

Multi-agent action strategy learning method and device, medium and computing equipment
A multi-agent, strategy learning technology, applied in the field of reinforcement learning
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0063] The principle and spirit of the present invention will be described below with reference to several exemplary embodiments. It should be understood that these embodiments are given only to enable those skilled in the art to better understand and implement the present invention, rather than to limit the scope of the present invention in any way. Rather, these embodiments are provided so that this disclosure will be thorough and complete, and will fully convey the scope of the disclosure to those skilled in the art.
[0064] Those skilled in the art know that the embodiments of the present invention can be implemented as a system, device, device, method or computer program product. Therefore, the present disclosure may be embodied in the form of complete hardware, complete software (including firmware, resident software, microcode, etc.), or a combination of hardware and software.
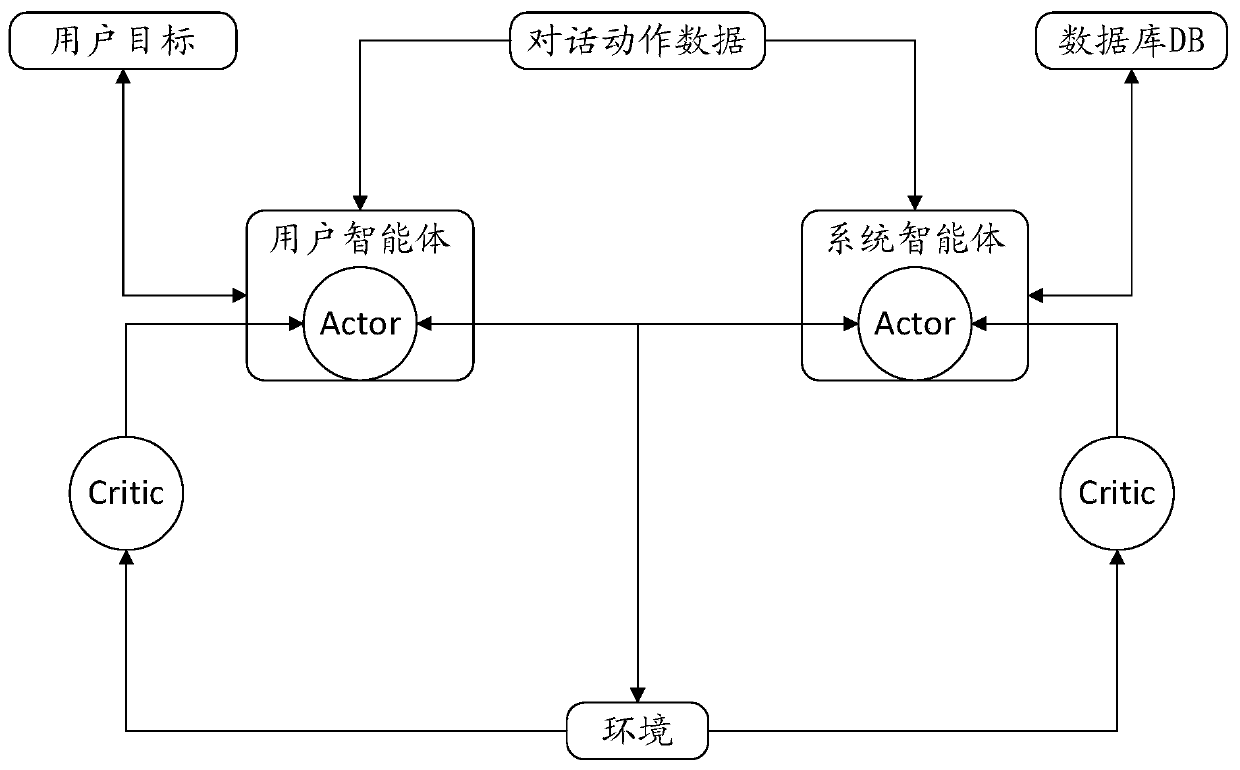
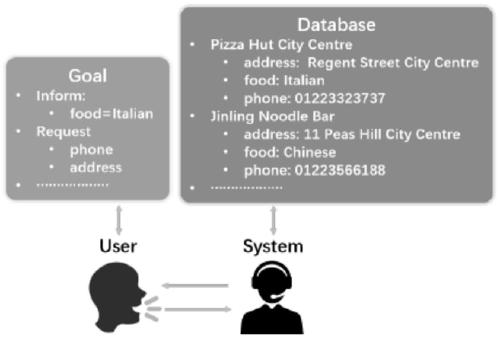
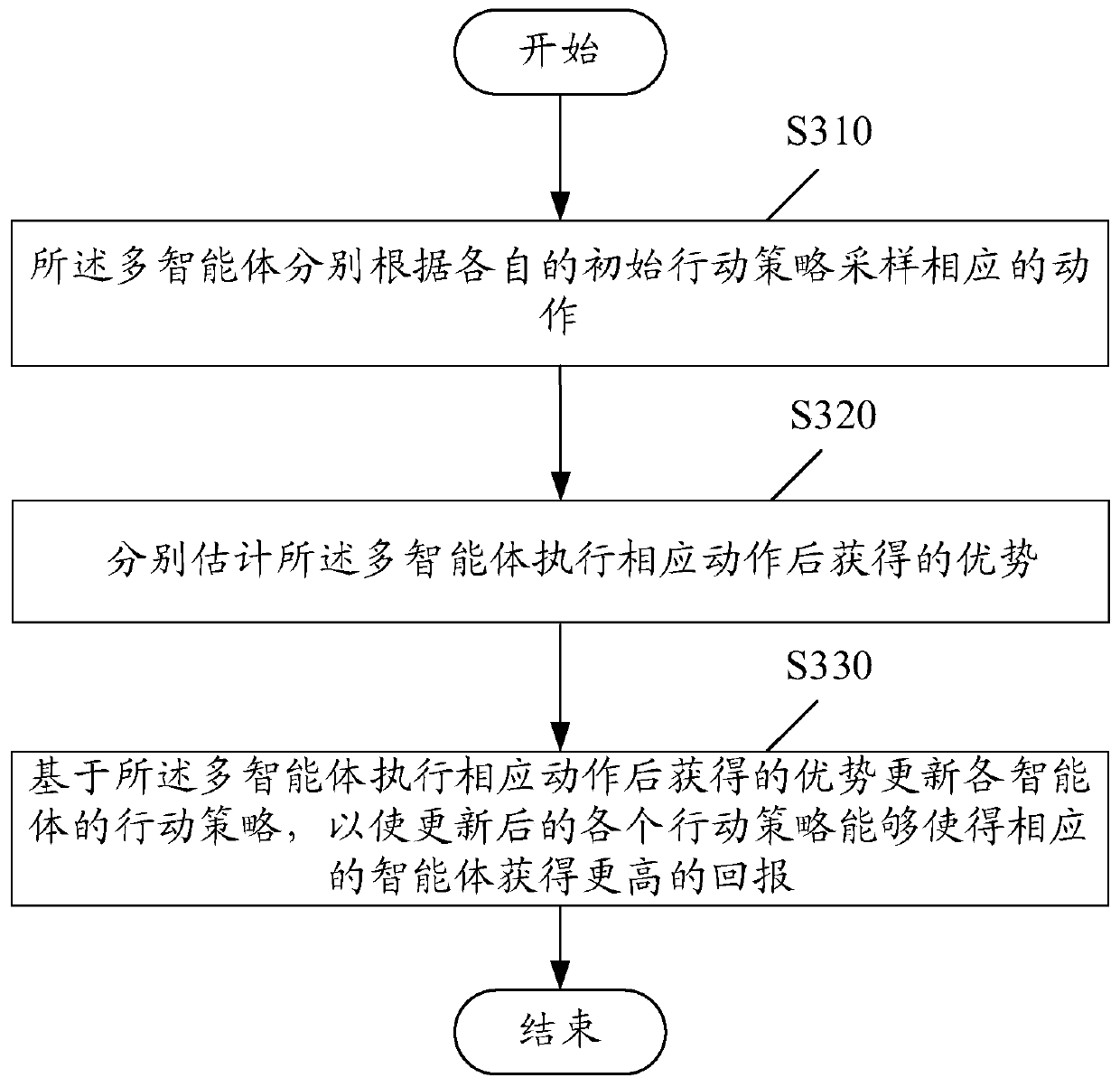
[0065] According to the embodiments of the present invention, a multi-agent action strateg...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More