

Data index establishment method and device, data retrieval method and device, equipment and storage medium
A technology for data indexing and establishing methods, applied in the field of data processing, can solve the problems of affecting retrieval accuracy, long retrieval time, exponentially increasing retrieval difficulty, etc. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
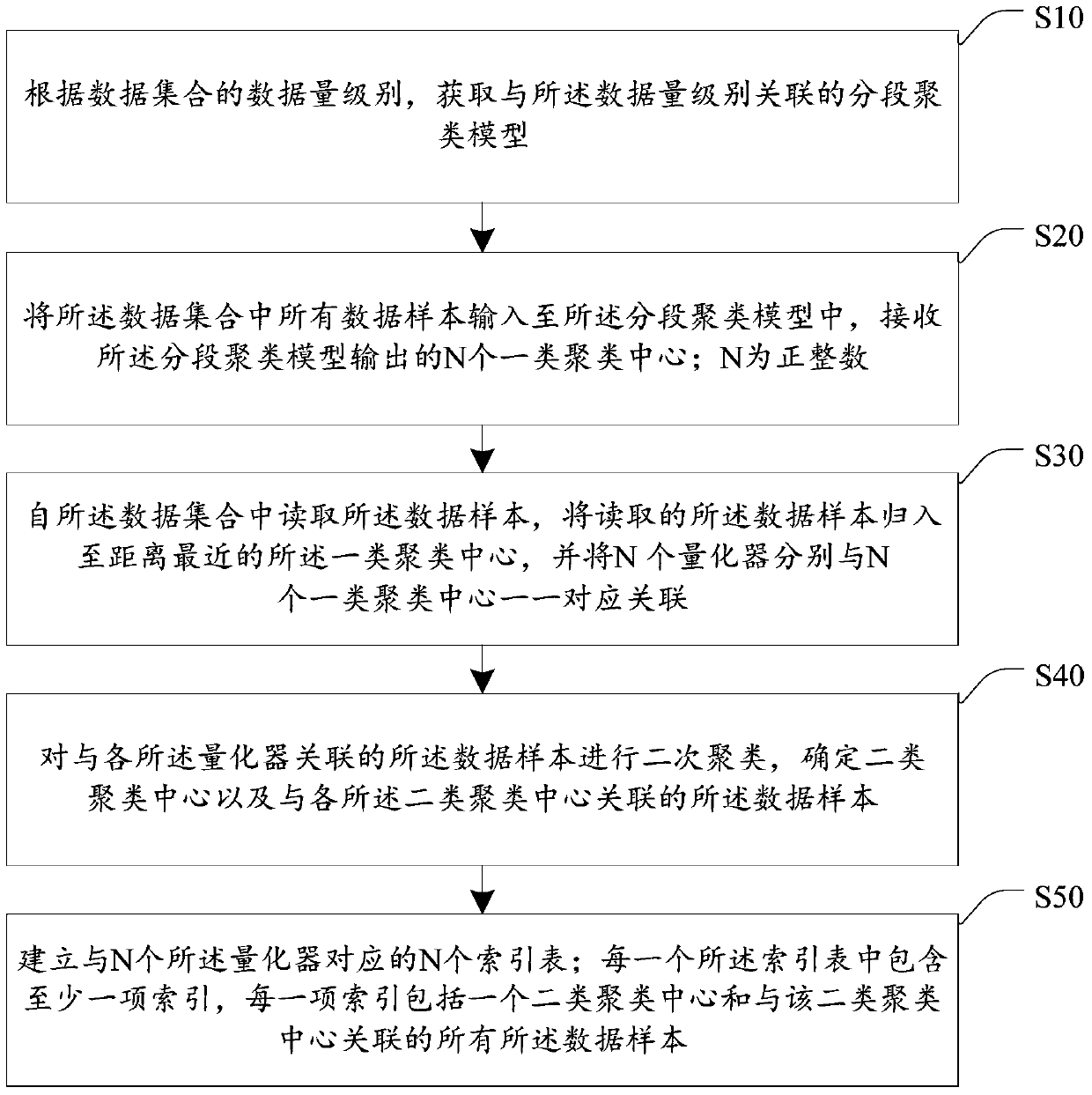
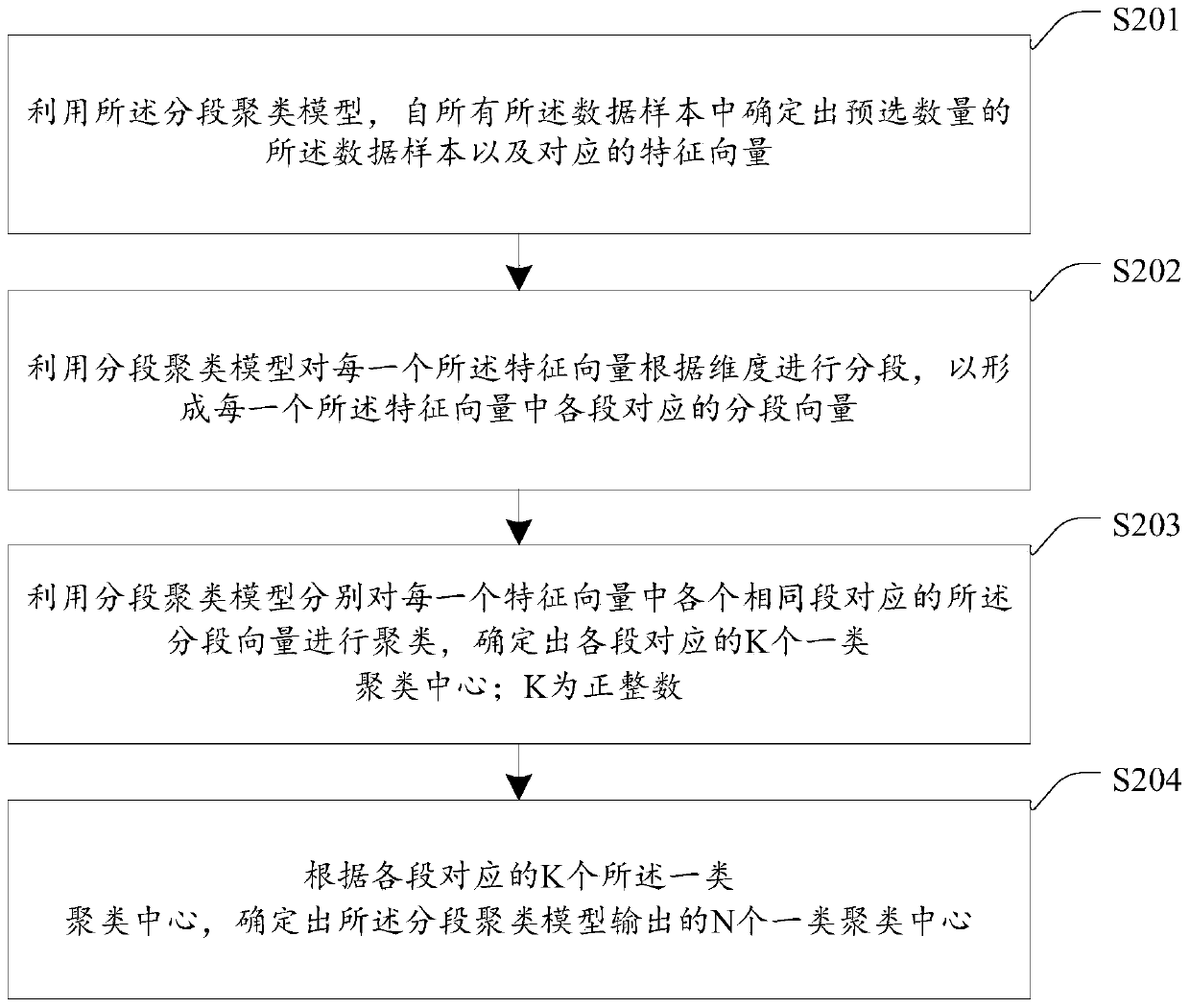
[0038] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are some of the embodiments of the present invention, but not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
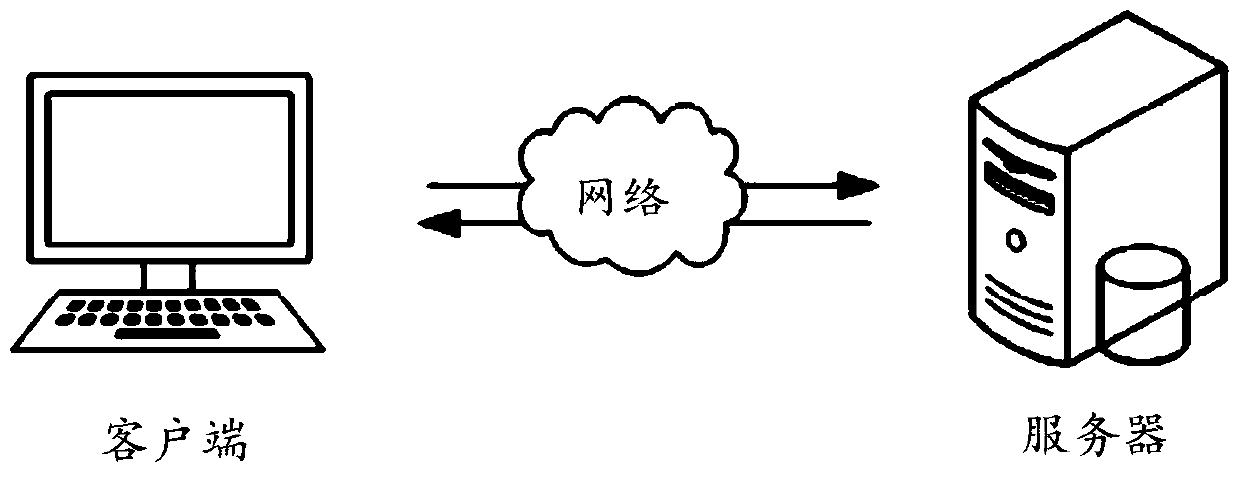
[0039] The cluster retrieval method of data samples provided by the present invention can be applied in such as figure 1 An application environment in which a client communicates with a server over a network. Among them, clients include but are not limited to various personal computers, notebook computers, smart phones, tablet computers, cameras and portable wearable devices. The server can be implemented by an independent server or a server cluster c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More