

Three-decision unbalanced data oversampling method based on Spark big data platform
A big data platform and oversampling technology, applied in the direction of instruments, character and pattern recognition, computer components, etc., can solve the problems of reducing efficiency, achieve the effect of solving classification problems, improving performance, and ensuring recognition rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] The technical solutions in the embodiments of the present invention will be described clearly and in detail below with reference to the drawings in the embodiments of the present invention. The described embodiments are only some of the embodiments of the invention.
[0036] The technical scheme that the present invention solves the problems of the technologies described above is:
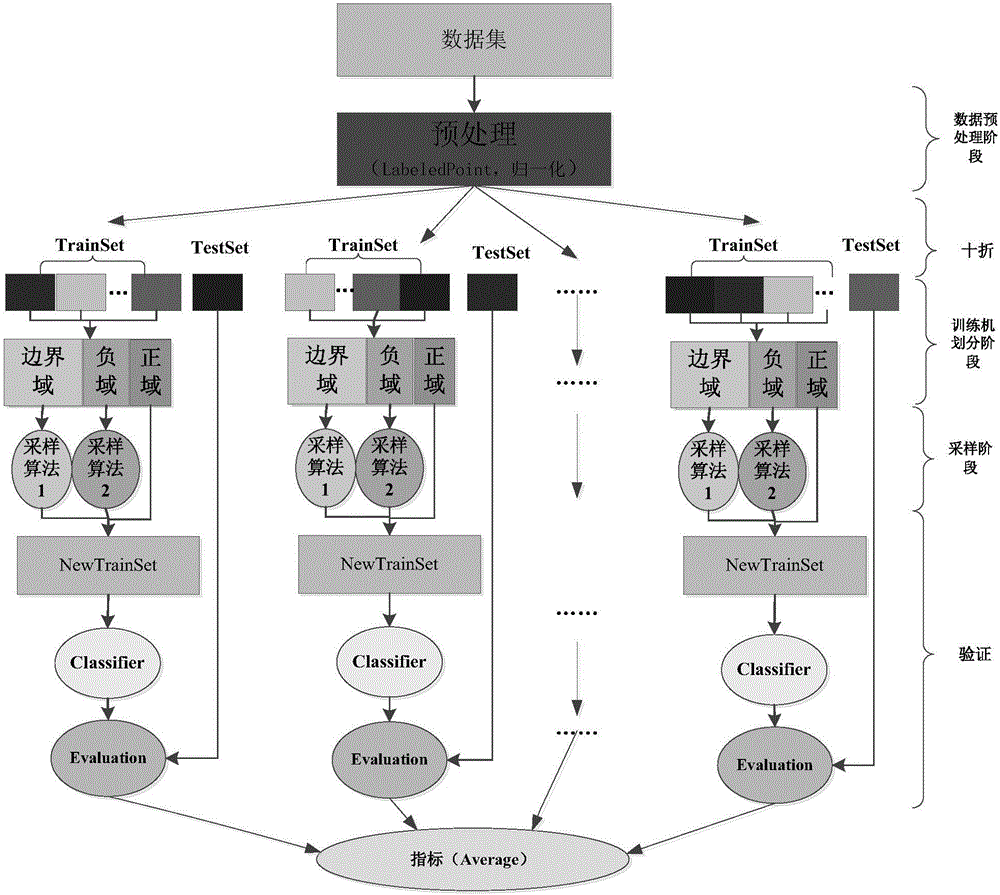
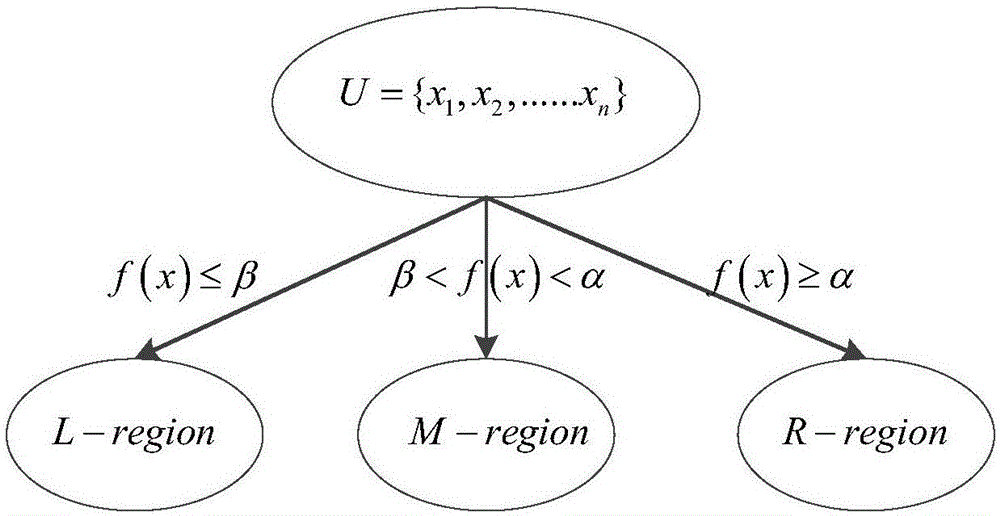
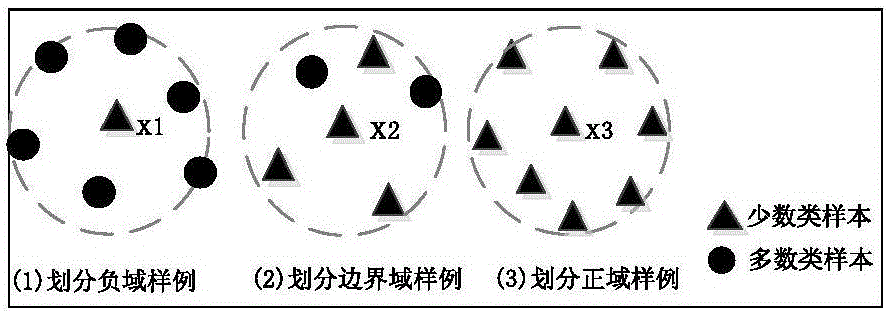
[0037] Using the three-branch decision imbalance data oversampling method based on the Spark big data platform includes the following steps:
[0038] Obtain the sample set that needs to be sampled from the system, and HDFS automatically performs distributed storage, and then uses Spark to perform data transformation on the entire sample to obtain a normalized sample set in LabeledPoint format . Specific steps: first create a SparkContext object, and then use its textFile(URL) function to create a distributed dataset RDD. Once created, this distributed dataset can be operated in parallel; se...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More