Webpage data crawling method and device
A webpage data and data technology, applied in the field of Internet technology applications, can solve the problems of high data request volume and high network resource consumption, and achieve the effect of solving high data request volume, reducing network resource consumption, and reducing repeated requests
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0043] According to an embodiment of the present invention, an embodiment of a method for crawling web page data is provided. It should be noted that the steps shown in the flow chart of the accompanying drawings can be executed in a computer system such as a set of computer-executable instructions, and , although a logical order is shown in the flowcharts, in some cases the steps shown or described may be performed in an order different from that shown or described herein.
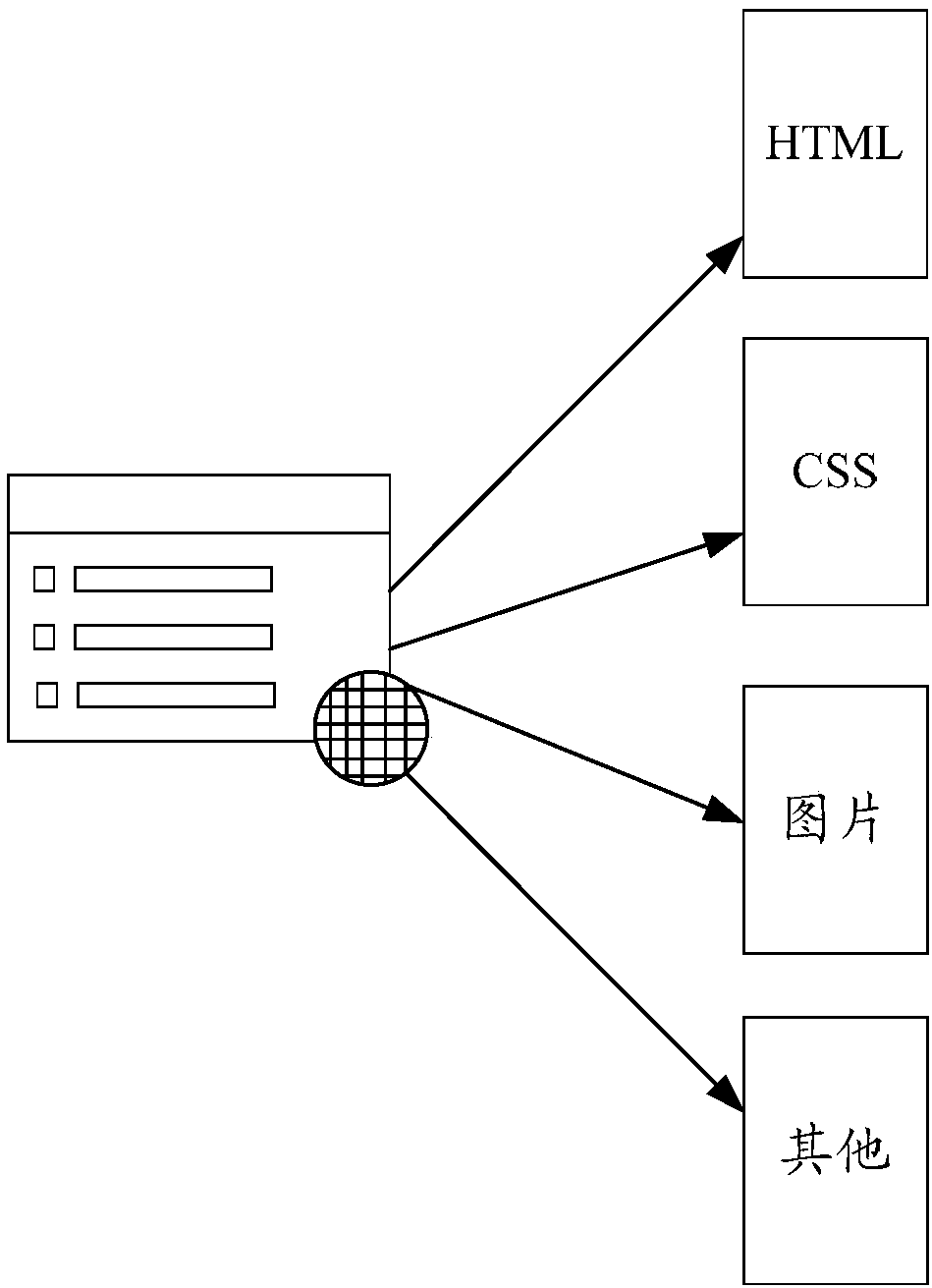
[0044] In the embodiment of the present invention, a proxy server is added between the web crawler and the remote website. When web crawlers send web page data crawling requests to network resources, they will all go through a proxy server. The proxy server includes a caching mechanism, which can formulate preset rules, and save network resources that meet the preset rules in the cache after successful acquisition.
[0045] image 3 It is a schematic flow chart of a method for crawling webpage data acco...
Embodiment 2
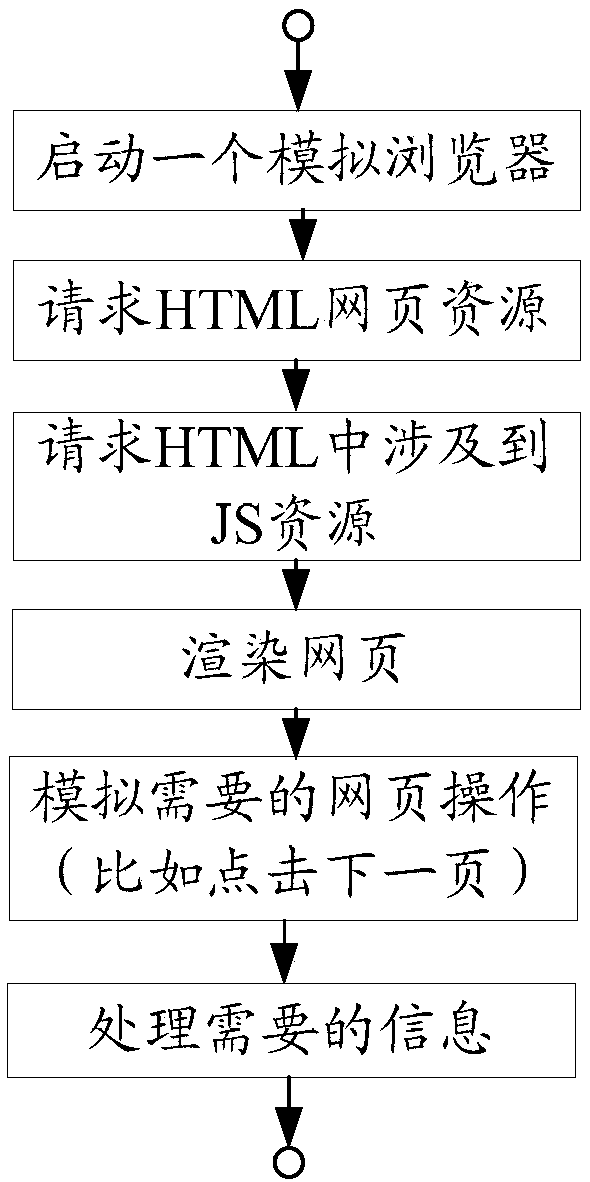
[0082] Image 6 It is a schematic flow diagram of another method for crawling webpage data according to an embodiment of the present invention, such as Image 6 As shown, on the remote website side, the method includes the following steps:
[0083] Step S602, receiving a webpage data crawling request forwarded by the proxy server;
[0084] Step S604, extracting corresponding data according to the web page data crawling request;
[0085] Step S606, returning the data to the proxy server.
[0086] In the webpage data crawling method provided by the embodiment of the present application, by receiving the webpage data crawling request forwarded by the proxy server; extracting the corresponding data according to the webpage data crawling request; and returning the data to the proxy server, reducing the hypertext transfer protocol The purpose of repeating HTTP requests is to realize the technical effect of reducing network resource consumption, and then solve the technical proble...
Embodiment 3
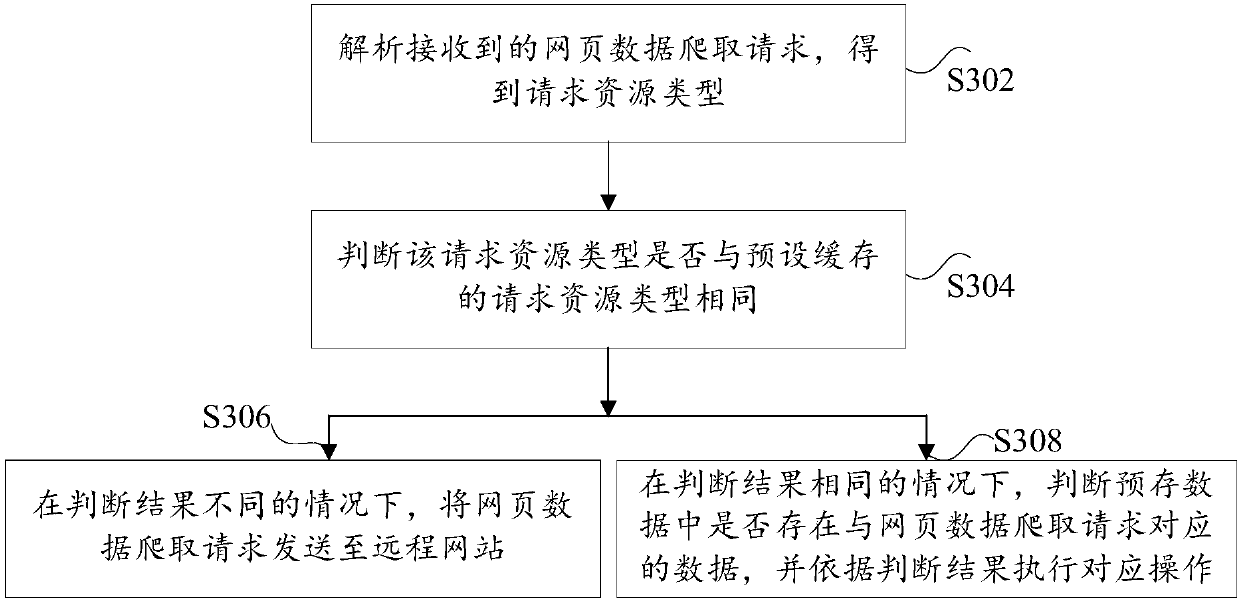
[0092] Figure 7 It is a schematic flow diagram of a device for crawling web page data according to an embodiment of the present invention, such as Figure 7 As shown, on the proxy server side, the device includes:
[0093] The parsing module 72 is used to parse the webpage data crawling request received to obtain the requested resource type; the first judging module 74 is used to judge whether the requested resource type is the same as the preset cached requested resource type; the sending module 76 is used to In the case of different judgment results, the webpage data crawling request is sent to the remote website; the second judging module 78 is used to judge whether there is data corresponding to the webpage data crawling request in the prestored data in the case of the same judgment result , and perform corresponding operations according to the judgment result.
[0094] In the webpage data crawling device provided in the embodiment of the present application, the reques...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More