

Spark-based parallel random label subset multi-label text classification method
A text classification and multi-label technology, which is applied in the field of parallel random label subset multi-label text classification algorithm, can solve problems such as inability to run downtime, memory overflow, long time, etc., to solve text classification problems, improve accuracy, reduce The effect of study time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
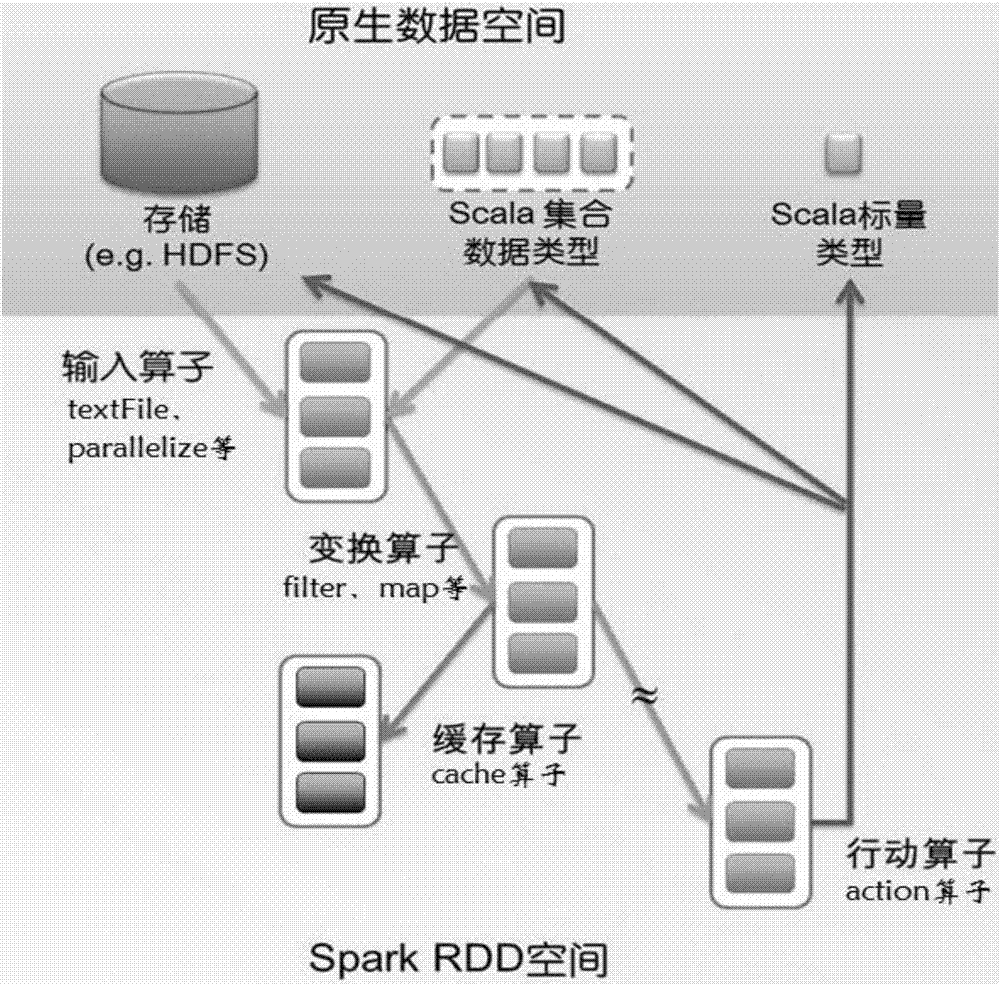
[0037] The technical solutions in the embodiments of the present invention will be described clearly and in detail below with reference to the drawings in the embodiments of the present invention. The described embodiments are only some of the embodiments of the invention.
[0038] The technical scheme that the present invention solves the problems of the technologies described above is:
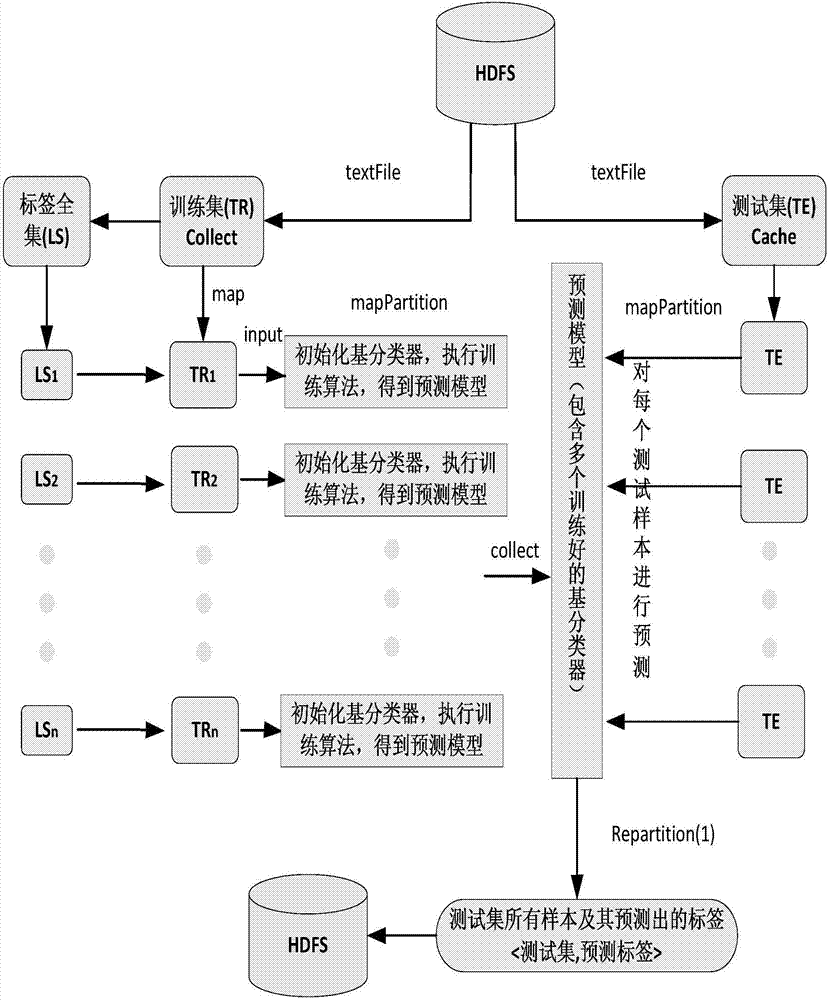
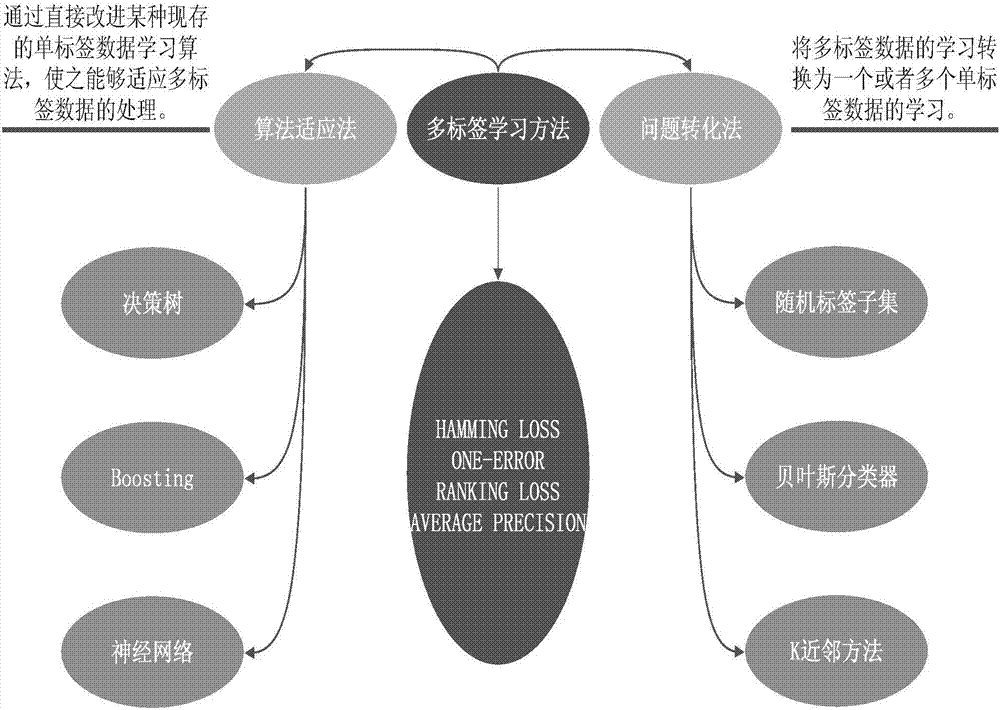
[0039] The parallelized multi-label text classification method based on the spark big data platform provided by the present invention-random label subset method includes the following three processes:
[0040] 1. Construct a multi-label data set according to the characteristics of the random label subset algorithm;
[0041] In order to reflect the efficiency of the parallel algorithm and the classification effect of the random label subset method, the text data set EUR-Lex (directory codes) was selected from the official website of mulan from the two perspectives of the number of labels and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More