

Data clustering method for rapidly determining clustering center
A clustering method and clustering center technology, applied in the field of data analysis, can solve the problems of manual determination of clustering centers, small parameter dependence, low clustering accuracy, etc., achieve good applicability and scalability, and reduce parameters Sensitivity issues, good clustering effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
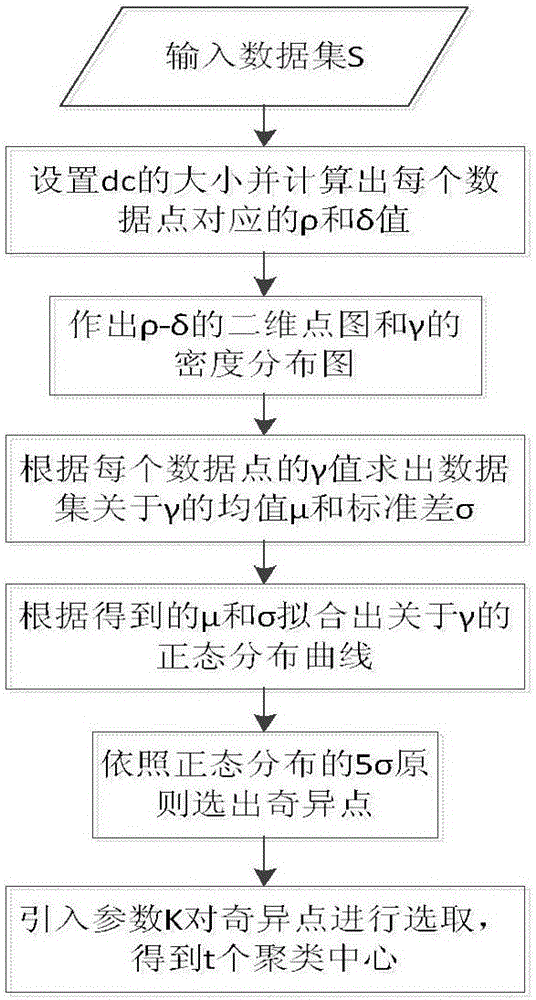
[0040] The present invention will be further described below in conjunction with the accompanying drawings.
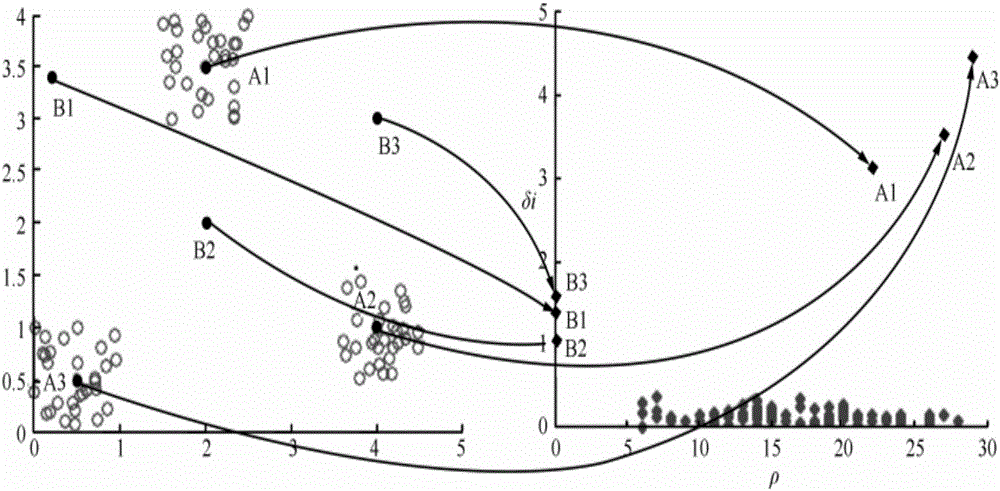
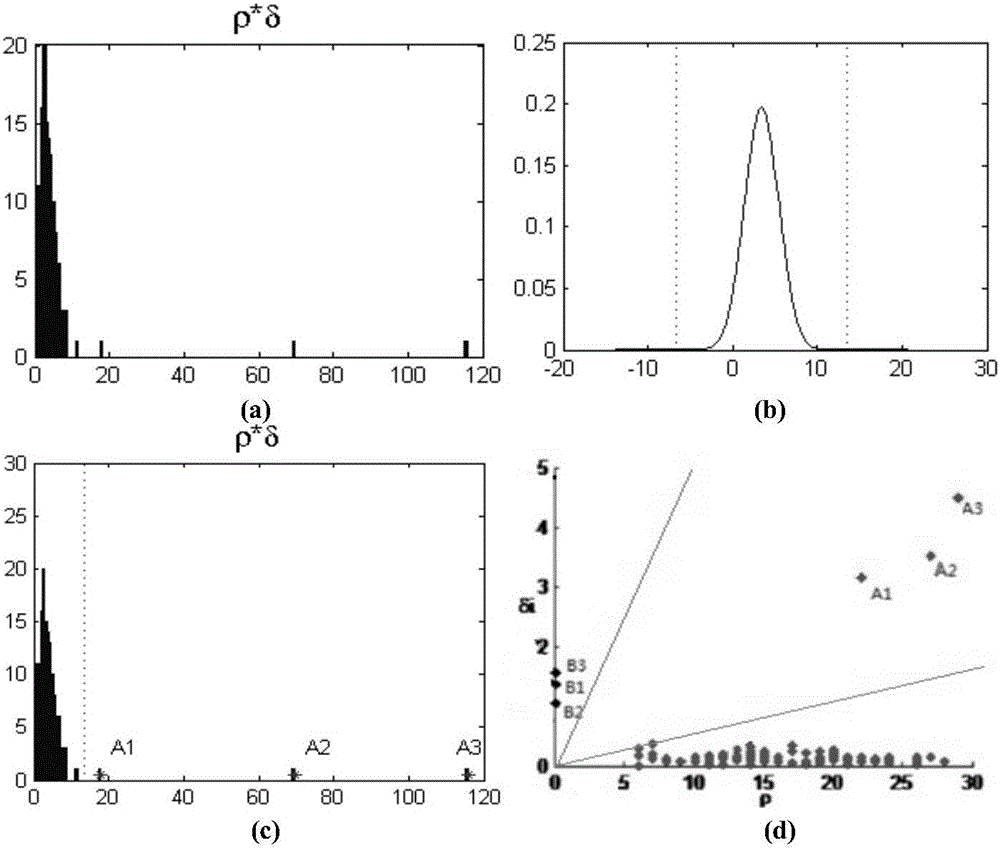
[0041] refer to Figure 1 to Figure 5 , a clustering method for quickly determining cluster centers, including the following steps:
[0042] 1) Read the original data set, perform dominant analysis on the data set, select the corresponding distance calculation method through the dominant analysis, and use this distance calculation method to obtain the distance matrix of the entire data set. The process is as follows:
[0043] 1.1 If the input data set has p-dimensional numerical attribute data and q-dimensional categorical attribute data, then by comparing the size of p and q, the data set is divided into numerical dominant data set and classification dominant data set.
[0044] 1.2 According to the results obtained by the dominant analysis, the corresponding distance calculation formula is used to calculate the data set, and the similarity distance matrix of the data...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More