

Distributed density peak value clustering algorithm based on z value
A density peak and clustering algorithm technology, applied in the field of big data processing, can solve problems such as increased computing overhead, large randomness of seed objects, and unbalanced load of computer clusters
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

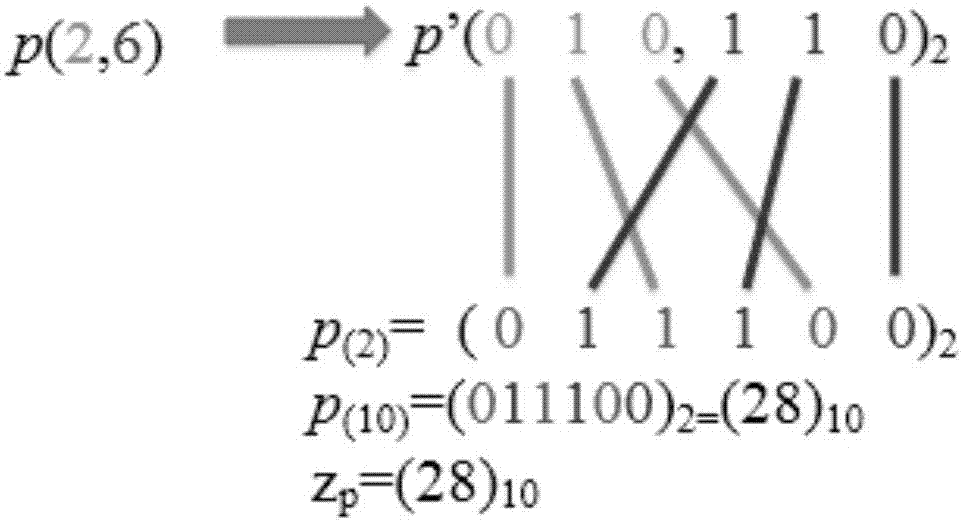
Examples
Embodiment Construction
[0037] The specific embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings.
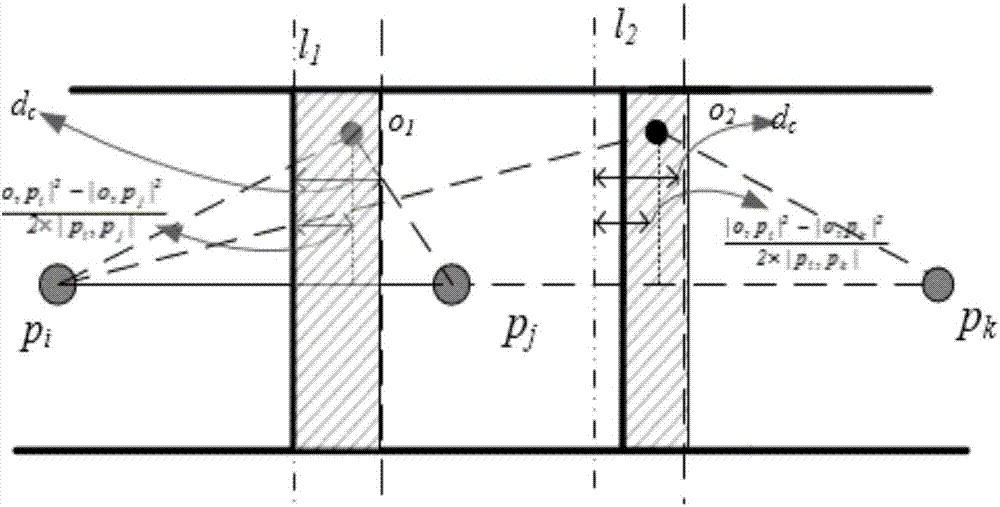
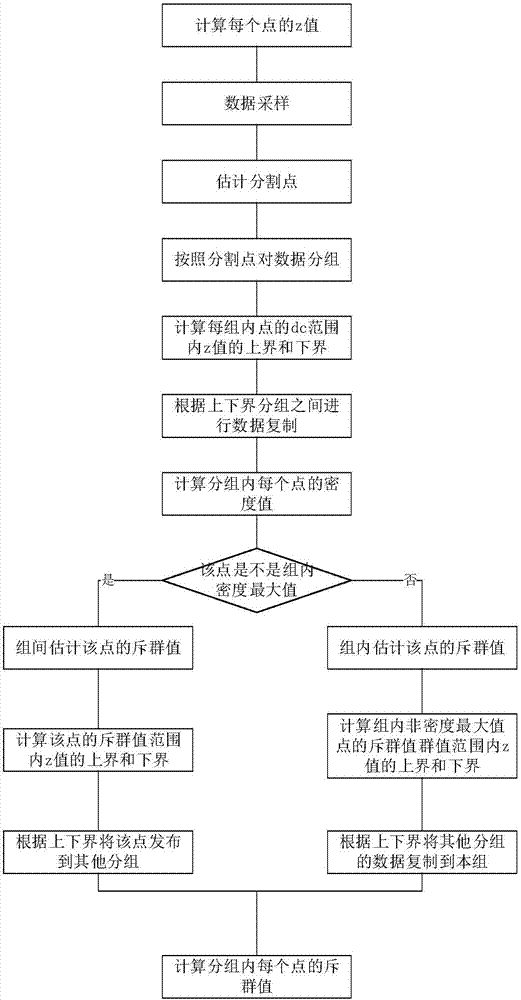
[0038] refer to Figure 1 ~ Figure 4 , using the z-value-based density peak clustering method to cluster high-dimensional big data, including the following steps:
[0039] Step 1: Data set selection.
[0040] This implementation uses three data sets of KDD'99_10%, FCoverType and facial. The KDD’99_10% data set is a data set composed of 494,021 data points with 42 attributes such as connection time and transmission data volume. This implementation intercepts 34 real-valued attributes. FCoverType is a dataset consisting of 581,012 data points of 54 attributes including latitude and longitude. The Facial dataset is a dataset consisting of 27,936 face images, each of which includes 300 pixels.
[0041] Step 2: Construction of software and hardware environment.
[0042] Step 2.1: Build a hardware computing platform.
[0043] Under the Ubu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More