

Method and system for extracting webpage content
A web page content and web page technology, applied in the field of web page content extraction, can solve the problems of slow extraction, single technical means, and low extraction accuracy, and achieve the effect of improving accuracy and accurate extraction results.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
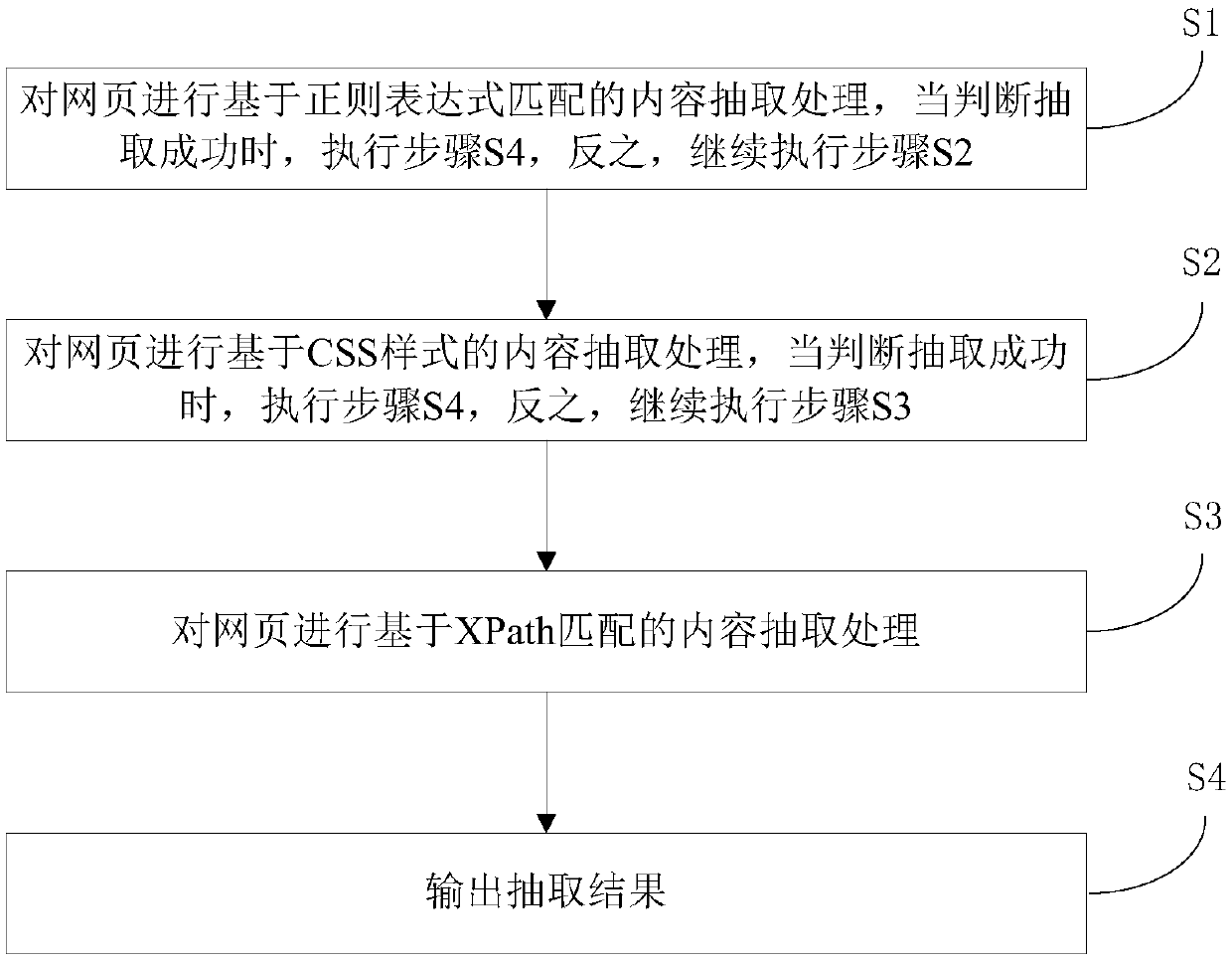
[0052] refer to figure 1 , the present invention provides a method for extracting webpage content, comprising the following steps:
[0053] S1. Perform content extraction processing based on regular expression matching on the webpage. When it is judged that the extraction is successful, execute step S4, otherwise, continue to execute step S2;
[0054] S2. Perform content extraction processing based on the CSS style on the webpage. When it is judged that the extraction is successful, execute step S4, otherwise, continue to execute step S3;
[0055] S3, performing content extraction processing based on XPath matching on the webpage;
[0056] S4. Outputting the extraction result.
[0057] This method firstly extracts the content of the webpage based on regular expressions. When the extraction is unsuccessful, it extracts the content of the webpage based on the CSS style, and when the extraction fails again, it extracts the content of the webpage based on XPath matching. Accord...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More