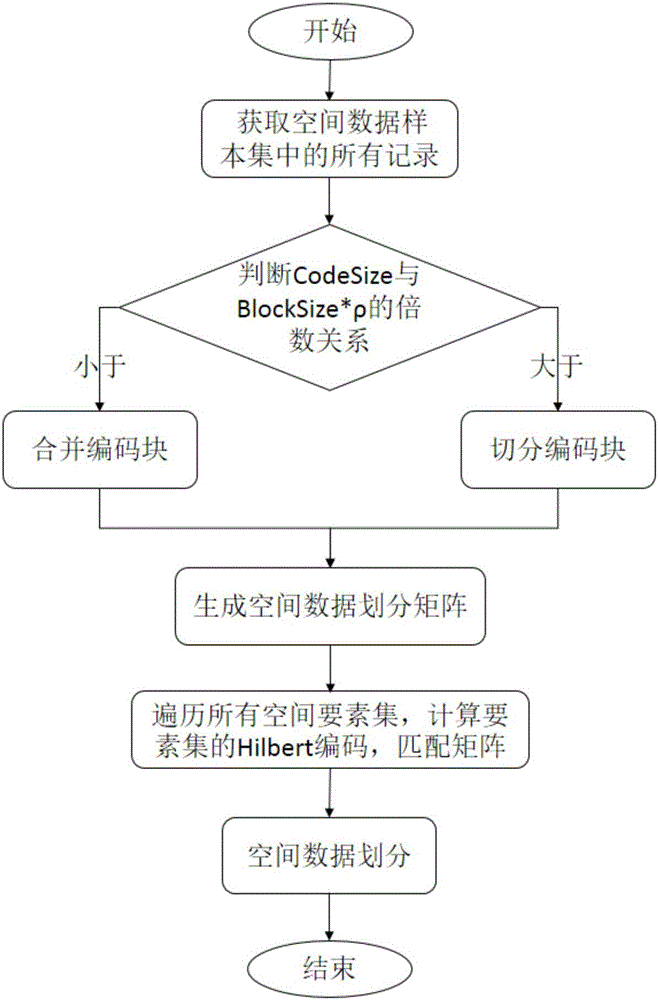
[0049] S13: Generate a spatial data division matrix according to the spatial data sample information set;
[0050] S14: Divide each spatial element into corresponding storage data blocks according to the spatial data division matrix, and distribute adjacent data blocks to the same cluster node at the same time.
[0051] In the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More