

Audio scene recognition method based on feature pyramid network
A feature pyramid and scene recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem of ineffective use of underlying features, and achieve the effect of fast prediction and improved model performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

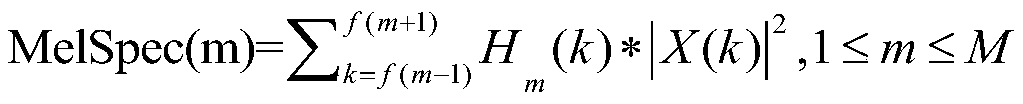
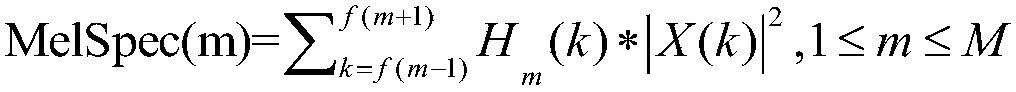
Examples
specific example
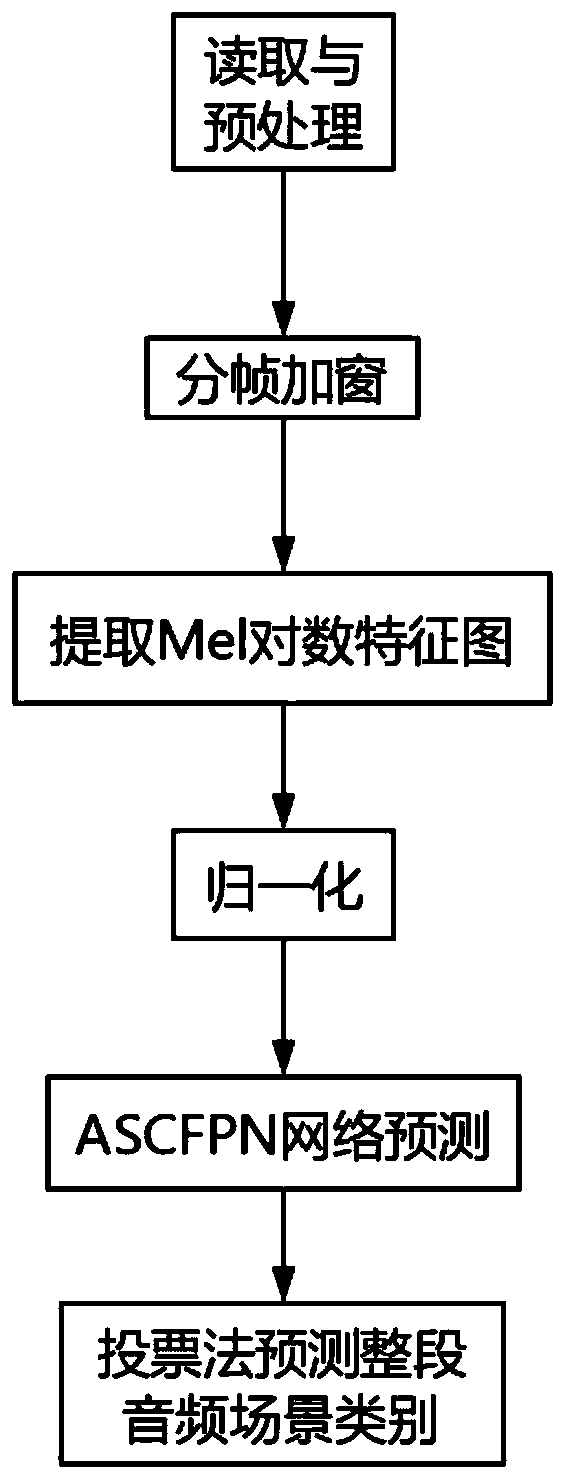
[0040] 1. Read the audio signal and perform truncation processing, and each segment is cut into a voice segment with a fixed duration of 10s;
[0041] 2. Perform frame-by-frame and window processing on fixed-duration speech signals, with 2048 sampling points per frame and 2048-point Hamming window;
[0042] 3. The signal after framing is extracted and logarithmized through the Mel filter bank, the number of filters is 134, the window length of the filter is 1704 points, and 852 points are overlapped between frames;
[0043] 4. Normalize the obtained Mel spectrogram;
[0044] 5. Input the normalized Mel spectrogram into the ASCFPN network for forward propagation;
[0045] 6. Use the voting method to count the prediction results of each frame, and the most predicted scene category is output as the prediction result of the entire audio.
[0046] Table 1 Comparison of various audio scene recognition algorithms
[0047]
[0048] As shown in the above table, ASCFPN is an algor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More