

Actor-Critic neural network continuous control-based fast learning algorithm
A learning algorithm and neural network technology, applied in the field of fast learning algorithm based on Actor-Critic neural network continuous control, can solve problems such as random sampling and low learning efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0055] The present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
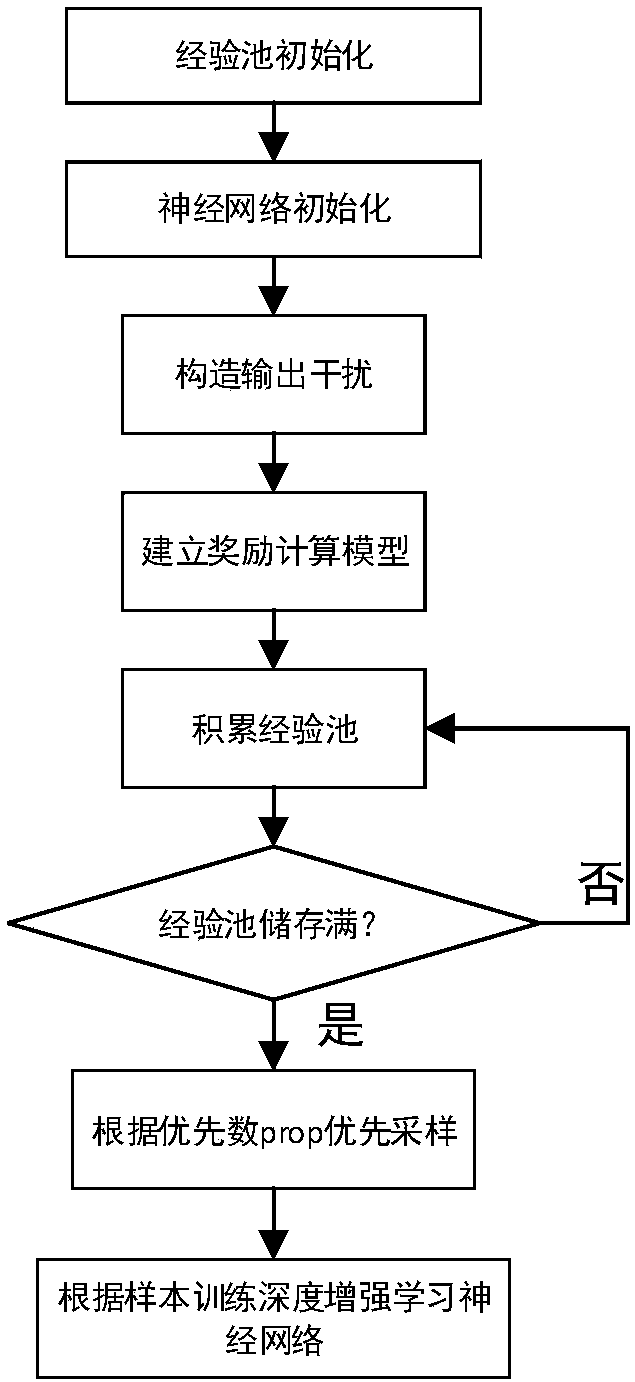
[0056] Such as figure 1 Shown is a schematic flow chart of the fast learning algorithm based on Actor-Critic neural network continuous control, including the following steps:
[0057] Step 1) Initialize
[0058] 1.1) Experience pool initialization: set the experience pool as a two-dimensional matrix with m rows and n columns, and initialize the value of each element in the two-dimensional matrix to 0, where m is the size of the sample and n is the information stored in each sample Quantity, n=2×state_dim+action_dim+3, state_dim is the dimension of the state, action_dim is the dimension of the action; at the same time, reserve space in the experience pool for storing reward information, usage traces and time difference errors, n= The 3 in the formula 2×state_dim+action_dim+3 is the reserved space for storing reward information, usage...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More