

Method for automatically judging dress code through surveillance video
A technology for automatic judgment and monitoring of video, applied in closed-circuit television systems, instruments, biological neural network models, etc., can solve problems such as poor detection results, complex kitchen environment, and easy interference of light by smoke, etc., to improve detection results, Robustness, the effect of reducing the input of supervisory manpower
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
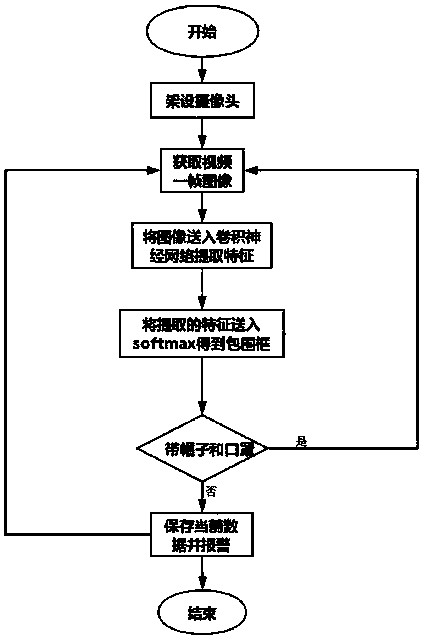
[0030] A method for automatically judging the dress code through surveillance video, mainly used to judge whether the head dress of the operator is standard, mainly includes the following steps:
[0031] Step A1: The video captures the clothing characteristics of the workers and generates images;
[0032] Step A2: Use the deep learning method to process the marked image of the worker's attire; extract the feature of the worker's attire, select the last layer as the result of feature extraction, and use the softmax function to calculate the probability, and output the calculated maximum value to generate training Model;
[0033] Step A3: Input the image generated in step A1 into the training model generated in step A2, and output an alarm message if it is detected that the attire of the worker does not meet the set standard.
[0034] The present invention collects the information on the head dress of the operator in real time through the camera, converts the video information ...
Embodiment 2
[0036] This embodiment is further optimized on the basis of Embodiment 1, and the step A2 mainly includes the following steps:
[0037] Step A21: Collect images of workers with different types of clothing, and mark the images; divide the images of marked workers into 13×13 rectangular blocks, and use a clustering method to predict anchor points for each rectangular block Frame, the rectangular block takes 5 anchor frames, the size of the anchor frame matches the size of different detection objects;
[0038] Step A22: Input the divided rectangular block into a multi-layer convolutional neural network, use the convolutional neural network to extract image features, take out the features of the last layer, and input them into the softmax function, and select the maximum probability value as the output result , resulting in a training model.
[0039] The present invention collects the information on the head dress of the operator in real time through the camera, converts the vide...
Embodiment 3
[0042] This embodiment is further optimized on the basis of Embodiment 1 or 2. In the step A1, the collected video is converted into an image, the image is divided into several 13×13 rectangular blocks, and each rectangular block is aggregated. Class prediction anchor point frame, described rectangular block takes 5 anchor point frames, and the size of anchor point frame matches the size of different detected objects;
[0043] In the step A3, input the image generated in the step A1 to the training model, use the convolutional neural network to extract the features of the image, take out the features of the last layer and input the softmax function, and initially judge whether each rectangular block contains the worker's head Internal features, if the rectangular block contains the head features of the worker, then generate the corresponding bounding box, and give the probability values of violation and non-violation respectively, and select the largest probability value as t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More