OWLHorst rule distributed type parallel reasoning algorithm in combination with Spark platform
A distributed and rules-based technology, applied in the field of the Semantic Web, can solve the problems of time-consuming startup, whether the rules can be activated or not, multiple redundant calculations, etc., to achieve the effect of reducing overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0015] The present invention will be further explained below in conjunction with the accompanying drawings and specific embodiments.
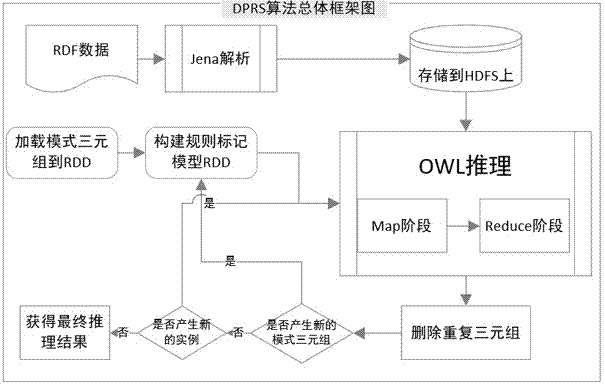
[0016] The present invention provides a kind of OWL Horst rule distributed parallel reasoning algorithm combined with Spark platform, and it comprises the following steps: DPRS algorithm mainly comprises the following several steps:
[0017] 1. Load pattern triplet set P j _RDD, O k _RDD and Rule m _linkvar_RDD and broadcast.
[0018] 2. Build a rule tag model Flag_Rule m and broadcast.
[0019] 3. To Flag_Rule m The rules in parallel execute the parallel inference of OWL Horst rules and output intermediate results.
[0020] 4. Remove duplicate triplets.
[0021] 5. If a new pattern triplet data is generated, then skip to 2, if a new instance triplet data is generated, then skip to 3, otherwise the algorithm ends.
[0022] Whole frame diagram of the present invention sees figure 1 .
[0023] Definition 1. (SchemaTriple) means that the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com