

A spatio-temporal and channel-based multi-attention mechanism video description method
A video description and attention technology, applied in the field of optical communication, can solve the problems of reduced model sentence generation ability, weakened influence, video feature and sentence description modeling, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
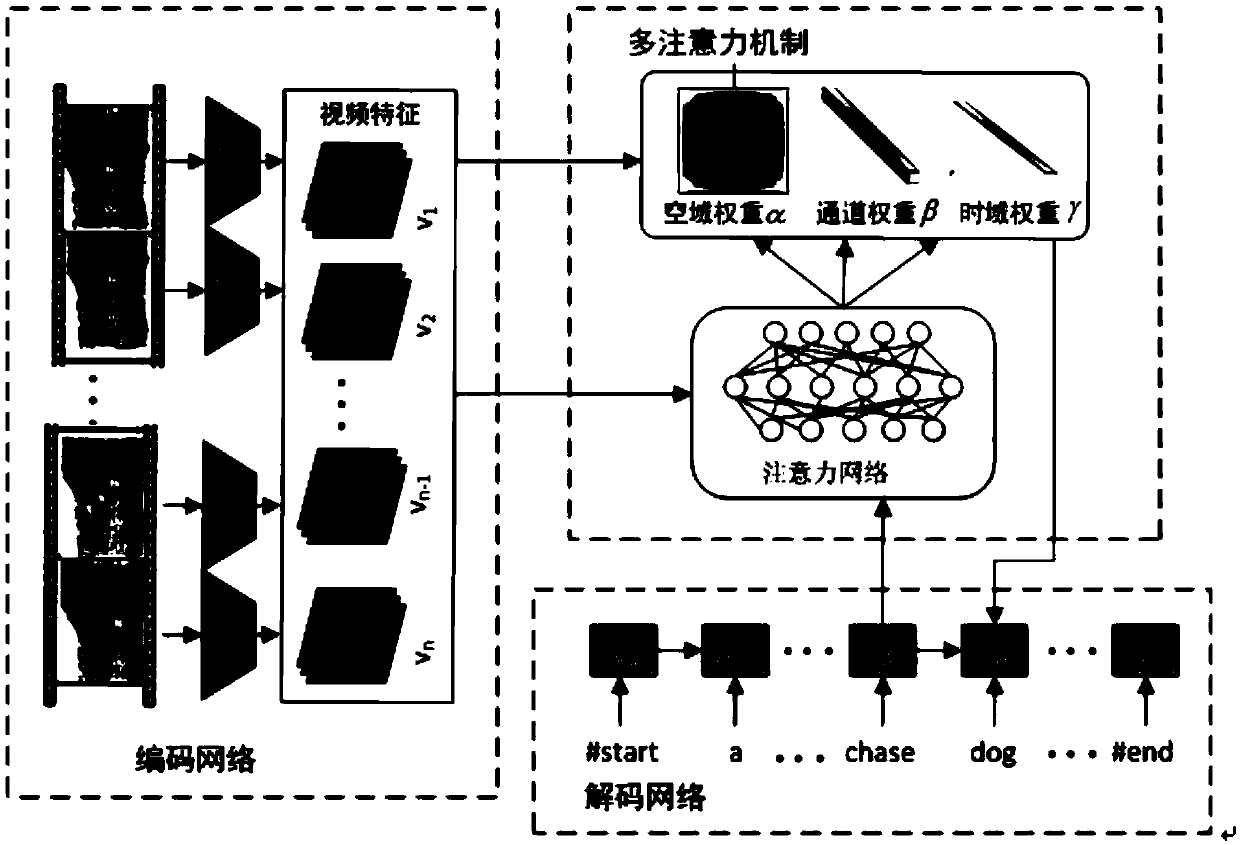
[0059] figure 1 It is a principle diagram of the multi-attention mechanism video description method based on space-time and channels of the present invention.
[0060] In this example, if figure 1 As shown in the present invention, a multi-attention mechanism video description method based on space-time and channel can extract powerful and effective visual features from the time domain, space domain and channel respectively, so as to make the representation ability of the model stronger. It is introduced in detail, specifically including the following steps:
[0061] S1. Randomly extract M videos from the video library, and then simultaneously input M videos to the neural network CNN;
[0062] S2. Training neural network LSTM based on attention mechanism
[0063] Set the maximum number of training times to H, and the maximum number of iterations in each round of training to be T; the word vector of the word at the initial moment is w 0 , h 0 Initialize to 0 vector;
[00...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More