Text similarity distinguishing method and apparatus
A technology of text similarity and discrimination method, applied in the Internet field, can solve the problems of high misjudgment rate, easy to cause misjudgment, and heavy workload.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
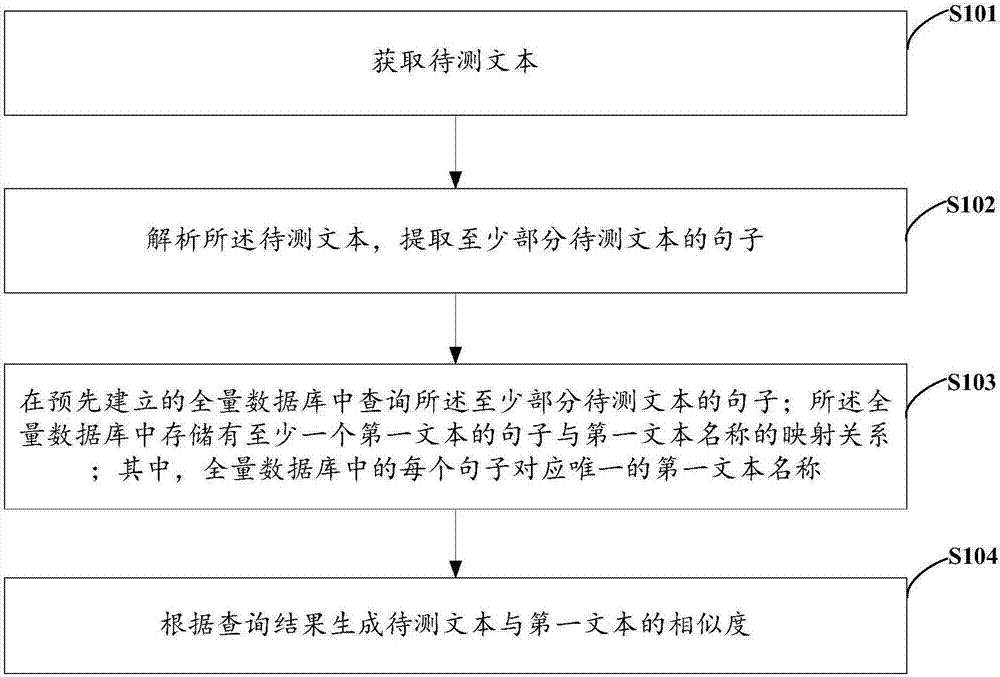
[0101] The present invention provides a method for judging text similarity, such as figure 1 As shown, the method at least includes the following steps:
[0102] S101: Acquire the text to be tested.
[0103] Text refers to the form of expression of written language. From a literary perspective, it is usually a sentence or a combination of multiple sentences with a complete and systematic meaning (Message). A text can be a sentence (Sentence), a paragraph (Paragraph) or a chapter (Discourse). Broad "text": any utterance fixed by writing. Narrow sense "text": a literary entity composed of language and characters, referring to "work", which constitutes an independent and self-contained system relative to the author and the world.
[0104] Text is mainly used to record and store text information, rather than images, sounds and formatted data. The extensions of common text documents are: .txt, .doc., .docx, .wps, etc.
[0105] The text to be tested in this application can contain one or...
Embodiment 2
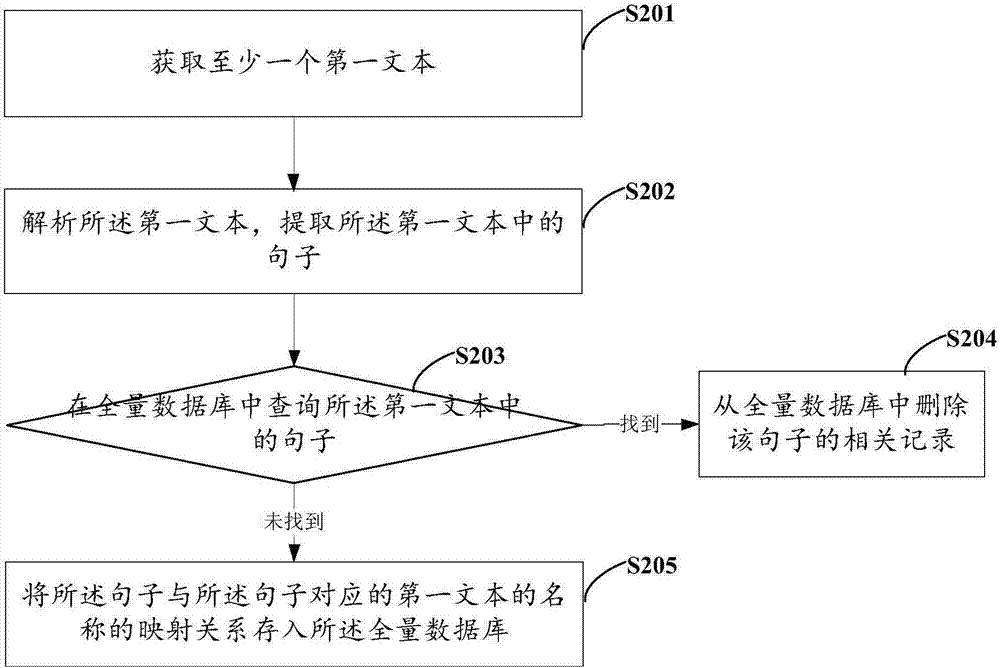
[0182] Such as Figure 5 As shown, the present invention provides another method for judging text similarity, including:
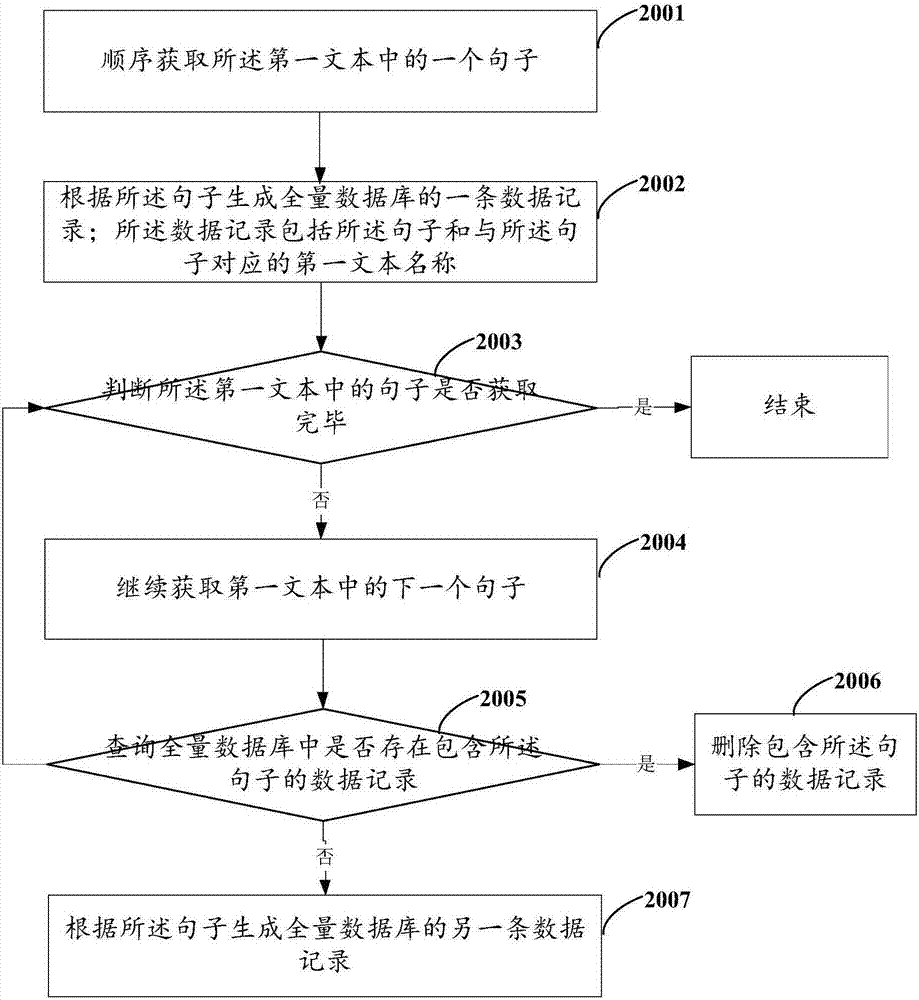
[0183] S501: Write data to the full database; the full database is used to store the mapping relationship between at least one sentence of the first text and the first text name; wherein each sentence in the full database corresponds to a unique first text name.
[0184] The writing of data to the full database includes:
[0185] Obtain at least one first text;
[0186] Parse the first text, and extract sentences in the first text;
[0187] Query the sentence in the first text in the full database;
[0188] If found, delete the relevant record of the sentence from the full database;
[0189] If not found, the mapping relationship between the sentence and the name of the first text corresponding to the sentence is stored in the full database.
[0190] S502: Write data to the single database of each first text.
[0191] The writing data into the single database of each fi...
Embodiment 3
[0225] According to the embodiment of the present invention, there is also provided a device for implementing the above-mentioned text similarity judgment method, Image 6 Is a schematic diagram of a text similarity judging device according to an embodiment of the present invention, such as Image 6 As shown, the device includes:
[0226] The test text obtaining module 10 is used to obtain the test text.
[0227] The text sentence extraction module 20 to be tested is used to parse the text to be tested and extract at least part of the sentences of the text to be tested.
[0228] The query module 30 is used to query the sentence of the at least part of the text to be tested in a pre-established full database; the full database stores at least one mapping relationship between a sentence of the first text and the name of the first text; wherein the full database Each sentence in the database corresponds to a unique first text name.
[0229] The similarity discrimination module 40 is used...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com