

Method and system of speech recognition based on matching model secondary identification
A speech recognition and secondary recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of speech recognition accuracy drop and affect human-computer interaction experience, so as to ensure accuracy, improve user experience, and recognize accurately high degree of effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
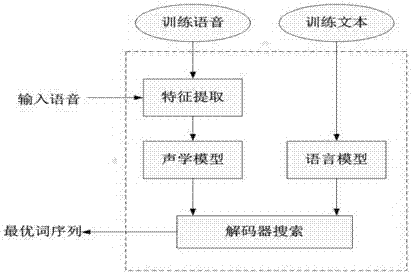
[0027] Such as figure 1 As shown, the present invention is based on the speech recognition method of matching model secondary recognition, comprises the following steps:
[0028] (10) Speech processing: perform preprocessing and feature extraction on the speech input by the user;
[0029] In the prior art, a common speech recognition model modeling process includes the following steps:
[0030] (1) Obtain a sufficient amount of labeled training data, extract the Mel domain cepstral coefficient (MFCC) of each training sample as the acoustic feature; sort out the labeled information of the training data to extract the text feature vector
[0031] (2) Input the acoustic feature vectors of the training samples into the deep neural network (DNN) composed of restricted Boltzmann machine (RBM) stacks, and use the GMM-HMM baseline system to obtain the output layer of the neural network through forced alignment. The error signal of the output layer is obtained by comparing the networ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More