Method for converting text into voice of specified style
A voice and style technology, applied in speech synthesis, voice analysis, instruments, etc., can solve problems such as strange changes in intonation, inability to adjust voice intonation, stuttering, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
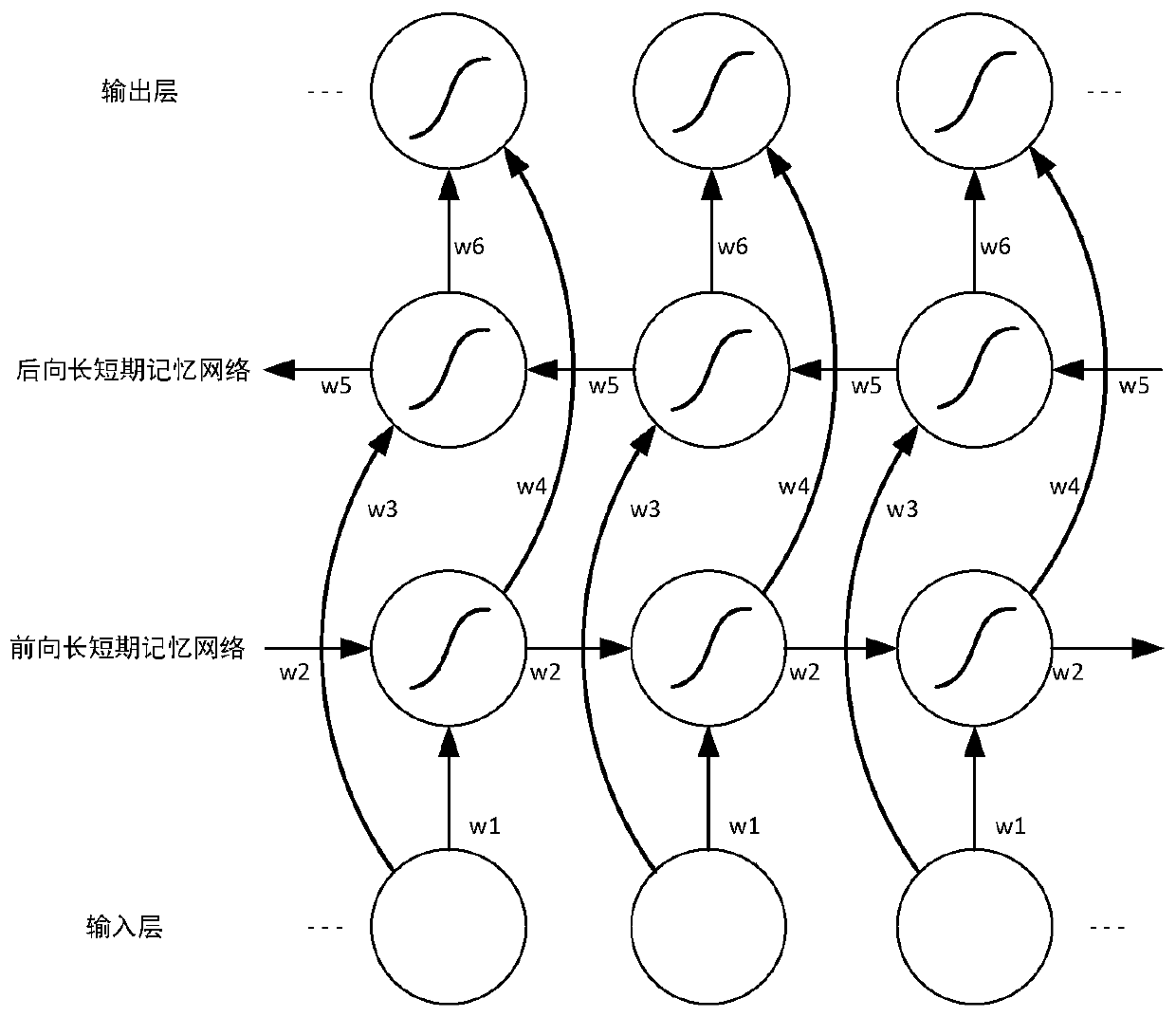
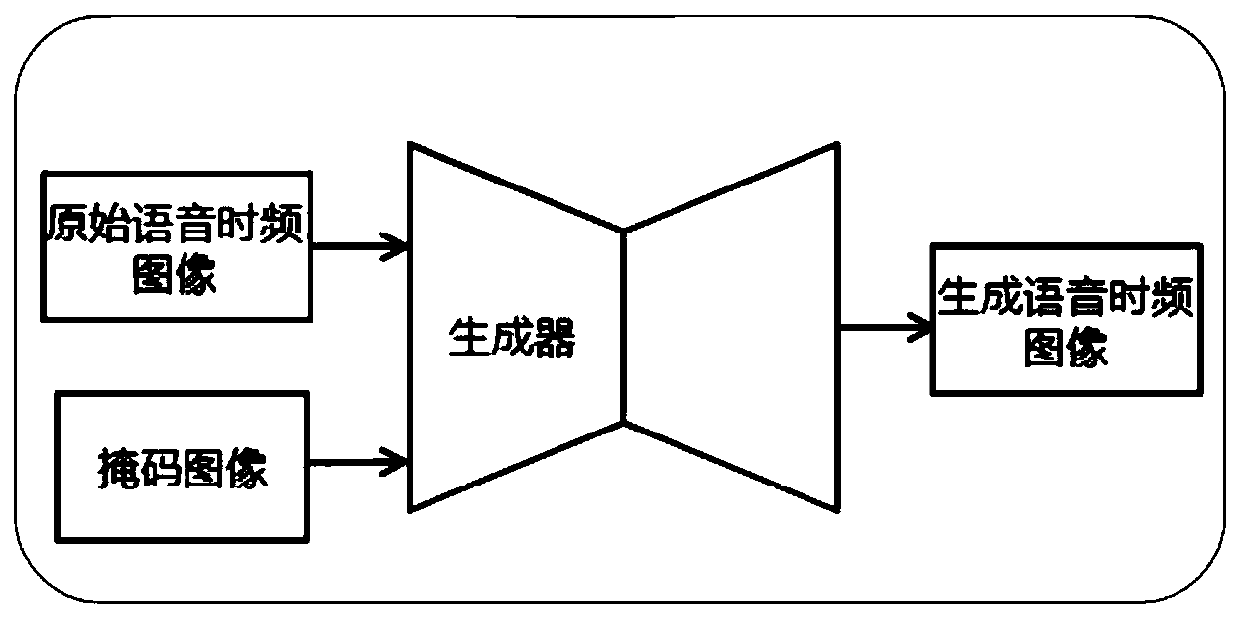
Method used
Image

Examples
Embodiment
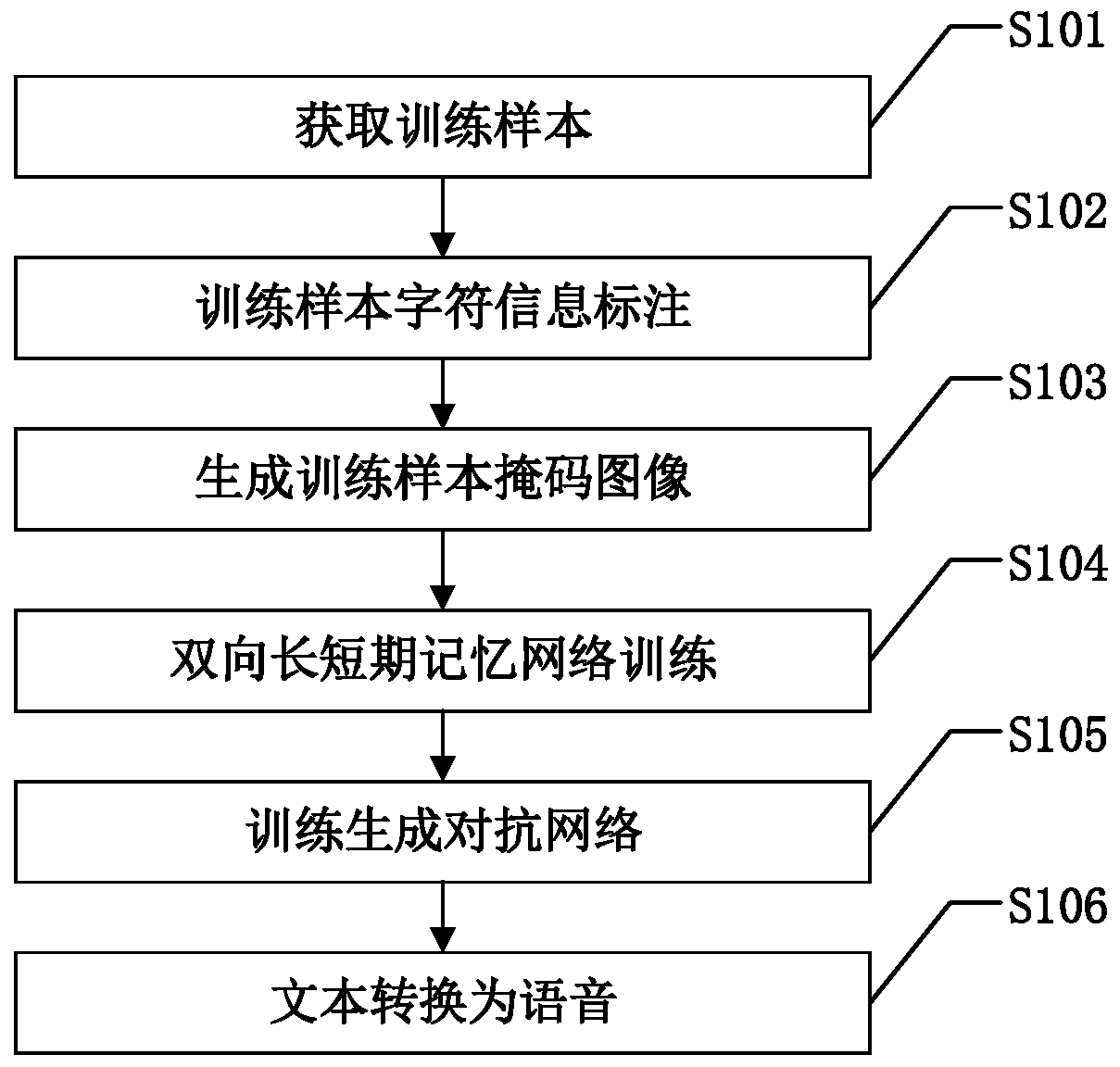
[0023] figure 1 It is a flowchart of a specific embodiment of the method for converting text into speech of a specified style in the present invention. Such as figure 1 As shown, the present invention converts text into the specific steps of the method for specifying style speech and includes:
[0024] S101: Obtain training samples:
[0025] Acquire several speech signals of different styles, and divide the speech signals according to the predetermined time interval, record the number of speech signals obtained by segmentation as N, and record the nth speech signal as S n , where n=1,2,...,N, get the speech signal S n the text T n and speech time-frequency image I n , classify the speech signal according to the style, denote the speech signal S n The corresponding style classification label F n . Generally speaking, the style classification label can be set as the serial number of the network, such as F n =1,2,...,K, K represents the number of style types.
[0026] T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More