

Visual dialogue generation method based on double visual attention network
An attention and dual-vision technology, applied in the field of computer vision, can solve the problems of only considering the global visual features, the visual semantic information is not accurate enough, and the word-level semantics are not considered.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
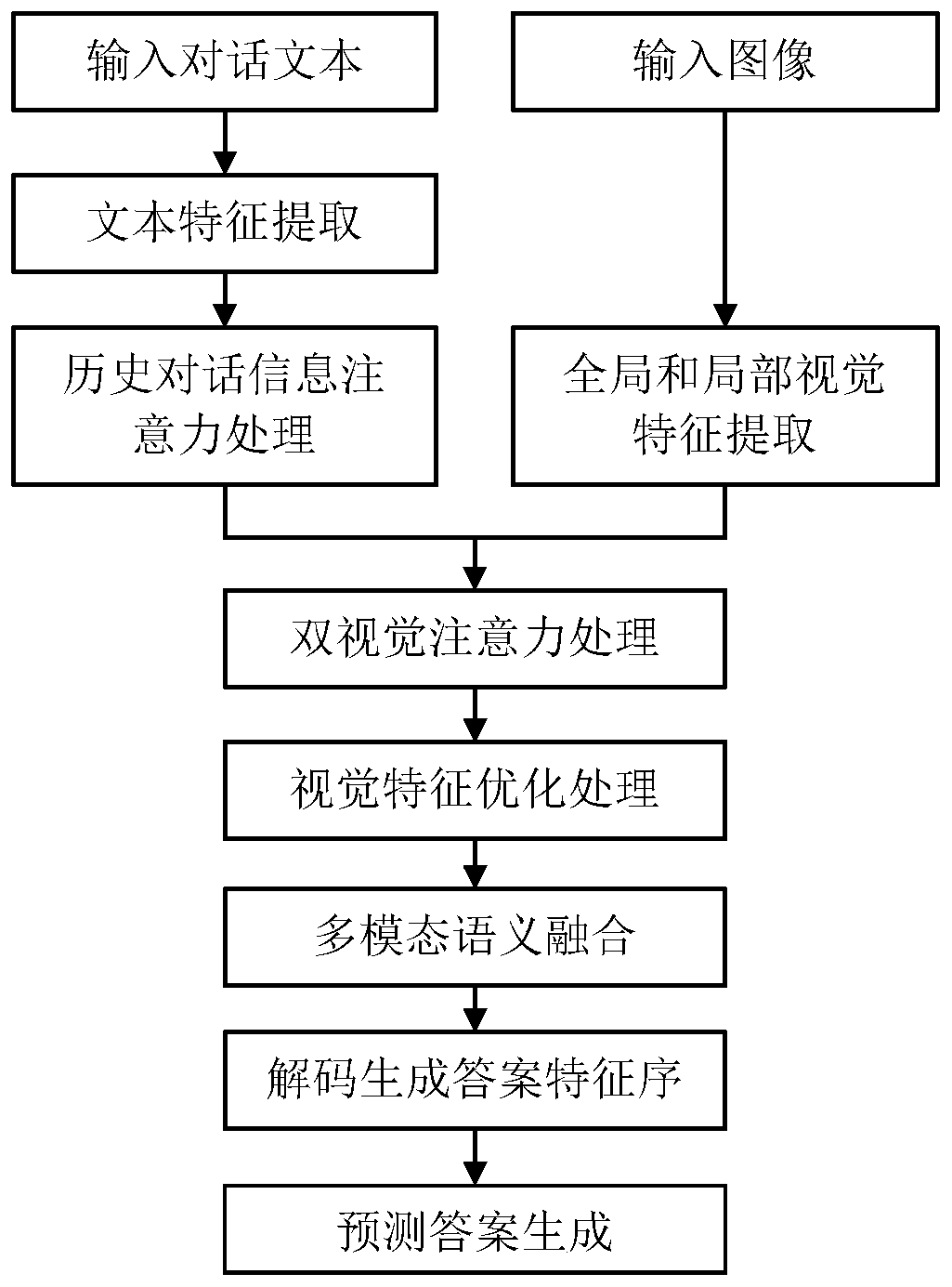
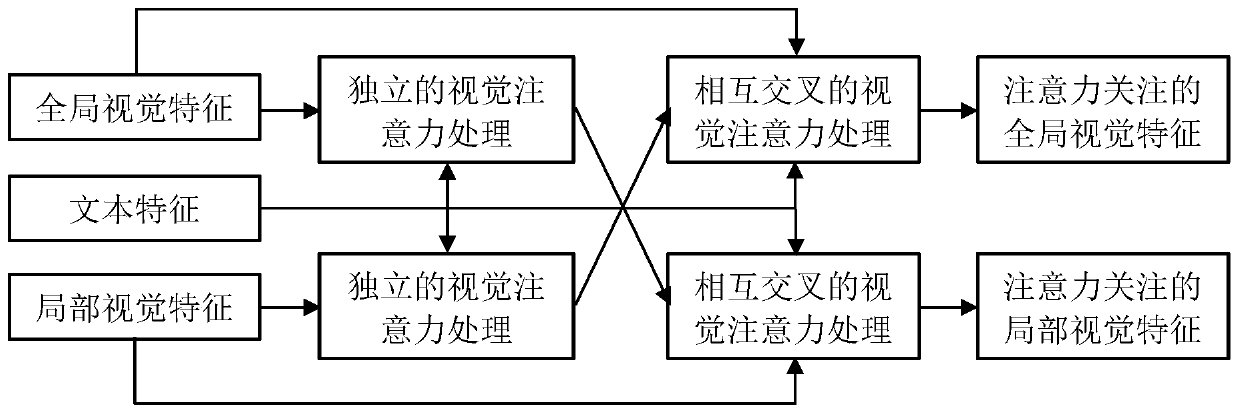
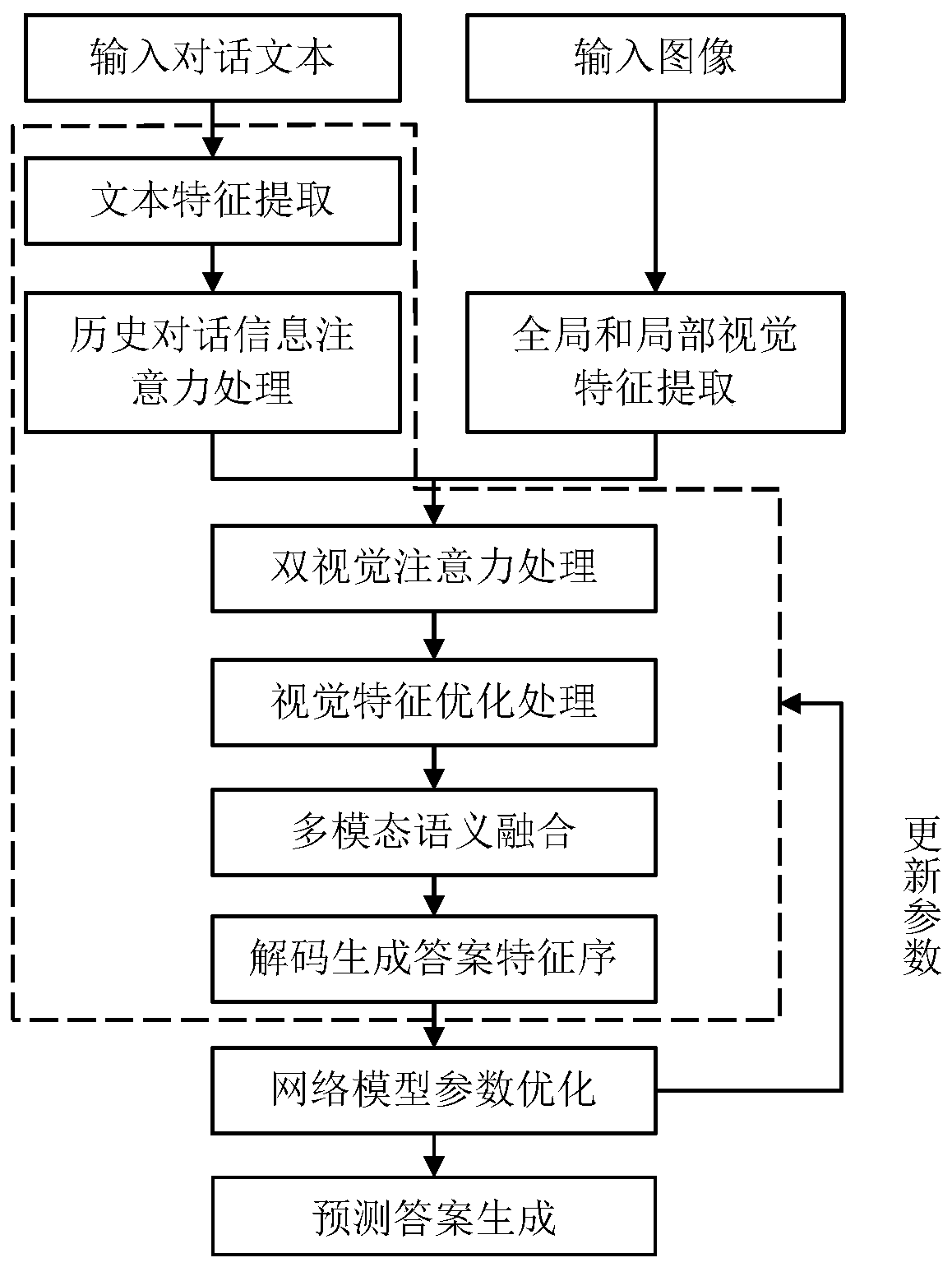
[0091] In this example, if figure 1 As shown, a visual dialogue generation method based on a dual-visual attention network is performed as follows:
[0092] Step 1. Preprocessing of text input in visual dialogue and construction of word list:
[0093] Step 1.1. Obtain visual dialogue datasets from the Internet. The currently public datasets mainly include VisDialDataset, which is collected by relevant researchers from the Georgia Institute of Technology. The visual dialogue dataset contains sentence text and images;
[0094] Perform word segmentation processing on all sentence texts in the visual dialogue dataset to obtain segmented words;
[0095] Step 1.2, screen out all words whose word frequency is greater than the threshold from the word after segmentation, the size of the threshold can be set to 4, and build the word index table Voc; the method for creating the word index table Voc: the word table can contain words, punctuation marks ; Count the number of words and sor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More