

Multi-speaker clustering system and method based on attention mechanism
An attention and speaker technology, applied in computer parts, speech analysis, instruments, etc., can solve the problem of insufficient generalization ability, one person, the latter part is another person, and the model learning frame features lack of ability to discriminate characteristics, etc. problem, to achieve the effect of improving the clustering effect and reducing the performance degradation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
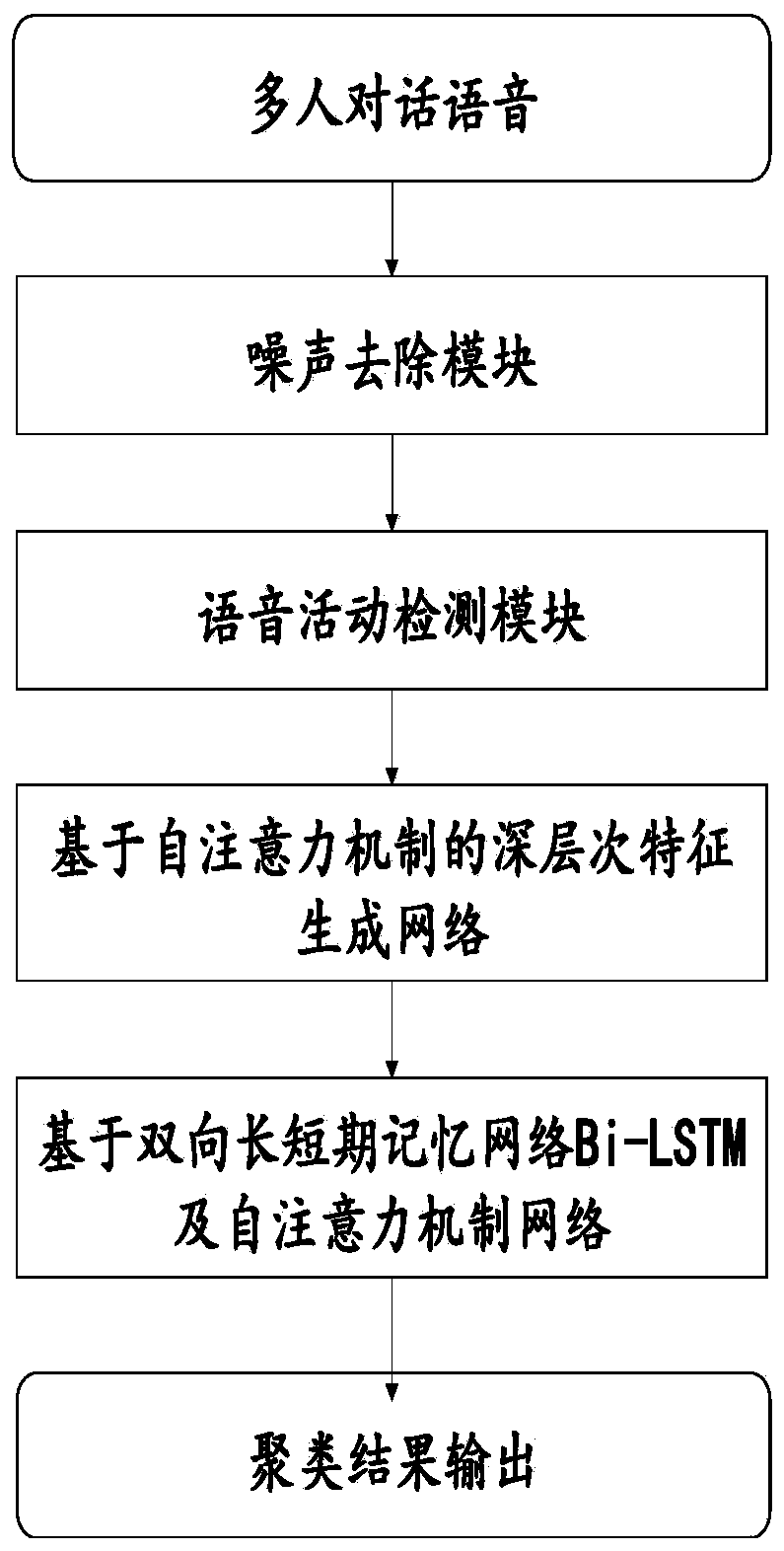
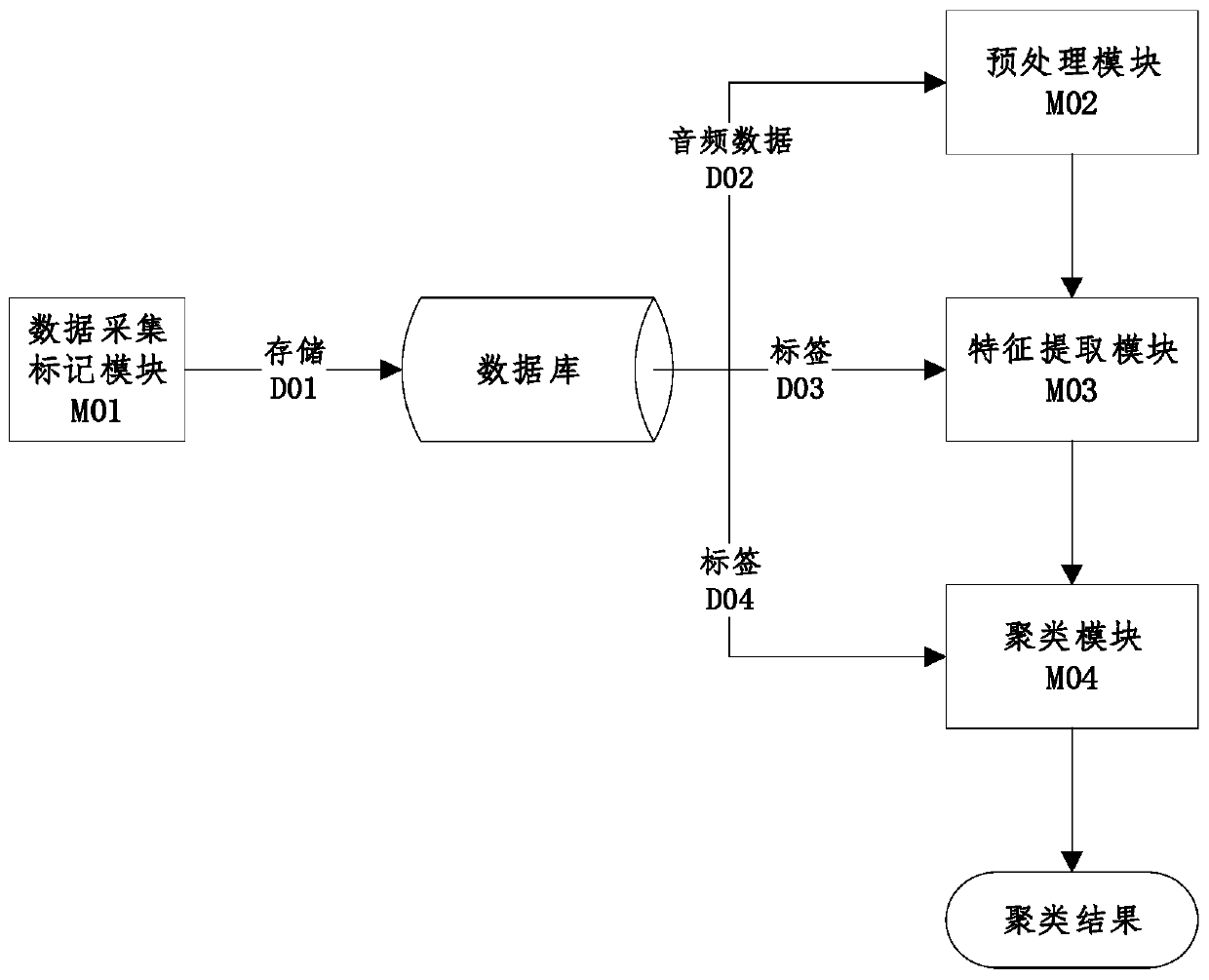
[0064] Such as figure 1 As shown, the present embodiment is a kind of multi-speaker clustering system based on attention mechanism, including noise removal module, voice activity detection module, deep-level feature vector generation module and deep-level feature vector clustering module;
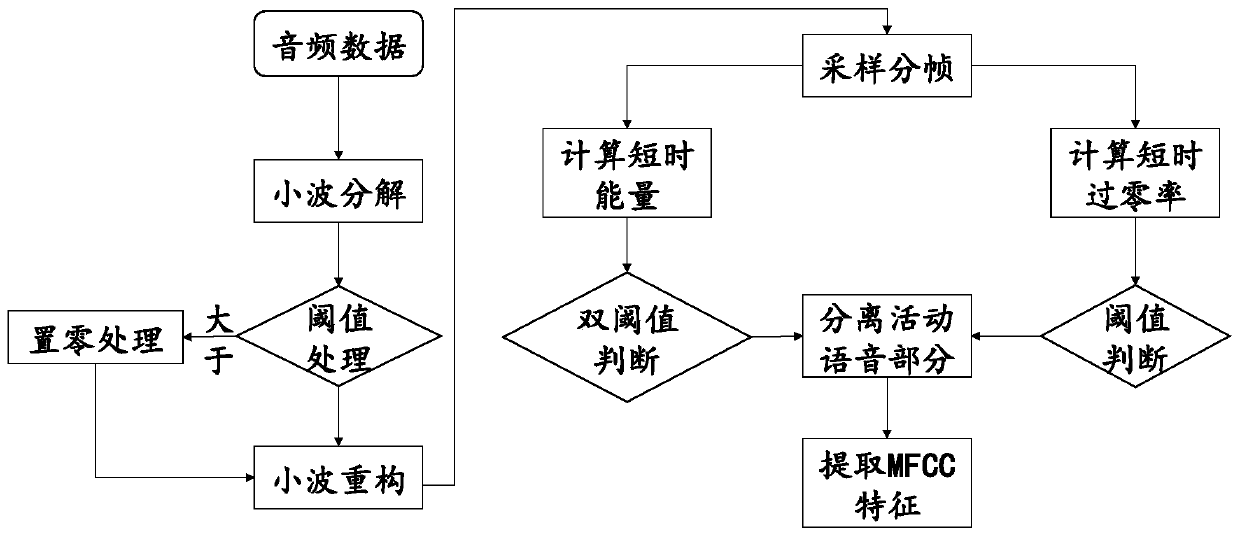
[0065] The noise removal module is used to remove noise in the audio; the noise removal module is used to remove audio background noise methods, including but not limited to the following methods and variants thereof: wavelet transform, Wienerfiltering (Wienerfiltering), LogMMSE , neural network DNN, CNN, etc.
[0066] The voice activity detection module is used to detect the start and end position of the sound, and separate the voice part and the non-voice part; the voice activity detection module is used to detect the start and end position of the sound, and separate the voice part and the non-voice Some methods, including but not limited to the following methods and their combinations o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More