

Unstructured view missing data classification method
An unstructured and missing data technology, applied in unstructured text data retrieval, text database clustering/classification, electronic digital data processing, etc., to achieve high efficiency, low complexity, and improve classification efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

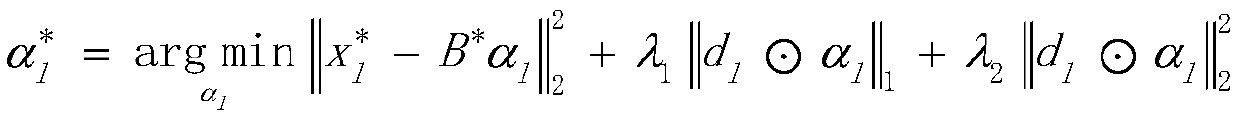
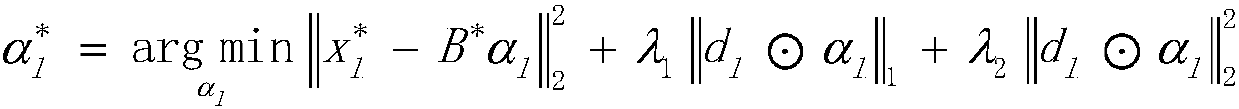
Examples
Embodiment Construction
[0054] The present invention will be described in further detail below in conjunction with the accompanying drawings.
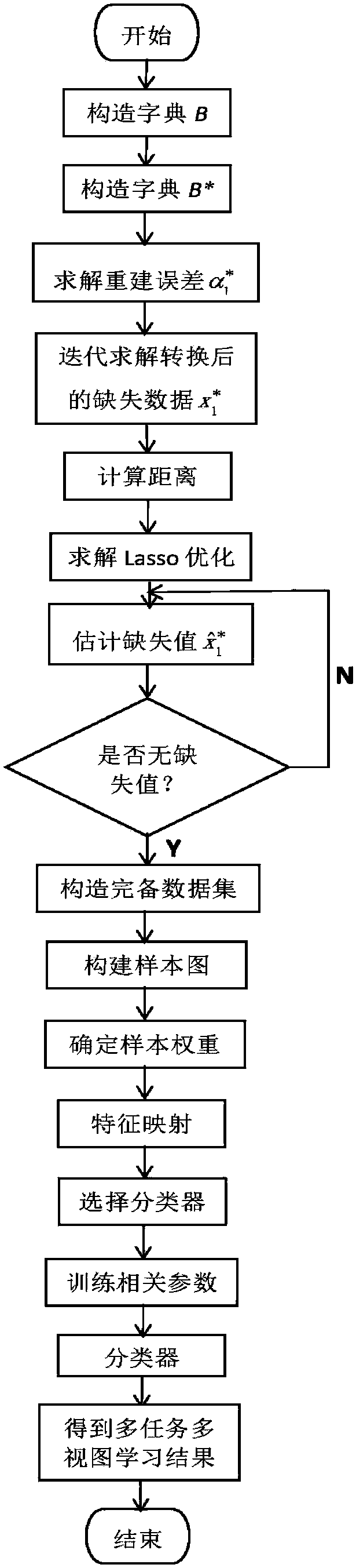
[0055] A method for classifying missing data from unstructured views. A MMLE (Multi-task Multi-view Laplacian Eigenmaps) framework based on multi-task multi-view Laplacian Eigenmaps is proposed to enrich the information content of original data. The framework consists of two stages: Data processing in the absence of structured views, multi-task multi-view classification in the absence of unstructured views. It includes the following steps:
[0056] Step 1. Processing of unstructured missing data, such as figure 1 As shown, the processing steps are as follows:
[0057] (1) Construction dictionary B=[b 1 ,b 2 ,...,b i ,...,b p ]∈R m×p , there are three ways to construct dictionary B:
[0058] 1) Directly use the complete data set as the elements in the dictionary B;
[0059] 2) Select the K nearest neighbors of the unstructured missing data as the elem...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More