

A deep convolutional neural network model adaptive quantization method based on modulus length clustering
A neural network model and adaptive quantization technology, applied in biological neural network models, neural architectures, etc., can solve problems such as limited storage resources and computing resources, network performance degradation, etc., to reduce the selection of unnecessary clustering points, The effect of fast clustering and reduced complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
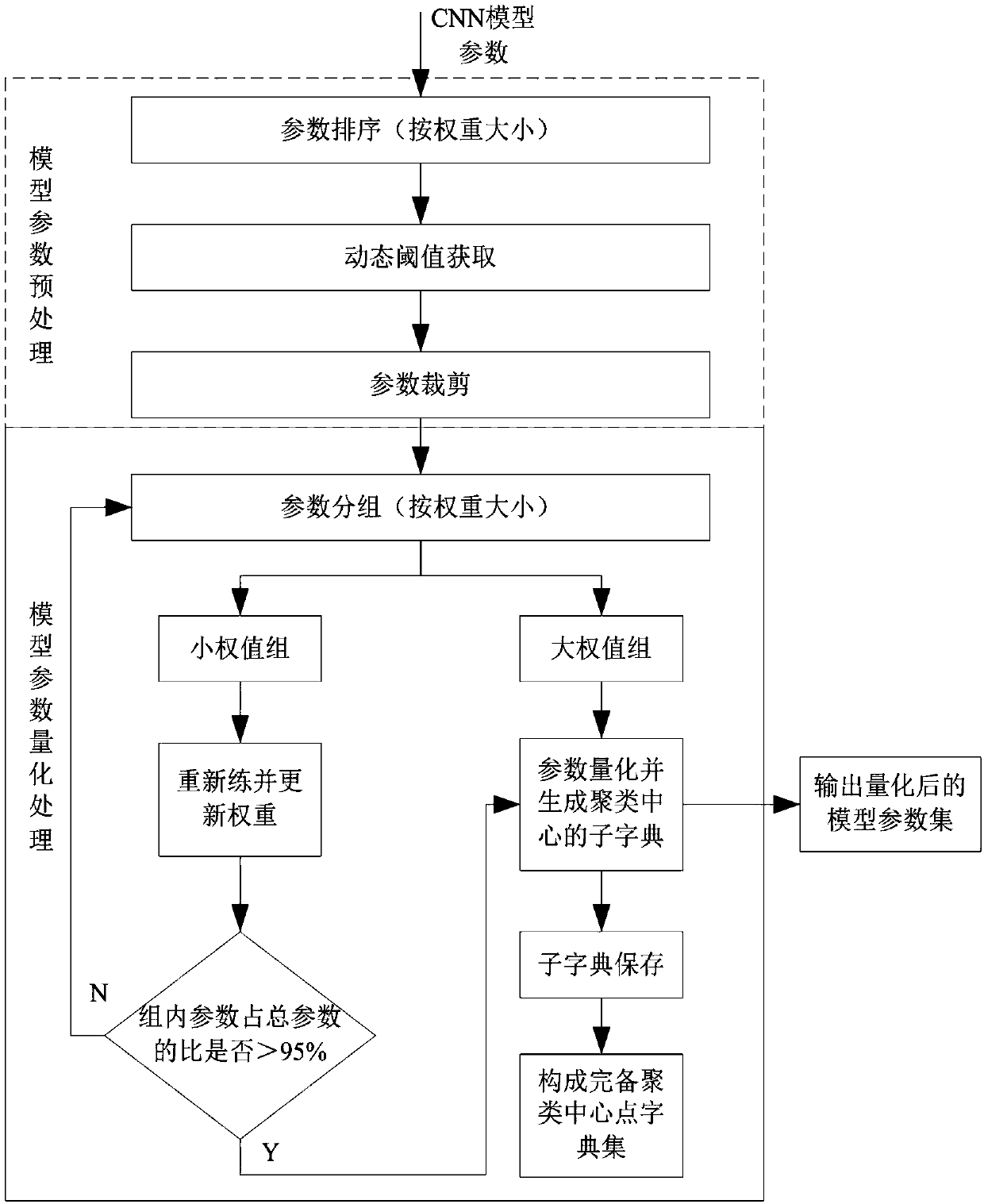
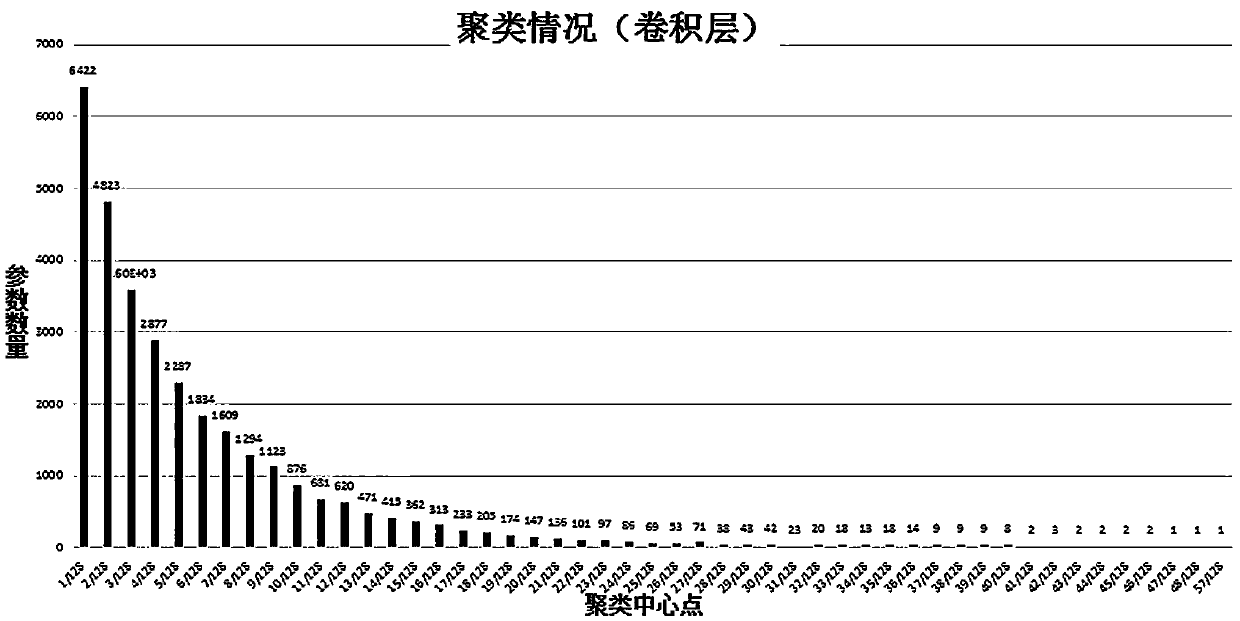
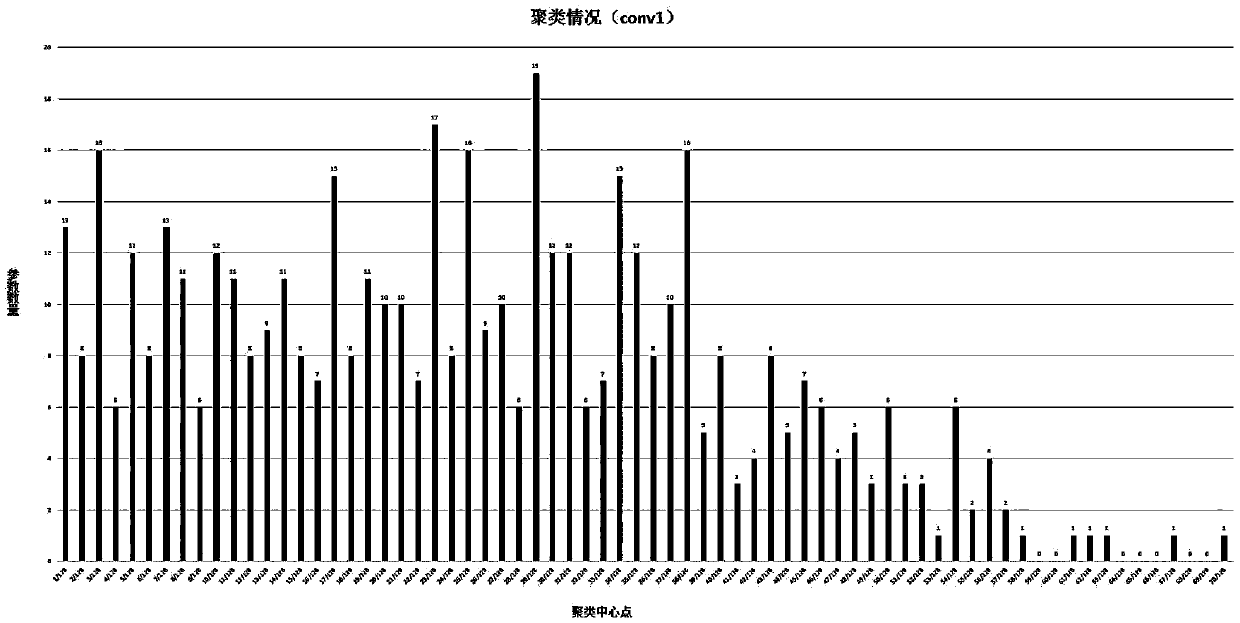
[0035] See attached figure 1 , is a flow chart of the adaptive quantization method for deep convolutional neural network models based on modular length clustering. The design and implementation of the adaptive quantization method for deep convolutional neural network models of the present invention are mainly divided into three parts: preprocessing of network model parameters , Group quantization of network model parameters and decomposition of quantized value...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More