

Hadoop-based big data association rule mining method
A technology of big data and large data sets, applied in the fields of electrical digital data processing, special data processing applications, digital data information retrieval, etc., can solve the problems of long calculation time, inability to store intermediate results, etc., to avoid inefficiency, avoid memory and the effect of I/O consumption
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

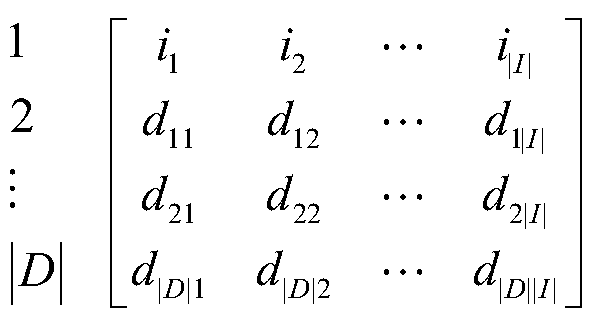
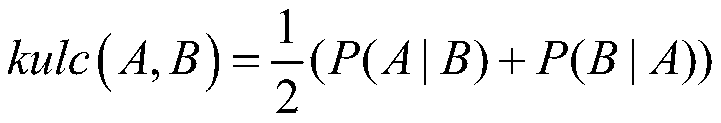
Examples
Embodiment Construction
[0044] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
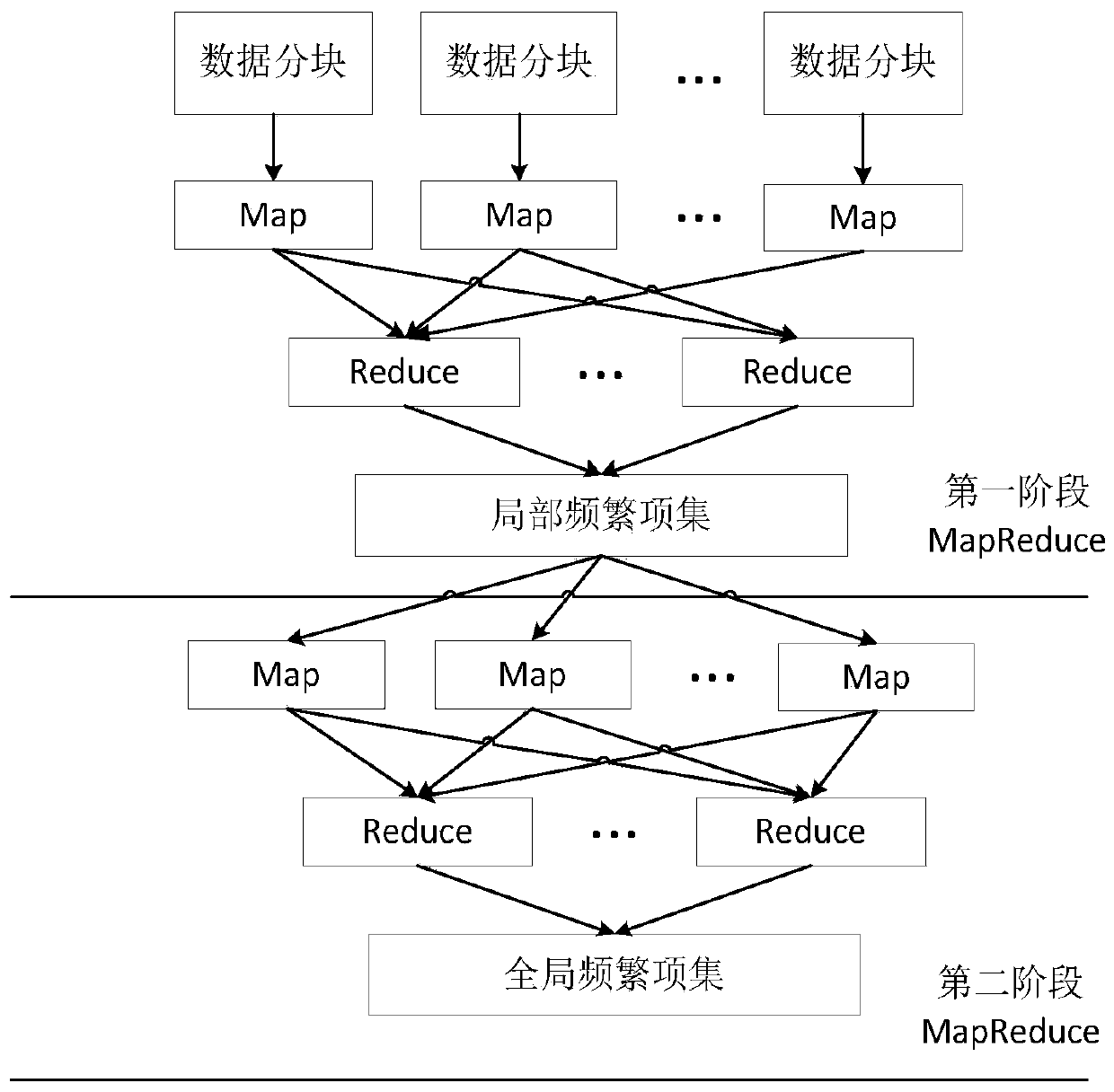
[0045] The mining method of Hadoop-based big data association rules of the present invention, such as figure 1 As shown, the specific operation process includes the following steps:
[0046] Step 1, input the large data set to be mined, and block the large data set;
[0047] The specific process of step 1 is as follows: Use HDFS, the core component of Hadoop, to block the large data set. In order to ensure data integrity, the number of copies is set to 3.
[0048] Step 2, using a two-stage MapReduce process to complete the task of mining association rules in large data sets;
[0049] Step 2 includes the following process:
[0050] Step 2.1, use the Map function to generate local candidate frequent itemsets, use the Reduce function to merge all local candidate frequent itemsets, and eliminate local candidate frequent itemsets that do not me...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More