

A data allocation method for cpu-fpga heterogeneous multi-core system
A CPU-FPGA and heterogeneous multi-core technology, which is applied in the field of data distribution for CPU-FPGA heterogeneous multi-core systems, can solve problems such as not optimizing system performance, and achieve the effect of improving overall performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

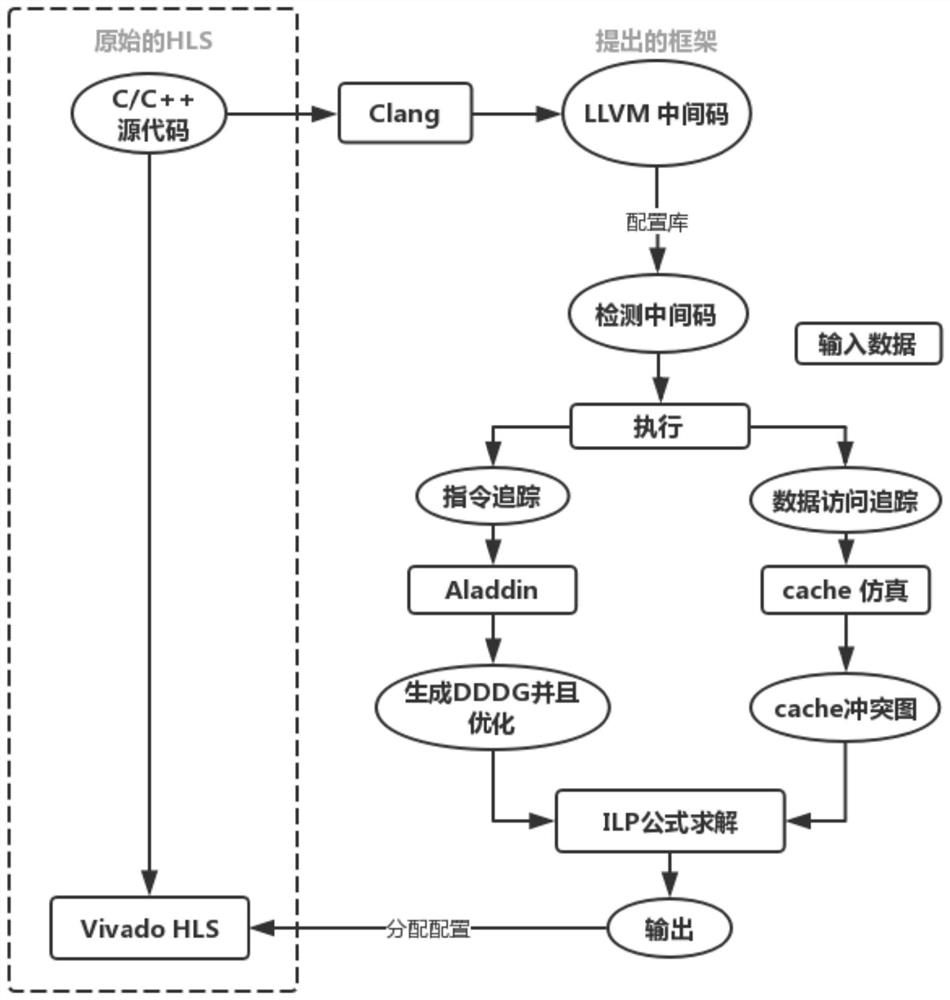
Examples
Embodiment 1
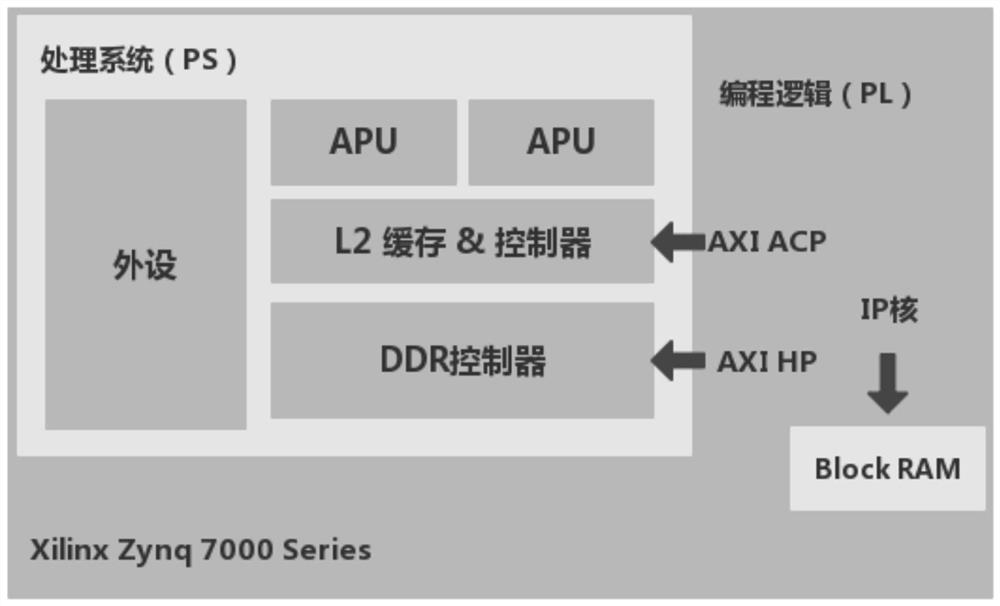
[0093] In order to understand the memory-level performance of CPU-FPGA HMPSoC, a memory access latency model is constructed.
[0094] To measure the access latency of a single memory hierarchy using a Xilinx Zynq-7020 SoC at a clock frequency of 100MHz, a microbenchmark FPGA core was designed to perform millions of memory accesses of a specific type. For example, a kernel that repeatedly accesses a huge matrix column sort via ACP can be used to measure the average ACP read miss (i.e. L2 cache read miss) latency.
[0095] Sizing the matrix according to the size of the given L2 cache ensures that all column-ordered accesses result in a cache miss.
[0096] The experimental results are shown in Table 1:
[0097] Table 1
[0098]
[0099] The parameters will be used in some formula operations in step (3), for example:
[0100] In the definition of the execution time variable of the basic block:
[0101]
[0102] If a node represents an array a i memory load instructions...
Embodiment 2
[0118] The purpose of this example is to show that the allocation of data has a significant impact on the system performance of the Zedboard platform based on the Zynq-7020 SoC.
[0119] The experiment used the stimulus example of General Matrix Multiplication (GEMM) from Polybench:
[0120] Algorithm 1 Matrix Multiplication Algorithm
[0121]
[0122] We assume that at most 1 of the 3 arrays A, B, and C can fit in the on-chip BRAMs.
[0123] Experimental results such as Figure 4 shown, where A a B b C h Indicates the allocation scheme of arrays A, B, and C respectively allocated to ACP, BRAM, and HP ports.
[0124] The results show that the optimal allocation (A b C a B h ) than the worst allocation (A h C h B b ) is accelerated by a factor of 3.14.
[0125] In addition, it can be seen that some results may run counter to the traditional CPU-based SPM allocation scheme.
[0126] (1) Compared with the other two arrays, array C has significantly higher read and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More